
文章圖片
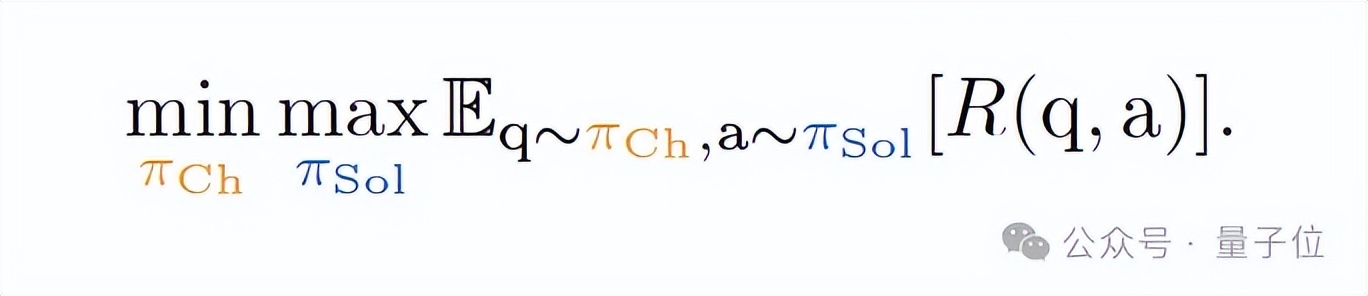
文章圖片

文章圖片
文章圖片
文章圖片
henry 發自 凹非寺
量子位 | 公眾號 QbitAI
Meta超級智能實驗室(MSL)又被送上爭議的風口浪尖了 。
不過 , 這次不是人事風波 , 而是他們的第二篇論文《Language Self-Play For Data-Free Training》被質疑忽視前人研究、缺乏創新 。
究竟是啥論文?
讓模型在博弈中學習總的來說 , MSL這篇新論文的核心思想是通過一種Language Self-Play(LSP)的方法 , 讓大型語言模型在沒有額外訓練數據的情況下實現自我提升 。
這一方法旨在應對當前大語言模型高度依賴大規模、高質量訓練數據 , 且訓練數據有限所帶來的困境 。
為此 , LSP將模型的學習過程設計成一個博弈框架 , 讓同一個語言模型扮演兩個角色進行對抗 , 從而實現無數據訓練 。
具體來說 , 這兩個角色分別是:
挑戰者:負責生成越來越有挑戰性的問題或指令 。 解決者:負責回答或執行這些指令 。在對抗過程中 , 挑戰者不斷生成越來越刁鉆的問題或指令 , 以降低解決者的預期回報;而解決者則必須努力理解并回答這些指令 , 以最大化自身回報——這其實就是我們熟悉的極小極大博弈(minimax game) 。
通過這樣的對抗訓練 , 模型能夠在不斷博弈中持續改進 , 逐步提升能力 。
此外 , 與傳統對抗訓練不同 , LSP讓單個語言模型同時扮演“挑戰者”和“解決者”兩個角色 , 研究人員給模型設計了一個特殊的“挑戰者提示”(Challenger Prompt):當接收到該提示時 , 模型進入挑戰者模式 , 生成難題;否則 , 它就扮演解決者角色 , 回答問題 。
這種單一模型的設計避免了訓練獨立對抗模型所帶來的額外開銷和不穩定性 。 整個過程完全自主 , 模型在自我對抗中不斷迭代 , 從而在沒有外部數據輸入的情況下提升自身能力 。
為了將這個博弈轉化成模型強化學習的過程 , 研究中采用了GRPO技巧 , 讓模型在每輪訓練中進行如下操作:
挑戰者生成問題:每輪生成N個問題 。 解決者回答問題:對于每個問題 , 解決者生成一定數量的答案 , 并分別計算獎勵 。 計算組價值與優勢:把解決者對同一個問題的所有答案的獎勵進行平均 , 得到這個問題整體的難度或表現水平 。 然后用每個答案的實際獎勵減去組價值 , 判斷這個答案比平均水平高還是低 。- 更新挑戰者優勢:通過計算優勢函數獲得問題和答案的反饋 , 優化自己出題的策略 。
通過這種獎勵機制 , 挑戰者生成的問題會針對解決者的薄弱環節 , 從而推動模型不斷改進 。
研究將這一方法稱為Language Self-Play Zero(LSP-Zero) , 其中 Zero 表示零和 。
此外 , 在實踐中 , 研究者發現LSP-Zero有時會退化 , 例如模型為了獲取獎勵而生成無意義但能獲得高分的內容(即獎勵 hacking) 。
針對解決這個問題 , 他們在LSP算法中引入了“自我質量獎勵” (RQ) , 引導博弈朝高質量交互發展 , 使訓練可長期進行 。
(注:LSP的具體算法如下表)
最后 , 為了驗證LSP算法的有效性 , 研究者使用Llama-3.2-3B-Instruct模型在Alpaca Eval基準上進行了兩組實驗 。
實驗一將算法與基礎模型本身以及一個通過傳統強化學習微調的大語言模型進行比較 。
實驗結果顯示 , 沒有使用任何數據的LSP和LSP-Zero和使用了數據的GRPO相當 , 并且顯著優于原始模型 。 而在 Vicuna這類對話型和開放式指令的數據集上 , LSP 的表現遠超GRPO 。
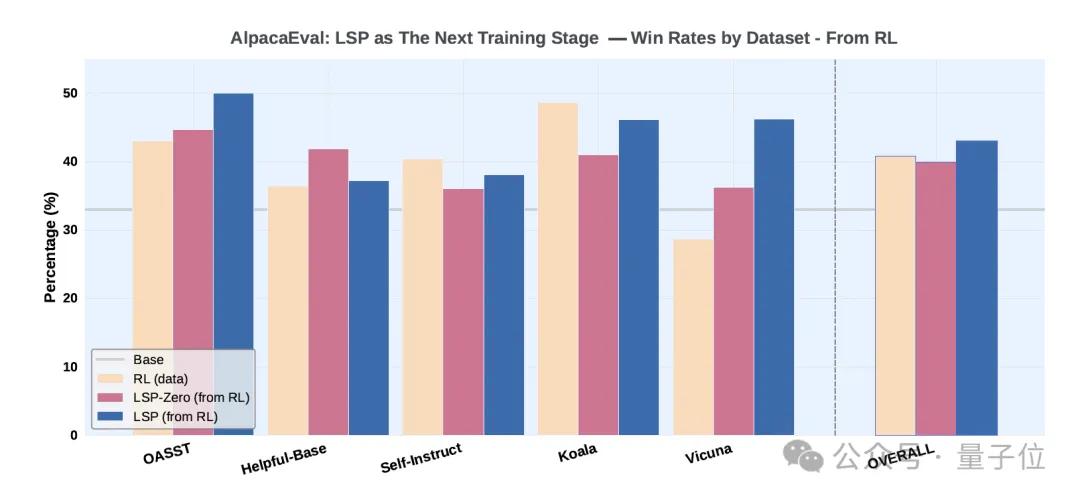
實驗二以實驗一中通過數據驅動 RL(GRPO)訓練得到的模型為起點 , 進一步使用 LSP-Zero 和 LSP 進行訓練 , 計算這些模型相對于Llama-3.2-3B-Instruct的勝率 , 并與初始的 RL 模型進行對比 。
實驗顯示 , 經過LSP的進一步訓練后 , 模型的整體勝率從40.9%顯著提升到了43.1% 。
同樣的 , LSP在Vicuna數據集上的提升尤為明顯 。 這表明 LSP 可以作為一種有效的方法 , 在數據驅動的訓練之后繼續挖掘模型潛力 。
總的來說 , 實驗結果表明 , LSP-Zero和LSP算法能夠在無需訓練數據的情況下提升預訓練LLM的性能 , 尤其是在對話類任務上表現顯著 , 而這可能意味著AI正在從依賴人類數據過渡到自主學習系統 。
網友:感覺忽略了大量前人研究?雖然(……)但是 , LSP一經發布后 , 在網友們這倒是出了些小插曲 。
一位推特網友直言:LSP自稱是突破性工作 , 但實際上忽視了大量前人研究 , 還順帶翻了一些舊賬 。
抱歉了 , Meta“超級智能”實驗室 , 但 @_AndrewZhao 等人的工作做得更好 , 而你們卻沒有引用 。 其實很多人都做過類似研究(比如 @Benjamin_eecs) , 無論是聯合最大化還是極小極大 , 不管是驗證器還是獎勵模型 。 為什么要把這說成是突破呢?你們在Vicuna上的評測確實做得不錯 , 簡直是2023年LLaMA社區的典型操作 。
而且 , 就連失敗的模型也大同小異 。
評論區有網友表示這可能是一篇老工作 , 然后拿到MSL發的:
(注:網友提及的論文如下:[1
Absolute Zero: Reinforced Self-play Reasoning with Zero Data[2
SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning[3
Scalable Reinforcement Post-Training Beyond Static Human Prompts)
截至目前 , MSL及論文作者尚未對此作出回應 。
參考鏈接
[1
https://x.com/teortaxesTex/status/1965654111069876296
[2
https://x.com/_akhaliq/status/1965601392187638018
[3
https://x.com/tydsh/status/1965856666580361705
[4
https://arxiv.org/pdf/2404.10642
[5
https://arxiv.org/pdf/2411.00062
[6
https://arxiv.org/pdf/2505.03335
— 完 —
量子位 QbitAI · 頭條號簽約
【Meta超級智能實驗室新論文陷爭議!被指忽略大量前人研究】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀














- 華為解碼制造業升級密碼,書寫“更懂制造”的智能化答卷
- 產銷旺出海忙 中國智能眼鏡產業“加速跑”
- 支付寶推出國內首個智能體支付服務“AI付”,瑞幸率先上線
- DeepSeek新大招曝光:下一步智能體
- 高通夏權2025服貿會發聲:以“人工智能+”驅動產業生態重構
- AI+行動號角吹響,聯想智能體憑什么領跑?
- 全球AI硬件提供商TOP10
- 創智復旦字節發布AgentGym-RL,昇騰加持,開創智能體訓練新范式
- 支付寶推出全國第一個智能體支付服務“AI付”
- 圖靈獎得主理查德·薩頓2025外灘大會演講:經驗是一切智能的核心與基礎