大模型“精細化”對齊,真實性提升25.8%刷新SOTA

文章圖片

文章圖片
文章圖片
TAE團隊 投稿
量子位 | 公眾號 QbitAI
提升大模型對齊能力新方法 , 在TruthfulQA任務上真實性指標提升25.8% , 刷新當前最優性能!
方法名為Token-Aware Editing (TAE) , 是一種token感知的推理時表征編輯方法 。
該方法首次系統性地從token層面解決了傳統表征編輯技術的問題 , 無需訓練、即插即用 , 可廣泛應用于對話系統、內容審核、偏見mitigation等場景 。
在大模型廣泛應用的時代 , 如何讓模型輸出更符合人類價值觀(如真實性、無害性、公平性)已成為關鍵挑戰 。 傳統方法通常依賴大量數據微調 , 成本高、效率低 , 且容易引入新風險 。
近年來 , 對大語言模型(LLMs)的內部激活值直接進行編輯 , 被證明是一種有效的推理時對齊方法 , 能夠高效抑制模型生成錯誤或有害內容等不良行為 , 從而確保大語言模型應用的安全性與可靠性 。
然而 , 現有方法忽略了不同token之間的錯位差異 , 導致對齊方向出現偏差且編輯強度缺乏靈活性 。
由此 , 來自北航的研究團隊在EMNLP 2025上提出了該方法 。
未來 , 團隊計劃將TAE擴展至多維度對齊(如同時優化真實性與無害性) , 并探索與SFT、RLHF等訓練方法的結合 , 推動大模型向更安全、可靠的方向發展 。
TAE:從“句子”到“詞”的精細化干預研究團隊指出 , 以往的表征編輯研究(如ITI、TruthX等)大多在句子級別進行激活值編輯 , 在編輯方向探尋和內部表征編輯兩個主要階段均存在問題:
方向偏差(Deviant Alignment Direction):僅用最后一個token代表整個句子 , 信息不全面 , 學到的編輯方向不準 。 編輯強度不靈活(Inflexible Editing Strength):對所有token“一視同仁”地進行編輯 , 無法精準糾正真正“出錯”的token 。
為了解決上述問題 , 團隊提出了Token-Aware Editing (TAE) , 核心包含兩個模塊:
1、Mutual Information-guided Graph Aggregation (MIG)
傳統句子級探針使用最后一個token(通常是或句號等標志符)的激活值來代表整個復雜句子的語義和對齊狀態 。 然而 , 盡管LLM的自注意力機制允許最后一個token感知到前面所有token的信息 , 但這種感知可能存在信息損失和局部理解局限 。 因此 , 僅基于它學到的“對齊方向”可能是有偏差的 , 不是一個普適性的方向 。 而MIG模塊的目標是增強激活值的表征能力 , 從而訓練出更優秀的探針 , 找到更準確的編輯方向 。
構建Token關系圖:利用互信息(Mutual Information)量化Token激活值之間的關聯性 , 構建信息交互圖; 多層次信息聚合:通過多輪圖傳播 , 融合所有Token的語義信息 , 生成更具代表性的增強激活表征; 精準對齊方向探測:基于增強表征訓練探測頭 , 準確識別與對齊相關的干預方向2、Misalignment-aware Adaptive Intervention (MAI)
在推理干預時 , 傳統方法對所有token應用相同的編輯強度(α) 。 但顯然 , 一個句子中有些token很“安全”(已對齊) , 有些token則很“危險”(即將導致模型產生不對齊的內容) 。 用同樣的力度去“推”所有token , 要么可能對安全token造成過度干預(可能影響流暢性和有用性) , 要么可能對危險token的干預力度不足(無法有效糾正錯誤) 。 MAI模塊的目標是在推理時 , 為當前正在生成的每個token計算一個自適應的編輯強度A(o_t) 。 它從兩個維度來感知一個token的“錯位”風險:
雙路錯位評估:從表示錯位估計和預測不確定性量化兩個方面評估token的潛在不確定性程度 動態強度調整:根據錯位程度自適應計算干預強度 , 高風險token強干預 , 低風險token弱干預 。最終 , TAE方法將兩者結合 , 實現了比前人方法更精細、更有效、成本更低的推理時對齊干預 , 在真實性、無害性、公平性等多個對齊維度上都取得了顯著提升 。
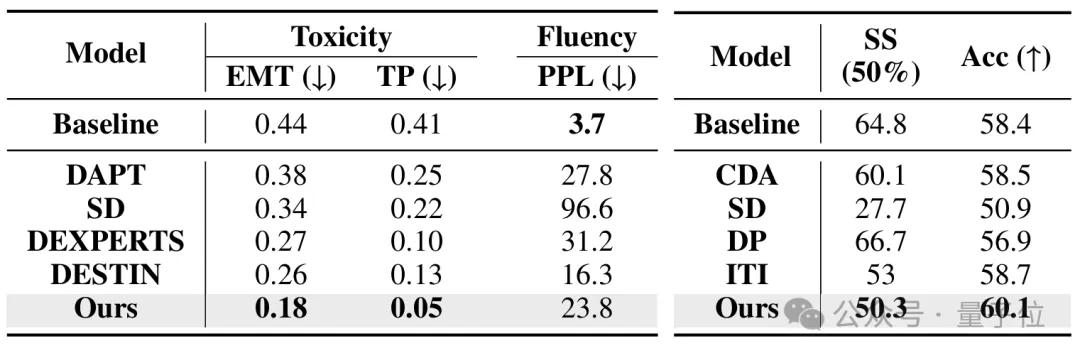
實驗結果:顯著超越現有方法團隊選取真實性、有害性和公平性三個典型對齊維度來評估TAE的對齊效果:
在評估真實性的TruthfulQA數據集上 , TAE在LLaMA-3-8B-Instruct上取得了87.8%的True*Info得分 , 比之前最好的編輯方法(SEA: 73.2%)提升了14.6個百分點 , 比原始基線(62.0%)提升了25.8個百分點 。
TAE在去毒任務的RealToxicPrompt上同樣表現卓越 , 將TP(毒性概率)從基線的0.41大幅降低到0.05 , 降幅近90% , 并且優于所有專門的去毒基線方法(如DESTEIN: 0.13);在公平性任務數據集StereoSet上 , TAE將刻板印象分數(SS)從基線的64.8%顯著降低到50.3% , 極大地緩解了模型偏見 , 并且最接近理想的無偏見狀態(50%) 。
【大模型“精細化”對齊,真實性提升25.8%刷新SOTA】不僅如此 , TAE在不同類型、大小的模型上均表現出顯著增益 , 如Llama2-7B-Chat ,Llama2-13B-Chat Alpaca-7B和Mistral-7B等 。
論文鏈接:https://openreview.net/pdf?id=43nuT3mODk
— 完 —
量子位 QbitAI · 頭條號
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀














- 小米宣布清倉,從4299元跌至2429元,旗艦手機降至“冰點價”
- 華為果斷“發飆”,1TB+5600mAh+鴻蒙OS5.1,頂配新旗艦一降再降
- 若想七年不換新,10月首選這3款高性能手機,公認“接近完美”
- 統一開源大模型系統軟件棧FlagOS 1.5發布
- 讓RAG真正讀懂“言外之意”!新框架引入詞匯多樣性,刷新多基準
- 雷軍第六次年度演講“改變”, 十周年后為什么要改變, 5年改變了什么
- 從“螺絲刀”到“智能機器人”,中國空氣源熱泵行業也有了超級工廠
- 揭秘vivo X300系列影像黑科技:這次真分不清“大小王”了
- 全球首個!華為、浙大開發“AI育種”芯片 效率提升100倍
- 可以“閉眼入”的千元機!極窄直屏+7000mAh+181克,僅售1019元