
文章圖片

文章圖片
文章圖片

文章圖片
機器之心報道
編輯:+0
還記得 DeepMind 的 Genie 3 世界模型嗎?它首次讓世界模型真實地模擬了真實世界 。
最近 , X 博主 anandmaj 在一個月內復刻 Genie 3 的核心思想 , 開發出了 TinyWorlds , 一個僅 300 萬參數的世界模型 , 能夠實時生成可玩的像素風格環境 , 包括 Pong、Sonic、Zelda 和 Doom 。
帖子附帶演示視頻 , 展示了模型通過用戶輸入實時生成視頻幀的過程 。
博主還分享了從架構設計到訓練細節的完整經驗 , 并開源了代碼倉庫 。
代碼:https://github.com/AlmondGod/tinyworlds理解世界模型
世界模型是一類神經網絡 , 它們通過生成視頻來模擬物理世界 。
DeepMind 在 Genie 3 上展示了這一理念的潛力:當世界模型在大規模視頻數據上訓練時 , 會出現類似 LLM 中的「涌現能力」 。 例如:
可控性:按下方向鍵 , 鏡頭會隨之平移 。 一致性:離開房間再返回 , 墻上的新油漆依舊存在 。 質量:水坑中的倒影清晰可見 。在 Genie 出現之前 , 研究者普遍認為要擴展世界模型 , 必須依賴帶動作標注或包含三維結構的數據 。
然而 DeepMind 發現 , 只要足夠規模化地訓練原始視頻 , 這些高級行為便會自然涌現 , 就像語言模型會自然習得語法和句法一樣 。
挑戰在于:世界模型的訓練通常需要逐幀的動作標簽(例如「按下右鍵 → 鏡頭右移」) 。 這意味著我們無法直接利用互聯網中龐大的未標注視頻 。
Genie 1 給出的解決方案是先訓練一個動作分詞器 , 自動推斷幀間的動作標簽 。 這樣一來 , 就可以把海量未標注視頻轉化為可用的訓練資源 。
這也是 Genie 3 能夠擴展至數百萬小時 YouTube 視頻 , 并解鎖上述涌現能力的關鍵所在 。
【爆肝一個月,復刻DeepMind世界模型,300萬參數玩實時交互像素游戲】受此啟發 , anandmaj 從零實現了一個最小化版本的世界模型:TinyWorlds 。
構建數據集
在開始訓練 TinyWorlds 前 , 作者首先要決定模型能夠生成怎樣的游戲世界 。 模型訓練時接觸的環境 , 決定了它未來的生成范圍 。
因此 , TinyWorlds 的數據集由處理過的 YouTube 游戲視頻構成 , 包括:
Pong:經典的雅達利雙人游戲 Sonic:二維橫版動作平臺 Zelda:鳥瞰式冒險 Pole Position:3D 像素賽車 Doom:3D 第一人稱射擊
構建時空變換器
與只需處理一維文本的大語言模型不同 , 視頻理解需要處理三維數據(高度 × 寬度 × 時間) 。 TinyWorlds 的核心是一個時空變換器(Space-time Transformer) , 它通過三層機制來捕捉視頻信息:
空間注意力:同一幀內部的 token 相互關聯 。 時間注意力:token 關注前幾個時間步的信息 。 前饋網絡:token 經過非線性處理以提取更高層次特征 。
動作如何影響視頻生成?作者嘗試了兩種方式:拼接動作與視頻表示 , 或利用動作對表示進行縮放與移位 。 實驗表明后者效果更好 , 最終被采納 。
同時 , TinyWorlds 也借鑒了大語言模型的優化技巧:SwiGLU 加速學習 , RMSNorm 提升穩定性 , 位置編碼則用于指示 token 在圖像中的位置 。
架構設計與分詞策略
在生成方式上 , 作者比較了擴散模型與自回歸模型 。
TinyWorlds 最終選擇自回歸 , 因為它推理更快 , 適合實時交互 , 訓練也更高效 , 且實現更簡潔 。
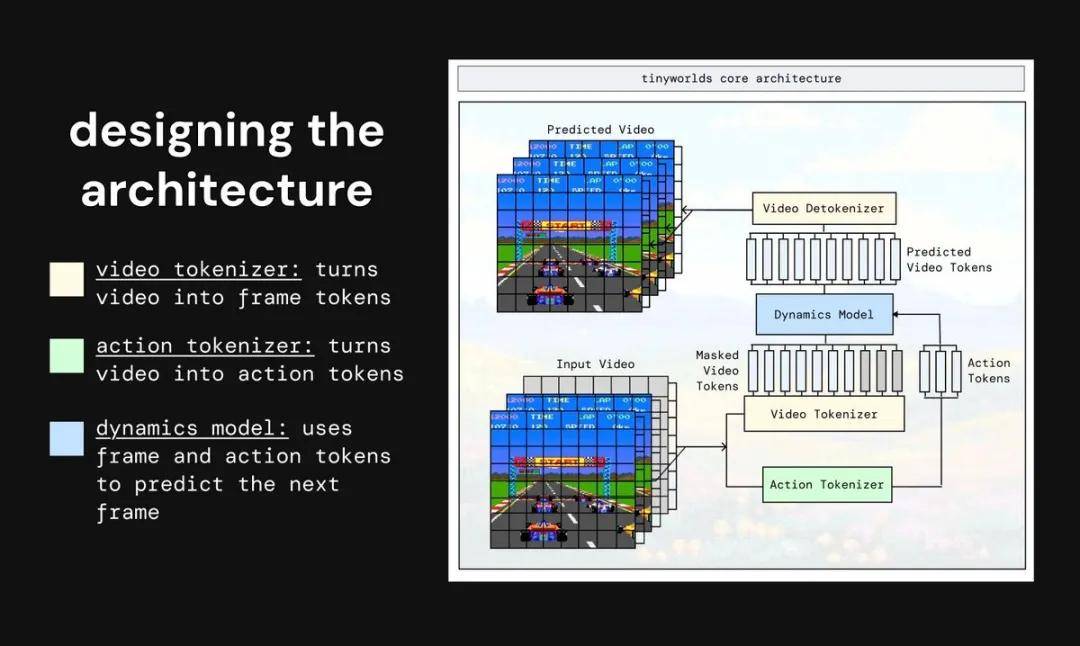
最終架構由三個模塊組成:
視頻分詞器:將視頻壓縮為 token 。 動作分詞器:預測兩幀之間的動作 。 動力學模型:結合歷史視頻和動作 , 預測未來幀 。
視頻分詞器通過有限標量量化(FSQ) , 將圖像劃分為立方體 , 并用這些立方體表示圖像塊 。 這樣產生的小 token 信息密集 , 減輕了動力學模型的預測負擔 。
動作分詞器的任務是從原始視頻中自動生成幀間動作標簽 , 使模型可以在未標注數據上訓練 。
在訓練初期 , 它容易忽略動作信號 。 為解決這一問題 , 作者引入了掩碼?。 ㄆ仁鼓P鴕覽刀鰨┖頭講釧鶚Вü睦嗦肫鞲哺歉囁贍芐裕?。
在小規模實驗中 , 動作 token 尚未完全映射到具體操作(如「左」「右」) , 但通過擴大模型或引入少量監督標簽 , 這一問題有望改善 。
訓練世界生成器
動力學模型是整個系統的「大腦」 , 負責結合視頻與動作預測未來幀 。 訓練中它通過預測掩碼 token 學習時序關系 , 推理時則根據用戶輸入動作生成下一幀 。 最初由于模型過小 , 性能停滯且輸出模糊;擴大規模后效果顯著提升 。
盡管 TinyWorlds 只有 300 萬參數 , 它依然能夠生成可交互的像素風格世界:
駕駛《Pole Position》中的賽車 在《Zelda》的地圖上探索 進入《Doom》的 3D 地牢雖然生成的畫面仍顯模糊、不連貫 , 但已經具備可玩性 。
作者認為 , 若擴展至千億級參數并引入擴散方法 , 生成質量會有巨大提升 。 這正是「苦澀的教訓」的再一次印證:規模與數據往往勝過技巧 。
參考鏈接:
https://x.com/Almondgodd/status/1971314283184259336
推薦閱讀












- 沉寂一個月,openPangu性能飆升8%!華為1B開源模型來了
- 深圳全球首創1.2萬架無人機燈光秀表演 復刻微信啟動畫面
- 還有山寨機?iPhone17Pro遭提前復刻,估計還不如紅米百元機好用
- DDR4價格飆升,一個月漲了一倍
- 6小時復刻AI IMO金牌成果,螞蟻多智能體新進展已開源
- 思必馳聲音復刻算法通過備案,精準賦能個性化語音服務
- 剛剛,字節掏出AI同傳模型王炸,2秒延遲,0樣本復刻你的聲音
- 華為新機發布一個月后,好評率跌至91%,降價太快是主因!
- 華為果斷放棄“高利潤”,麒麟9020新機上市僅一個月,跌價1050元
- 雙筒、三筒洗衣機爆賣:占比已達10% 一個月翻2倍