文章圖片
在人工智能領域 , 模型微調已成為提升模型性能、使其適應特定任務的關鍵技術 。 本文將全面系統地介紹模型微調的各個方面 , 幫助讀者深入理解這一重要技術 。
一、什么是模型微調模型微調是指在已經訓練好的預訓練模型基礎上 , 進行進一步的調整和優化 , 以使模型的輸出更加符合特定的應用需求 。 從本質上講 , 微調也是模型訓練的一種形式 , 其過程與訓練一個全新的模型有諸多相似之處 。
誰來做微調微調工作通常需要由具備豐富經驗的研發人員或算法工程師來承擔 。 這一過程不僅需要扎實的技術功底 , 還離不開兩個核心要素:代碼實現能力和充足的算力支持 。 值得一提的是 , 雖然目前有一些平臺提供了可視化界面來輔助微調 , 但這些界面的功能往往較為有限 , 只能起到一定的輔助作用 。
什么樣的模型可以微調并非所有模型都適合進行微調 , 以下兩類模型是比較常見的微調對象:
- 大部分開源模型 , 例如 LLaMA、qwen、glm 等 。 這些模型具有開放的架構和參數 , 為用戶進行個性化調整提供了便利 。
- API 中開放微調接口的閉源模型或平臺 , 如文心、智譜 AI 等 。 不過 , 開源模型和閉源模型在微調時存在明顯差異:開源模型經過微調后可以生成新的模型;而閉源模型的微調過程則是在平臺的服務器上進行 , 用戶無法直接獲取模型的原始參數 。
影響微調的核心因素微調的效果受到多個因素的綜合影響 , 其中最為核心的包括:
- 基座模型的選擇:基座模型的性能和特性在很大程度上決定了微調的上限 。
- 微調方式的選擇:不同的微調方法適用于不同的場景和需求 。
- 數據質量:高質量的數據是確保微調成功的關鍵基礎 。
二、模型微調工作流程第一步:需求分析與目標設定這一階段主要由項目組或產品經理主導 , 是微調工作的起點和關鍵 。
什么情況下需要微調
在實際應用中 , 以下幾種情況通常需要考慮對模型進行微調:
- 項目性質要求:例如甲方明確提出需求、出于資本化考慮或為了完成政績工程等 。 此外 , 微調也是快速獲得符合特定領域需求的大模型的常見手段 , 如礦山大模型、領域大模型等 。
- 溝通方式和語言風格有特殊要求:當基座模型通過 prompt 控制無法穩定實現特定的溝通方式或語言風格時 , 如 AI 兒童講故事場景 。
- 基座模型缺少垂直領域數據:在醫療、軍事等對專業知識要求較高的領域 , 由于互聯網公開數據可能無法滿足需求 , 導致基座模型無法完成專業任務 。
- 基座模型無法完成特定任務:例如需要模型實現自動化操作電腦、手機等功能 。
在決定進行微調之前 , 需要全面評估以下幾個方面:
- 是否已經充分嘗試了 prompt(包括 few-shot、cot 等方式)和 RAG 技術?
- 是否能夠保障微調所需的數據量級和數據質量?
- 由于基座模型會不斷推出新版本 , 其能力也會不斷提升 , 是否考慮過需要重新微調的情況?
1)明確業務需求和微調模型的目標:
- 仔細審視所選的基座模型在實際場景中的表現 , 判斷是否真的需要微調 。
- 檢查是否已經嘗試了各種 prompt 方法 。
- 考慮是否對任務進行了合理拆解 。
- 確認是否已經完善了 RAG 系統 。 需要注意的是 , 在大多數情況下 , 可能并不需要進行微調 。
3)設定預期的性能提升目標 。
4)明確特定的業務指標或限制條件 。
第二步:數據收集與準備數據收集與準備工作主要由產品經理主導 , 這是微調工作的基礎 。
數據收集
根據具體的需求 , 從企業的數據庫、日志文件、用戶交互記錄等多種來源收集相關數據 。 需要強調的是 , 在真實場景中收集真實數據至關重要 , 這將直接影響到微調的效果 。
數據清洗
對收集到的數據進行清洗 , 去除其中的噪聲、錯誤和不一致性 , 確保數據的質量 。 高質量的數據是模型能夠有效學習的前提 。
數據標注
如果采用監督學習方法進行微調 , 則需要對數據進行標注 。 這一步可能需要雇傭外部團隊或利用內部資源來完成 。 準確的標注數據對于模型的訓練和性能提升具有重要意義 。
數據劃分
將數據集劃分為訓練集、驗證集和測試集 , 以便對模型的性能進行評估:
- 訓練集:占比 70-80% , 用于模型的實際訓練和學習 。
- 驗證集:占比 10-15% , 用于評估模型在訓練過程中的表現 , 以便及時做出調整 。
- 測試集:占比 10-15% , 在模型訓練完成后用于最終評估模型的性能 。
模型尺寸與微調數量級之間存在一定的大致關系 , 如下表所示:
數據質量標準
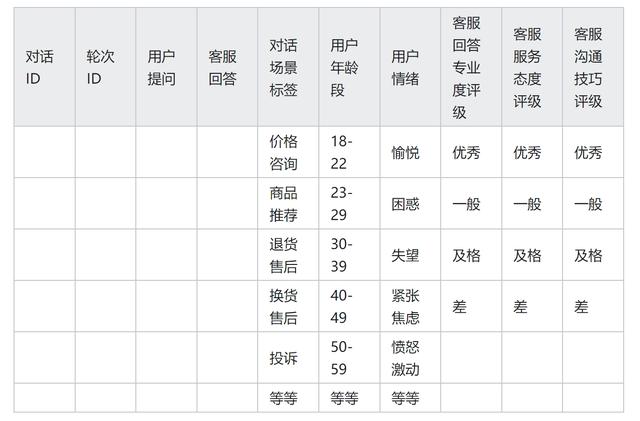
以智能客服系統的對話場景模型微調為例 , 數據質量標準可以包括以下多個維度:
第三步:模型選擇模型選擇通常由算法主導 , 產品經理也應積極參與 。
前提考慮
在選擇模型之前 , 同樣需要考慮以下幾個問題:
- 是否已經充分嘗試了 prompt(包括 few-shot、cot 等方式)和 RAG 技術?
- 是否能夠保障微調所需的數據量級和數據質量?
- 由于基座模型會不斷更新 , 是否考慮過需要重新微調的情況?
- 開源和閉源的選擇:原則上優先選擇開源模型 , 但最終決策需要根據具體的業務場景來確定 。
- 基座模型公司的選擇:例如智譜 AI 的 glm 系列模型 , 其中 glm4 的最強模型不開源 , 而阿里系的 qwen 模型是一個值得推薦的選擇 。
- 模型尺寸的選擇:需要從效果和成本兩個方面綜合考慮 , 在項目中 , 可能需要根據不同的場景選擇不同尺寸的模型 。 一般來說 , 可以先嘗試最大尺寸的模型以獲取最佳效果 , 然后再根據實際需求降到最小可行尺寸 。
在實際項目中 , 模型的選擇需要綜合考慮效果和成本 。 一個項目可能包含多個場景 , 因此可能需要選擇不同的模型 。 通常需要通過實驗和經驗來確定最佳的模型選擇和微調方式 , 例如:
- 對于一些復雜任務 , 可能需要采用 33b + 的模型進行全量微調 。
- 而對于另一些任務 , 可能采用 110 + 的模型并凍結部分參數進行微調更為合適 。
第四步:模型微調模型微調由算法工程師實施 , 是整個工作流程的核心環節 。
模型微調方式(本質上是 SFT)
1)全模型微調:對整個模型的所有參數進行調整 。
2)輕量化微調(Parameter-Efficient Fine-tuning , PEFT):
- 低秩適應微調(Low-Rank Adaptation , LoRA):這是最常用的微調技術之一 。
- prompt tuning 。
- P-Tuning 。
- Prefix-Tuning 。
4)漸進微調:逐步調整模型的參數 , 以提高微調的效果和穩定性 。
5)多任務微調:同時對多個任務進行微調 , 以提高模型的泛化能力 。
LoRA 微調原理
LoRA 微調的核心原理是只選擇原始模型的部分參數作為目標微調參數(通常 r 取 4、8、16、32 等) , 不更改模型的原始參數 , 而是在原始參數的基礎上增加一個偏移量 , 從而得到一套新的參數 。 這種方法具有高效、節省算力等優點 , 因此在實際應用中最為常用 。
QLoRA 微調
QLoRA 微調的主要目的是解決顯存占用量過大的問題 。 顯存占用量的計算方法如下:參數量 ×4×4 倍(裝進來 + 轉起來)/(1024×1024×1024)=xG 顯存 。 以 7B 模型為例 , 其參數量為 7000000000 , 計算可得顯存占用約為 11200000000 字節 , 即約 104G , 這需要 5 張 NVIDIA 4090 顯卡(每張 24G) 。 QLoRA 通過將 4 個字節的浮點數改成 1 個字節的整數 , 直接將顯存占用降低到原來的四分之一 , 大大提高了模型微調的可行性 。
第五步:模型評估模型評估由產品經理主導 , 是確保模型滿足預期需求的關鍵環節 。
評估手段:支持率
在特定場景下評估微調后的模型能力 , 支持率是一個重要的指標 。 通用領域的評估往往沒有實際意義 。 具體評估方法如下:
1)設計問答任務 , 使用微調前和微調后的模型分別回答問題 , 然后由人工在不知道回答來源的情況下進行偏好選擇 。
2)評估標準:
- 如果微調后的模型支持率低于 50% , 說明這次微調不僅沒有提升模型能力 , 反而破壞了原有模型的能力 。
- 如果支持率在 50% 左右 , 說明微調幾乎沒有取得進步 。
- 如果支持率在 50%-70% 之間 , 微調的成果不夠理想 。
- 如果支持率在 70%-80% 之間 , 說明這次微調是成功的 。
- 如果支持率超過 80% , 表明在大多數場景下 , 這次微調都取得了顯著的提升 。
第六步:模型部署一旦模型通過評估 , 就可以由研發人員將其部署到生產環境中 , 使其能夠為實際業務提供服務 。
第七步:監控與維護模型部署到生產環境后 , 需要由產品經理負責進行監控與維護:
- 性能監控:定期檢查模型的性能 , 確保其持續滿足業務需求 。
- 更新與再訓練:隨著新數據的獲取或業務環境的變化 , 可能需要對模型進行再次訓練或微調 , 以適應新的情況 。
第八步:反饋循環產品經理需要設計反饋和監督機制 , 建立一個有效的反饋循環:收集模型使用過程中的反饋信息 , 用于指導未來的改進和優化工作 , 使模型能夠不斷進化和完善 。
三、數據工程需要明確的是 , 微調不是一次性工程 , 持續的數據收集和體系化的數據處理比微調技術本身更為重要 。
如何收集偏好數據(相當于人工標注)
- 點贊點踩:通過用戶對模型輸出的點贊或點踩行為來收集偏好數據 。
- 多選項選擇:例如一次性給用戶展示 4 張圖 , 讓用戶選擇偏好的選項;或者讓模型生成兩個答案 , 讓用戶進行選擇 。
- 客服工作臺輔助:在客服工作臺中 , 模型生成 4 個輔助回復 , 其中 2 個來自原模型 , 2 個來自微調后的模型 , 讓客服選擇一個最合適的回復 , 從而收集偏好數據 。
- 數據收集能力:在產品功能設計上 , 一定要具備數據收集能力 , 以便及時獲取用戶反饋和偏好數據 。
- 定向數據收集:針對特定場景 , 在產品功能上設計定向數據收集的機制 , 提高數據的針對性和有效性 。
- 利用 LLM 能力:讓數據管理平臺具備一定的智能 , 提高數據管理的效率和質量 。
- 參考案例:如百度智能云的數據管理和數據標注平臺 。
- 數據來源管理:管理自有數據、公開數據、用戶生成數據、專家撰寫的數據、模型合成數據、眾包收集數據等多種數據來源 , 并實現在線系統數據的直接導入和數據平臺與在線系統的實時對接 。
- 體系化標注:包括標簽定義、標簽層次構建、打標任務管理和打標任務分層等 , 支持用戶打標、服務人員打標、專家打標、AI 打標、交叉打標、交叉復檢和專家抽檢等多種標注方式 。
- 數據去重與增強:通過 prompt 的相似度計算、數據來源整體質量分級等方法進行數據去重 , 同時采用同義詞替換、詞序打亂、反向翻譯、數據混合等技術進行數據增強 。 例如 , 將 200 條問答數據通過模型生成相同的提問 , 可擴展為 400 條數據;將數據翻譯成其他語言再翻譯回原語言 , 可實現表達方法的多樣性 。
- 數據打包:實現訓練集、驗證集和測試集的自動化劃分 , 建立數據集與模型版本、模型評估結果的關聯 , 并按標簽評估數據的可用性和復用性 。
- 模型評估:支持偏好打標、專家打分、用戶偏好收集等評估方式 , 并按標簽產出評估結果 , 實現評估與打標數據的復用 。
- 多利用能力強大的模型輔助工作:例如利用強大的模型進行數據過濾、自動打標、交叉復檢、prompt 的相似度計算、response 質量對比、數據增強和模型評估等工作 , 提高數據工程的效率和質量 。
四、后記原則
- 如果沒有高質量的數據 , 微調實操的意義不大 。 數據質量是決定微調效果的關鍵因素 , 即使采用最先進的微調技術 , 若沒有高質量的數據支撐 , 也難以取得理想的效果 。
- 不強調數據量的大小 , 但是數據質量一定要高 。 在數據工程中 , 應更加注重數據的質量而非數量 , 高質量的數據能夠使模型更加有效地學習到所需的知識和模式 。
本文由 @李雨田 原創發布于人人都是產品經理 。 未經作者許可 , 禁止轉載 。
題圖來自Unsplash , 基于CC0協議 。
【模型微調:從理論到實踐的深度解析】該文觀點僅代表作者本人 , 人人都是產品經理平臺僅提供信息存儲空間服務 。
推薦閱讀












- 昇騰生態再升級,華為宣布開源盤古7B稠密和72B混合專家模型
- 大模型時代,通用視覺模型將何去何從?
- 庫克徹底清倉!A15芯片+6.1英寸XDR屏幕,從5999元跌至2699元
- 一加開啟清倉模式,從4399元跌至2798元,24GB+1TB+天工散熱
- 英特爾Day0完成文心大模型4.5系列開源模型的端側部署
- 百度文心大模型4.5系列正式開源,同步開放API服務
- 榮耀堅決清倉,驍龍8Gen3旗艦從4999元跌到2549,比紅米K80還香
- 華為果斷清倉,從3999元跌至2909元,512GB鴻蒙手機可“閉眼入”
- 從無語到還行,用了兩天小米AI眼鏡,我的看法發生了一些改變
- 蘋果AI戰略困局:從自主研發到急尋外援,Siri升級之路一波三折