大模型時代,通用視覺模型將何去何從?

文章圖片
文章圖片
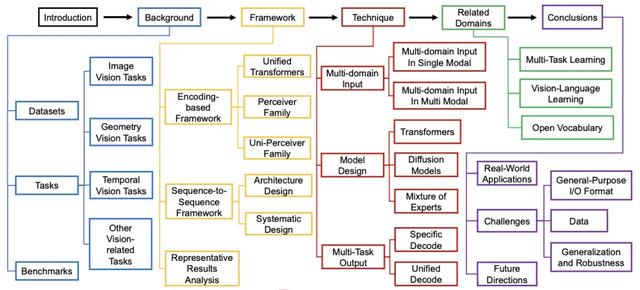
過去幾年 , 通用視覺模型(Vision Generalist Model , 簡稱 VGM)曾是計算機視覺領域的研究熱點 。 它們試圖構建統一的架構 , 能夠處理圖像、點云、視頻等多種視覺模態輸入 , 以及分類、檢測、分割等多樣的下游任務 , 向著「視覺模型大一統」的目標邁進 。
然而 , 隨著大語言模型 LLM 的迅猛發展 , 研究熱點已經悄然發生轉移 。 如今 , 多模態大模型興起 , 視覺被看作是語言模型眾多輸入模態中的一種 , 視覺模態數據被離散化為 Token , 與文本一起被統一建模 , 視覺的「獨立性」正在被重新定義 。
在這種趨勢下 , 傳統意義上以視覺任務為核心、以視覺范式為驅動的通用視覺模型研究 , 似乎正在逐漸被邊緣化 。 然而 , 我們認為視覺領域仍應保有自己的特色和研究重點 。 與語言數據相比 , 視覺數據具有結構化強、空間信息豐富等天然優勢 , 但也存在視覺模態間差異大、難替代的挑戰 。 例如:如何統一處理 2D 圖像、3D 點云和視頻流等異質輸入?如何設計統一的輸出表示來同時支持像素級分割和目標檢測等不同任務?這些問題在當前的多模態范式中并未被充分解決 。
正因如此 , 在這個多模態模型席卷科研與工業的新時代 , 回顧并總結純視覺范式下的通用視覺模型研究仍然是一件十分有意義的事情 。 清華大學自動化系魯繼文團隊最近發表于 IJCV 的綜述論文系統梳理了該方向的研究進展 , 涵蓋輸入統一方法、任務通用策略、模型框架設計、模型評測應用等內容 , 希望能為未來視覺模型的發展提供參考與啟發 。
【大模型時代,通用視覺模型將何去何從?】
- 論文標題:Vision Generalist Model: A Survey
- 論文鏈接:https://arxiv.org/abs/2506.09954
VGM 到底解決了什么問題?
通用視覺模型是一種能夠處理多種視覺任務和模態輸入的模型框架 。 類似于大語言模型在自然語言處理中的成功 , VGM 旨在通過構建一個統一的架構來解決各種計算機視覺任務 。 傳統的視覺模型通常針對特定任務(如圖像分類、目標檢測、語義分割等)設計 , 而 VGM 通過廣泛的預訓練和共享表示 , 能夠在不同的視覺任務之間實現零樣本(Zero-shot)遷移 , 從而無需為每個任務進行專門的調整 。
VGM 的關鍵能力之一是其多模態輸入的統一處理能力 。 不同于傳統模型只處理單一類型的視覺數據 , VGM 能夠同時處理來自多個模態的數據 , 如圖像、點云、視頻等 , 并通過統一的表示方法將它們映射到共享的特征空間 。
此外 , VGM 還具備強大的多任務學習能力 , 能夠在同一個模型中處理多個視覺任務 , 從圖像識別到視頻分析 , 所有任務都可以在一個通用框架下并行處理 。
綜述涵蓋了哪些核心內容?
數據 + 任務 + 評測:為通用建模打基礎
VGM 通常使用大規模、多樣化的數據集進行訓練和評估 。 為了支持多模態學習 , VGM 使用的訓練數據集涵蓋了圖像、視頻、點云等多種類型 , 本綜述列舉并介紹了一些常見的多模態數據集 。
任務方面 , 本綜述將視覺任務分為四類:圖像任務、幾何任務、時間序列任務以及其他視覺相關任務 。 評測方面 , 主要通過多個綜合基準來衡量其在多種任務和數據集上的表現 。 與傳統的單一任務評測不同 , 現代評測方法更注重模型的跨任務泛化和多模態處理能力 。 本綜述也對現有通用視覺模型的評測基準做了充分的調研與總結 。
模型設計范式與技術補充
現有通用視覺模型的設計范式主要集中在如何統一處理不同視覺模態輸入和多樣化任務輸出 , 大致可以分為兩種類型:編碼式框架和序列到序列框架 。
編碼式框架(Encoding-based Framework)旨在通過構建一個共享的特征空間來統一不同的輸入模態 , 并使用 Transformer 等模型進行編碼 。 這類框架通常包括領域特定的編碼器來處理不同類型的數據 , 如圖像、文本和音頻 , 然后通過共享的 Transformer 結構進行進一步處理 , 最終生成統一的輸出 。
而序列到序列框架(Sequence-to-Sequence Framework)則借鑒了自然語言處理中的序列建模方法 , 將輸入數據轉換為固定長度的表示 , 然后通過解碼器生成相應的輸出 。 這些框架特別適合處理具有可變長度輸入輸出的任務 , 如圖像生成和視頻分析 。
盡管有一些工作并不能被定義為通用視覺模型 , 但它們在聯合多模態數據輸入、模型架構設計、協同處理多任務輸出等方面做出了卓越的技術貢獻 。 本綜述也對這些技術進行了詳盡的討論分析 。 一些相關領域的內容 , 如多任務學習、視覺-語言學習、開放詞匯 , 也被用來擴充通用視覺模型領域的知識邊界 。
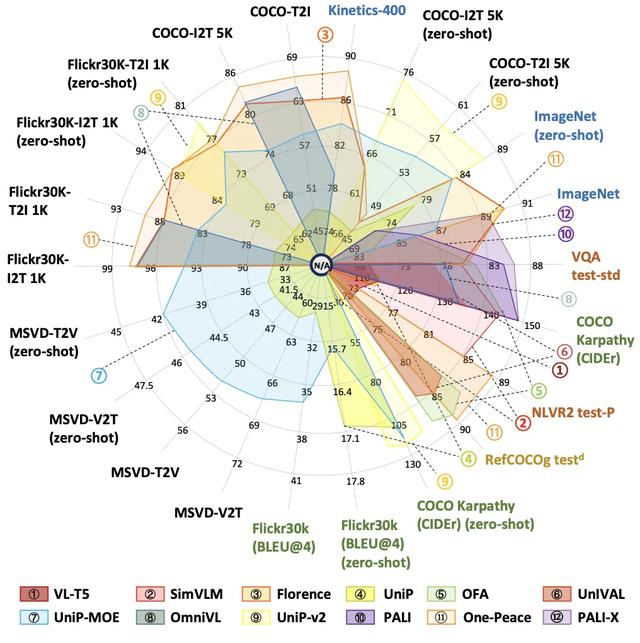
此外 , 作為一個 case study , 本綜述對比了收錄了多個主流 VGM 模型在 22 個基準數據集上的評測結果:
VGM 的未來在哪里?
最后 , 本綜述總結了 VGM 的當前研究進展和面臨的挑戰 , 還強調了其在實際應用中的潛力和未來發展方向 。
現有 VGM 在多個任務和多模態輸入的統一處理方面已經取得了顯著的進展 , 但仍面臨著如何優化統一框架設計、提高訓練效率和應對大規模數據等挑戰 。 數據獲取和標注仍然是 VGM 發展的瓶頸 。
為了解決這一問題 , 自動化標注技術以及大規模無監督學習方法的研究將成為未來的研究重點 。 然而 , 隨著模型規模的擴大 , VGM 也面臨著倫理問題和偏見的挑戰 。 大量未標注的數據中可能包含潛在的偏見 , 如何確保模型的公平性、透明性和安全性 , 仍是未來研究中的重要課題 。
盡管如此 , 現有的 VGM 在實際應用中展示了廣泛的潛力 。 它不僅可以用于傳統的視覺任務 , 如圖像分類、目標檢測和語義分割 , 還能擴展到更復雜的多模態任務 , 如視覺問答、圖像-文本檢索、視頻理解等 。 這些應用涵蓋了智能監控、自動駕駛、機器人等多個領域 , 推動了 VGM 在實際場景中的廣泛部署 。
希望這篇文章能給研究中的你一些啟發 。
推薦閱讀












- 英特爾Day0完成文心大模型4.5系列開源模型的端側部署
- 百度文心大模型4.5系列正式開源,同步開放API服務
- 淺析AI大模型未來發展的三大關鍵特性:主動性、項目性和互動性
- 企業大模型落地的現實解法:為什么RAG是繞不開的技術路徑?
- 大模型技術如何重構智能客服對話體驗
- 華為入選《時代周刊》全球100影響力企業:自主研發支撐品牌韌性
- AI大模型回答如何優化?AI-CRO了解一下
- CRO是什么意思
- 讓審批快起來!DeepSeek大模型賦能政務申辦受理平臺的實踐路徑
- 什么是AI-CRO/CRO?