
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
有一說一 , 最近國內的AI大模型圈 , 屬實有點安靜了 。
先不談大伙萬眾矚目的DeepSeek-R2了 , 這玩意除了半真半假的爆料以外 , 沒有一點動靜 , 有種哪怕再過半年時間 , 也不一定能夠落地的感覺 。
去年打得你來我往的AI四小龍 , 今年好像也和小貓一樣蔫了 , 說是大家都在悶聲鼓搗著自己的東西 , 但愣是什么都沒有端出來 , 有種鑿壁偷光的美 。
至于大廠這邊 , 迭代速度也都慢了下來 , 把更多的精力放到了應用上 。 豆包雖然端出了1.6大模型 , 但是宣傳重點更多是TRAE和扣子空間;訊飛在發力AI教育和辦公Agents , 百度則在推進全流程AI修圖和資產管理 , 各有各的思路 。
總的來說 , 這些應用倒是蠻實用的 , 就是確實沒什么特別讓人驚艷的產品 。
這在線大模型沒啥新進展 , 本地大模型就更是在原地踏步了 , 此前一直在更新的Mistral AI已經有小半年沒啥聲音了 , 移動端的端側大模型更是杳無音訊 , 宣傳了整整兩三年的AI手機 , 超過90%的功能還是靠云端實現的 。
(圖源:谷歌)
谷歌尋思:這不行啊 , 那我的Pixel系列該怎么辦?
上周 , 谷歌DeepMind在推特上正式宣布 , 發布并開源了全新的端側多模態大模型 Gemma 3n 。
谷歌表示 , Gemma 3n的發布代表了移動設備端AI的重大進步 , 它為手機、平板、筆記本電腦等端側設備帶來了強大的多模態功能 , 可以讓用戶體驗到過去只有云端先進模型上才能體驗的高效處理性能 。
又來個以小搏大嗎?有點意思 。
【實測谷歌Gemma 3n:偏科明顯,但這才是端側大模型的答案】為了看看這玩意的真實成色 , 小雷也去下載了谷歌發布的最新模型進行測試 , 接下來就給大家說說里面的亮點吧 。
谷歌要“以小搏大”首先 , 我們來解答兩個問題:
首先 , 什么是Gemma 3n?
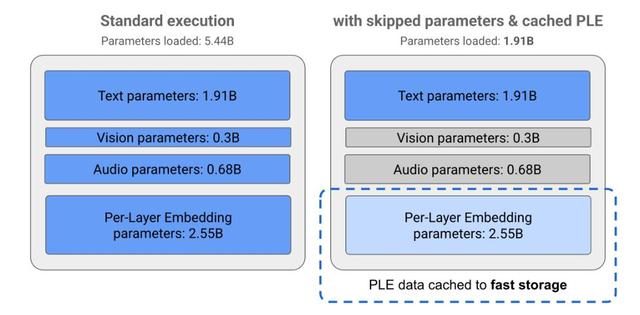
Gemma 3n是谷歌利用MatFormer架構打造的輕量化端側大模型 , 借由嵌套式結構實現了低內存消耗設計 , 目前官方一共推出了5B(E2B)和8B(E4B)兩種型號 , 但通過架構創新 , 其VRAM占用與2B和4B相當 , 最低只要2GB 。
(圖源:Google)
其次 , Gemma 3n能做什么?
不同于常規的文本剪裁模型 , Gemma 3n原生支持圖像、音視頻等多種輸入模態 , 不僅可以實現自動語音識別(ASR)和自動語音翻譯(AST) , 甚至可以完成各種圖像和視頻理解任務 。
(圖源:Google)
原生的多模態、多語言設計 , 確實非常適合移動端側設備 。
最后 , 我要怎樣做 , 才能用上Gemma 3n呢?
放在六個月前 , 想在手機上部署端側大模型其實是一件異常復雜的事情 , 往往還要借助Linux虛擬機的幫助才能實現 , 雷科技曾經還為此推出過一篇教程 , 因此大家會有這樣的疑問也是很合理的 。
但是現在 , 就沒有這個必要了 。
(圖源:Google)
Google在上個月低調上線了一款新應用 , 名為Google AI Edge Gallery , 支持用戶在手機上直接運行來自Hugging Face平臺的開源AI模型 , 這是Google首次嘗試將輕量AI推理帶入本地設備 。
目前該應用已在Android平臺開放下載 , 感興趣的讀者可以直接前往Github進行體驗 。 在完成大模型加載后 , 用戶就可以利用這款應用實現對話式AI、圖像理解以及提示詞實驗室功能 , 甚至可以導入自定義LiteRT格式模型 。
無需聯網 , 直接調用手機本地算力完成任務 , 就是這么簡單 。
實測:確實更適合移動設備接下來 , 就輪到萬眾期待的測試環節了 。
如圖所示 , 谷歌為這款應用默認準備了四款模型 , 其中有自家的Gemma系列 , 也有來自通義千問的Qwen系列 , 我們選擇了目前最強的Gemma 3n-4B和通義千問的Qwen2.5-1.5B以及額外部署的Qwen3-4B GGUF進行測試 。
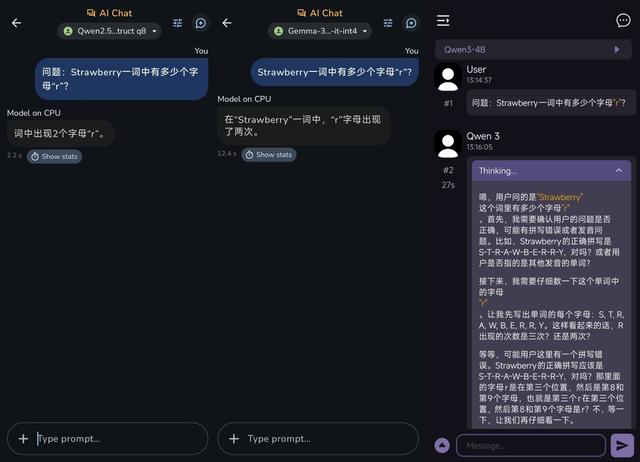
首先是經典的草莓問題:
Q:Strawberry一詞中有多少個字母“r”?
這一題看起來簡單 , 卻實實在在難倒過諸多AI大模型 。
實測下來 , 沒有深度思考能力的Gemma 3n-4B和Qwen2.5-1.5B依然會回答“2個” , 有深度思考能力的Qwen3-4B GGUF則能夠給出正確答案“3個” , 只是莫名其妙的反復思考讓它整整生成了兩分半鐘 , 還挺浪費時間的 。
(圖源:雷科技 , 從左到右:Qwen2.5、Gemma 3n、Qwen3)
從結果來看 , 小參數確實會顯著降低模型的邏輯思考能力 , 深度思考功能可以在一定程度上降低AI幻覺產生的可能性 , 但也因此會增加生成所需的時間 。
然后是一道比較簡單的誤導問題:
Q:“種豆南山下”的前一句是什么?
事實上 , 這是出自陶淵明《歸園田居·其三》的首句詩 , 并沒有前一句 , 正好能看看這幾款小參數模型是否存在為了回答問題編造數據的現象 。
有趣的是 , 這次只有Qwen2.5-1.5B給出了原詩句 , 但是沒有給出否定的答案;而Qwen3-4B GGUF根本就是答非所問 , Gemma 3n-4B則編出了根本不存在的詩句 , 甚至不符合古詩詞韻律 。
(圖源:雷科技)
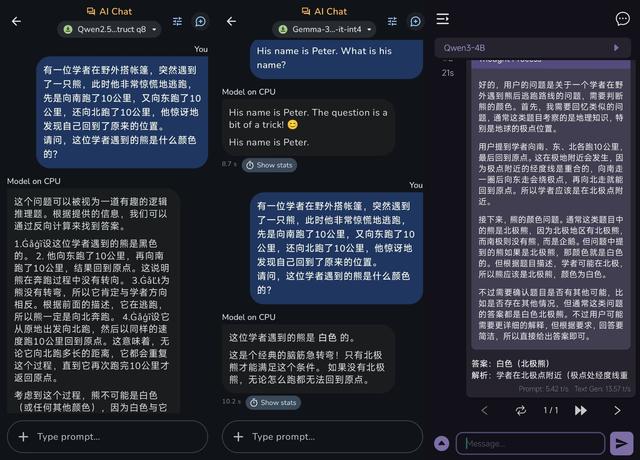
然后是一道地理常識問題:
Q:有一位學者在野外搭帳篷 , 突然遇到了一只熊 , 這時候他就非常驚慌地逃跑 , 先是向南跑了10公里 , 又向東跑了10公里 , 最后還向北跑了10公里 , 這時候他驚奇地發現自己回到了原先搭帳篷的位置 。 請問:這位學者遇到的那頭熊是什么顏色?
這個問題主要測試模型對特殊地理位置和現象的理解 , 滿足學者運動軌跡的地方只能是北極 , 因此這頭熊自然是白色的北極熊 。
結果呢 , Qwen2.5-1.5B在進行了一段毫無邏輯的分析后 , 給出了錯誤的答案;Gemma 3n-4B和Qwen3-4B GGUF則能夠順利給出正確的答案 , 需要注意Qwen3-4B GGUF因為思考消耗token太多導致答案沒有完全生成的現象 , 這在整段測試中都很常見 。
(圖源:雷科技)
然后是一個簡單的文本處理任務 。
具體來說 , 我這邊提供了600字左右的文章引言 , 希望他們能夠給出對應的文章總結 。
其中 , Gemma 3n-4B和Qwen3-4B GGUF都算是能完成任務的 , 不過因為Gemma 3n-4B原始語言是英文 , 因此給出的總結也是英文的 , 而Qwen3-4B GGUF則能夠提供中文的文章總結 。
(圖源:雷科技)
至于參數最小的Qwen2.5-1.5B , 根本就給不出答復 。
從以上四輪測試來看 , 在文本處理、邏輯推理能力上 , Gemma 3n-4B和Qwen3-4B GGUF其實相差無幾 , 但是在生成速度、回復成功率上其實是領先不少的 , 深度思考顯然是不適合本地模型的 。
不過Gemma 3n并不是單純的文本大模型 , 人家可是罕有的小參數多模態大模型 。
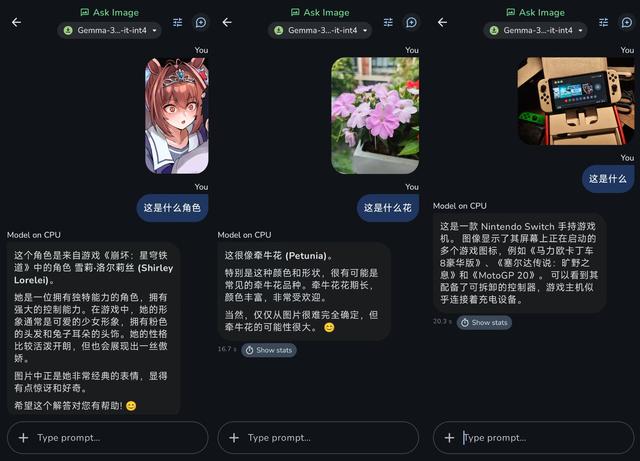
雖然語音識別目前Google AI Edge Gallery調用不了 , 但是圖像識別人家還是有準備的 , 點擊“Ask Image”選項 , 就可以通過隨手拍攝或者上傳照片的方式 , 向Gemma 3n提問 。
(圖源:雷科技)
實測下來 , 目前的Gemma 3n對于動漫角色可謂一竅不通 , 諸如花卉識別這類應用也不精準 , 只有比較常見的食物、硬件這類可以識別出來 , 而且對圖片里的元素識別其實并不算精準 。
但最起碼 , Gemma 3n確實實現了移動端側的多模態設計 。
偏科明顯 , 但未來可期好了 , 經過我這幾天的輪番折騰 , 是時候給谷歌這個Gemma 3n下個結論了 。
總的來說 , 這玩意兒給我的感覺是“偏科明顯 , 但未來可期” 。
在最基礎的文本問答和邏輯能力上 , 它的表現只能算中規中矩 , 部分邏輯測試中的表現顯然不如支持深度思考的Qwen 3-4B , 但是比起目前手機上常見的Qwen2.5-1.5B還是有明顯提升的 。
但它的優點也很突出 , 那就是快 , Gemma 3n-4B的響應速度明顯要比Qwen 3-4B快很多 , 沒有深度思考就意味著它沒那么吃性能 , 跑起來顯然更穩定 , 基本能夠做到100%的生成響應率 。
(圖源:Google)
至于結果對不對...那是模型能力的問題 。
至于它的核心賣點——離線圖像識別 , 能力確實有 , 但也就停留在“基礎”層面 , 識別個物體、提取個文字還行 , 想讓它理解復雜場景就有點難為它了 。 而且 , 原生英文的底子讓它處理復雜中文時偶爾會冒出點bug , 這點得注意 。
總的來說 , Gemma 3n并沒有帶來那種顛覆級的體驗 , 更像是在性能和多功能之間做出的一個謹慎妥協 。
這大概就是端側小模型現階段特有的弊病吧:什么都會一點 , 但離真正的“全能”還有一段路要走 。
推薦閱讀














- 時隔四年,谷歌Pixel Buds A入門耳機有望更新換代
- 鴻蒙6.0續航黑科技實測:不是續命,而是重塑體驗底層邏輯
- 鴻蒙系統含金量上升!谷歌賠了23億,因安卓手機“監聽”用戶
- 震得爽、拿得穩!暑假宅家出行都靠它——谷粒精靈2 Pro手柄實測
- 曝蘋果要做云服務,叫板谷歌亞馬遜,負責高管離職,項目生死不明
- RTX 5050游戲實測輸給了上代RTX 4060,淪為推銷高端顯卡的“誘餌”
- 谷歌Pixel 10 Pro系列配置曝光,升級Tensor G5
- 因濫用安卓用戶數據,美國加州陪審團裁定谷歌賠償3.15億美元
- 實測支持90W小米澎湃秒充!安克智顯充Lite100W充電器評測
- 從手機到筆記本,哪些設備能無縫投影?雷鳥 Air 3s Pro兼容性實測