
文章圖片
文章圖片
文章圖片
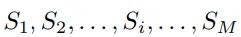
文章圖片
【長思維鏈里的推理步驟,哪些最關鍵?三招鎖定LLM的「命門句子」】
文章圖片
文章圖片
機器之心報道
編輯:張倩
思維鏈里的步驟很重要 , 但有些步驟比其他步驟更重要 , 尤其是在一些比較長的思維鏈中 。
找出這些步驟 , 我們就可以更深入地理解 LLM 的內部推理機制 , 從而提高模型的可解釋性、可調試性和安全性 。
但是 , 這些步驟沒有那么好找 , 因為每個生成的 token 都依賴于之前的所有 token , 其計算難以分解 。
在最近的一項研究中 , 來自杜克大學和 Aiphabet 的研究者提出 , 在句子層面分析推理痕跡或許是一種有前途的方法 。
- 論文標題:Thought Anchors: Which LLM Reasoning Steps Matter?
- 論文鏈接:https://arxiv.org/pdf/2506.19143
作者提出了三種互補的方法來分析 LLM 的推理過程 , 這些方法旨在識別推理過程中的關鍵步驟 , 即所謂的「思維錨(thought anchor)」 , 這些步驟對后續推理過程具有重大影響 。
第一種是黑盒方法 。 它通過反事實分析衡量句子對最終答案的影響 。 即通過比較模型在包含某個句子和不包含該句子時的最終答案分布 , 來評估該句子對最終答案的影響 。
第二種是白盒方法 。 它通過注意力模式識別關鍵句子 , 揭示關鍵句子如何影響推理軌跡的其余部分 。
第三種是因果歸因方法 。 它通過抑制注意力直接測量句子之間的因果關系 , 即抑制對特定句子的注意力如何影響后續每個句子的 logits 。
每種方法都為思維錨的存在提供了證據 。 這些推理步驟非常重要 , 對后續推理過程產生了不成比例的影響 。 這些思維錨通常是計劃句或回溯句 。
作者提供了一個開源工具 , 用于可視化方法的輸出 。
開源工具鏈接:http://thought-anchors.com/
這項研究也為更精確地調試推理失敗、識別不可靠性的來源以及開發提高推理模型可靠性的技術打開了大門 。
通過反事實測量句子影響
有些句子比其他句子更重要 , 但哪些句子最重要取決于我們如何定義和衡量重要性 。 作者將句子層面的重要性表述為一個反事實影響的問題:包含或排除一個句子會如何影響后續步驟以及模型的最終輸出?
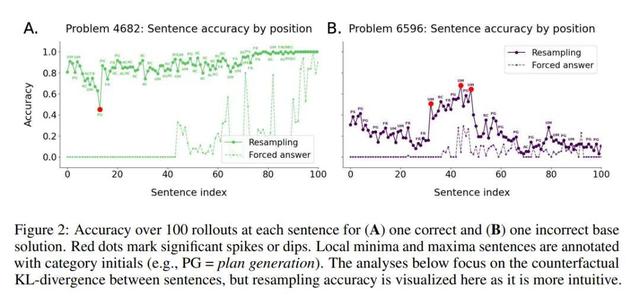
在之前的研究中 , 句子重要性通常是通過在推理過程中的每個句子位置強制模型給出最終答案來近似的 , 這種方法叫做「forced-answer」(如圖 3A) 。
這種方法的一個局限性在于 , 對于某些最終答案而言 , 句子 S 可能是必要的 , 但 LLM 在推理過程中往往較晚才生成該句子 。 這意味著 , 對于出現在 S 之前的所有句子 , 強制回答的準確率都會很低 , 從而無法準確判斷這些早期步驟的重要性 。
考慮一個由句子以及最終答案 A 組成的推理軌跡 。 作者通過重新采樣來定義一個度量 , 用以衡量句子 S 導致答案 A 出錯的程度 。 作者稱這個度量為反事實重要性 。 他們通過以下三個步驟來激勵并定義這個度量:
推理軌跡采樣 。 對于給定的句子 S_i , 生成 100 次推理軌跡 。 一種情況下包含句子 S_i(干預條件) , 另一種情況下用一個語義不同的句子 T_i 替代 S_i(基礎條件) 。
分布比較 。 計算兩種條件下最終答案分布的 KL 散度 。 從而得到一個衡量句子 S_i 改變答案程度的標量 。 作者稱其為重采樣重要性度量 。
語義過濾 。 重采樣重要性的問題在于 , 如果 T_i 與 S_i 相同或相似 , 那么我們無法得知 S_i 是否重要 。 因此 , 作者通過計算句子對的余弦相似度 , 并設定一個相似度閾值 , 篩選出那些與原句子 S_i 語義不同的替代句子 T_i 。 這樣可以避免因替代句子與原句子過于相似而導致的分析偏差 , 從而更準確地評估 S_i 對最終答案的影響 。
由于作者在給定句子 S_i 之后重新采樣所有步驟 , 因此避免了上述強制回答方法的局限性 。
在數據集中 , 他們發現規劃生成(Plan generation)和不確定性管理(uncertainty management)例如 , 回溯)句子的反事實重要性始終高于其他類別的句子 , 如事實檢索或主動計算(見圖 3B) 。 這支持了這樣一種觀點:高層次的組織性句子可以錨定、組織并引導推理軌跡 。 作者認為 , 與強制回答重要性和先前基于 token 或注意力的度量相比 , 這種方法提供了更有信息量的結果 。
通過注意力聚集衡量句子重要性
作者假設重要的句子可能會受到下游句子更多的關注 。 盡管注意力權重并不一定意味著因果聯系 , 但高度的關注是重要的句子可能對后續句子施加影響的合理機制 。 作者進一步推測 , 對重要句子的高度關注可能由特定的注意力頭驅動 , 通過追蹤這些頭 , 可能能夠確定關鍵句子 。
作者評估了不同的頭在多大程度上將注意力集中在特定的句子上 。 首先 , 對于每個推理軌跡 , 他們將每個注意力頭的 token-token 注意力權重矩陣取平均值 , 形成一個句子 - 句子矩陣 , 其中每個元素是兩個句子之間所有 token 對的平均值 。 基于每個注意力矩陣 , 他們計算其對角線下方列的平均值 , 以衡量每個句子從所有下游句子中獲得的關注程度;只在相隔至少四個句子的句子對之間取平均值 , 以專注于遠距離的連接 。 這為每個頭生成了一個分布(例如 , 圖 4A) , 并且每個頭通常將注意力集中在特定句子上的程度可以通過其分布的峰度來量化(對每個推理軌跡進行計算 , 然后在軌跡之間取平均值) 。 繪制每個頭的峰度圖表明 , 一些注意力頭強烈地將注意力集中在推理軌跡中特定的、可能是重要的句子上(圖 4B) 。
圖 5 表明 , 規劃生成、不確定性管理和自我檢查(self checking)句子始終通過接收頭獲得最多的關注(見圖 5) , 而主動計算句子獲得的關注最少 。 進一步與這一發現一致的是 , 根據重采樣方法 , 那些獲得高接收頭關注的句子往往也會對下游句子產生更大的影響 。 這些發現與以下觀點相符:推理軌跡是圍繞高層句子構建的 —— 這些句子啟動的計算可能連接高層陳述 , 但對整體推理路徑的影響可能微乎其微 。
通過「注意力抑制」衡量句子重要性
自然而言 , 考察注意力權重存在一個固有局限:它們無法衡量因果關系 。 此外 , 接收頭未必適合識別句子與單個后續句子間的關聯 。 因此 , 作者接下來聚焦于句子間依賴關系的因果歸因分析 。
基于重采樣的句子間分析雖能考察此類依賴關系 , 但在映射邏輯連接時精度有限 —— 因為反事實重要性反映的是句子對另一句子的總效應(包括直接和間接影響) 。 而本文方法旨在分離句子間的直接影響 , 從而有望實現對邏輯連接更精確的建模 。
作者通過抑制對特定句子的所有注意力(所有層和頭) , 觀察其對后續句子的影響 。 具體而言 , 影響程度定義為 token logits 與基線 logits(未抑制時)的 KL 散度 。 對后續句子的總效應計算為其組成 token log-KL 散度的平均值 。
該方法基于兩個假設:
- token logits 能準確捕捉句子的語義內容;
- 注意力抑制不會導致分布外行為的干擾 。
注意力抑制矩陣與重采樣矩陣的值呈現顯著相關性 。 在 20 條推理軌跡中 , 19 條顯示正相關 。 當僅分析推理軌跡中相距 5 句以內的案例時(可能更好捕捉直接效應) , 相關性更強 。 考慮到兩種方法測量的是因果關系的不同維度 , 且重采樣法本身包含隨機噪聲 , 這些相關系數具有實質意義 。 該結果支持了重采樣方法的有效性 。
案例研究
所采用的三種技術覆蓋了推理軌跡中不同層面的歸因分析 。 接下來 , 作者通過模型對具體問題的響應展示了這些技術的實用性和互補性 。 選用的例題是:「當十六進制數 66666_16 轉換為二進制表示時 , 它有多少個二進制位(比特)?」
重采樣
模型處理此問題的思路是:首先考慮 66666_16 包含 5 個十六進制位 , 而每個十六進制位可用 4 個二進制位表示 。 基于此邏輯 , 思維鏈最初得出「20 比特」的答案 。 然而這一初始答案忽略了 6_16 實際對應 110_2(而非 0110_2 , 因其最前面的 0 無效) , 因此正確答案應為「19 比特」 。 在第 13 句時 , 模型通過啟動將 66666_16 轉換為十進制再轉二進制的計算 , 轉向了正確解答 。
重采樣方法揭示了這一初始錯誤軌跡和關鍵轉折點(圖 2A 已展示) 。 具體表現為:第 6-12 句期間預期準確率持續下降 , 但第 13 句使反事實準確率急劇上升 。 值得注意的是 , 若采用強制模型立即生成響應的評估方法(如部分已有研究所示) , 則會完全錯過第 13 句的關鍵作用 —— 該方法僅會得到 0 準確率 。
接收頭
模型得出最終正確答案的推理軌跡可分解為多個計算模塊(見圖 6 流程圖) 。 首先 , 模型建立將 66666_16 轉換為十進制的計算公式(第 13-19 句);接著執行該公式的計算 , 得出 66666_16 對應的十進制值為 419430(第 20-33 句);隨后通過提出并求解新公式 , 確定正確答案為「19 比特」(第 34-41 句) 。 此時模型注意到與早期「20 比特」答案的矛盾(第 42-45 句) , 于是啟動雙重驗證計算:先確認十六進制轉十進制的準確性(第 46-58 句) , 再校驗二進制轉換的正確性(第 59-62 句) 。 在強化對「19 比特」答案的確信后 , 模型最終發現初始「20 比特」錯誤的根源:「因最前面的 0 不計入位數」(第 66 句) 。
上述過程基于作者對注意力模式的分析:接收頭精準定位了發起計算或陳述關鍵結論的句子 , 從而將推理軌跡劃分為具有明確意義的模塊(圖 6) 。
注意力抑制分析
除了被組織成計算模塊外 , 該推理過程還展現出與句子間依賴關系相關的框架結構(圖 6) 。 其中一個結構特征是包含錯誤提議、發現矛盾及最終解決的自我糾正模式 。 具體而言 , 模型最初提出「20 比特」的錯誤答案(第 12 句) , 隨后決定重新核驗 。 這導致與通過十進制轉換計算得出的「19 比特」答案產生矛盾(第 43-44 句) 。 在重新核驗支持「19 比特」答案的運算后 , 模型回到該矛盾點(第 65 句) , 最終解釋為何「20 比特」答案是錯誤的(第 66 句) 。 這可視為一個初步的思維鏈回路:兩個相互沖突的結論產生矛盾 , 進而促使模型解決該矛盾 。
在這個大跨度框架中 , 還存在驗證先前計算的更深層依賴關系 。 具體表現為:模型先完成 66666_16 轉換為十進制值 419430 的計算(第 32 句) , 隨后決定核驗該轉換結果(第 46 句) , 最終確認原始值正確(第 59 句) 。 這可視作思維鏈回路的進一步體現 。
作者基于論文前面提到的注意力抑制矩陣識別出這些關鍵連接 , 該矩陣在這些關聯位置呈現局部最大值(12→43、43→65、12→66;32→46、32→59) 。 值得注意的是 , 注意力抑制技術定位的多數句子與接收頭(receiver heads)高度關注的句子存在重疊 。 相較于接收頭的結論 , 注意力抑制技術還展示了信息是如何在這些構建推理軌跡的關鍵句子之間流動的 。
更多細節請參見原論文 。
推薦閱讀











- 插件形態AI應用爆發式增長,重塑產業格局
- OPPO小屏旗艦也很香,極窄直屏+天璣9400+潛望長焦,國補后3499元
- 2025年第一季度全球智能手表市場: 整體遇冷,華為小米逆勢增長
- 電池容量新高度!榮耀X70標配8300mAh電池,超長續航千元機來了
- 高通孟樸:終端側AI,開啟 “芯”增長
- Q2手機市場份額出爐:華為第一,蘋果增長,vivo出貨量第二卻遇冷
- 長江存儲在美國把美光給告了?中企正面硬剛美芯巨頭,干就完了
- 中國科學家在研究,下一代EUV光刻機,采用6.7nm波長光源?
- REDMI K90 Pro影像將有史詩級加強:潛望長焦首次下放
- 三星“無底線”清倉了,1TB頂級旗艦跌價4801元,鈦金屬+四長焦系統