
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
機器之心報道
機器之心編輯部
ChatGPT 現在可以思考行動 , 主動選擇工具 , 用自己的虛擬計算機為你完成任務 。
Agent AI 時代 , 比我們想象中來得要早一些 。
北京時間周五凌晨 , OpenAI 突然開啟了新產品直播 。
本次發布的是全新的 ChatGPT Agent , 它實現了通用智能體(Agent)能力的關鍵升級 。
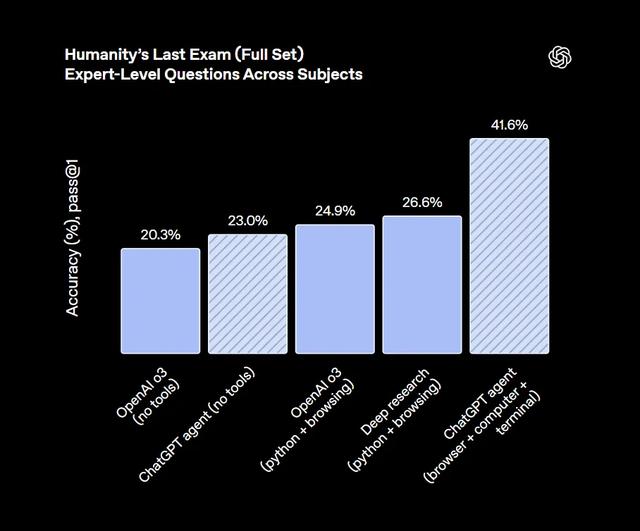
與以往的基礎大模型升級不同 , 通用 Agent 可以自動利用多種工具進行規劃 , 幫助人們完成復雜的任務 , 包括自動瀏覽用戶日歷 , 生成可編輯的 PPT , 運行代碼等等 。 Agent 能夠連接你的 Gmail、GitHub 網站獲取信息并解決問題 , 使用 API 來訪問各種應用 。 Agent 加持的 AI 智能有了大幅提升 —— 基于 ChatGPT Agent 的模型在 HLE 基準上拿到了 41.6% 的分數 , 是 o3 和 o4-mini 的幾乎兩倍 。
ChatGPT Agent 目前已向 OpenAI Pro、Plus 和 Team 計劃的訂閱用戶開放 。 想要使用的用戶在 ChatGPT 的工具下拉菜單中選擇「Agent 模式」即可 。
OpenAI 表示 , 企業版和教育版用戶預計將于夏季晚些時候獲得新功能 。 在正式發布時 , Pro 用戶每月通常最多可使用 400 次 Agent 提示 , 其他付費用戶則最多可使用 40 次 。 目前尚不清楚該功能何時會面向 ChatGPT 免費用戶推出 。
【剛剛,OpenAI通用智能體ChatGPT Agent正式登場】
這是 OpenAI 迄今為止最為大膽的一次新產品發布 , 從此以后 ChatGPT 成為了一款能夠為人們采取行動和分擔任務的 Agent 產品 , 已經遠遠超出了回答問題的范疇 。
OpenAI CEO 山姆?奧特曼(Sam Altman)表示 , 看著 ChatGPT 智能體使用計算機執行復雜任務對我來說是一個真正的「感受 AGI」的時刻 , 看到計算機思考、計劃和執行會帶來不同的感受 。
ChatGPT 現在可以使用自己的虛擬電腦為你完成工作 , 從頭到尾處理復雜任務 。 用戶不僅可以讓 ChatGPT 執行諸如「查詢年度財務報告」等請求 , 并智能地瀏覽網站、篩選結果 , 在需要時提示你安全登錄 , 運行代碼、進行分析 , 甚至可以交付可編輯的幻燈片和電子表格 , 總結其研究成果 。
比如讓「ChatGPT Agent 搜索查詢舊金山市年度綜合財務報告(2020-2024 年)」:
再比如輸入提示「我是一位網球迷 , 想去棕櫚泉觀看網球比賽 , 特別是在半決賽 / 決賽期間 。 我住在舊金山 , 請幫我制定一份詳細的三天行程 , 包括航班安排、酒店預訂、活動內容(比賽、徒步、美食、水療等) 。 我喜歡徒步旅行、純素食餐廳和水療 。 總預算為 3000 美元 。 這份行程需要包括:精確的時間安排;每項活動的內容、費用和其他細節;如有需要 , 提供購票或預訂鏈接」 , 接著讓 ChatGPT Agent 幫你制定詳細的行程:
這一新能力的核心是一個統一的智能 agentic 系統 , 它結合了三個早期突破的優勢 , 包括 Operator 的網站交互能力、deep research 的信息綜合能力 , 以及 ChatGPT 的智能推理與對話能力 。
ChatGPT 借助自己的虛擬計算環境 , 在推理與執行之間靈活切換 , 根據用戶的指令 , 從頭到尾處理復雜的工作流程 。最重要的是 , 用戶始終掌控全局 。 ChatGPT 會在執行任何重要操作前征求你的許可 , 你也可以隨時中斷任務、接管瀏覽器或停止運行 。
OpenAI 表示 , 「雖然 ChatGPT Agent 已經可以應對復雜任務 , 但這次發布只是開始 。 我們將持續迭代、定期推出重大改進 , 讓它變得更強大、更實用 , 服務于更多用戶 。 」
Operator 與深度研究的自然進化
過去 , Operator 和 deep research 各自具備獨特優勢:Operator 能夠在網頁上滾動、點擊和輸入 , 而 deep research 擅長分析和總結信息 。
不過 , 二者在不同場景下才發揮最大作用 , 各有不擅長的領域 。 Operator 無法深入分析或撰寫詳細報告 , 而 deep research 又無法與網頁交互、進一步篩選結果或訪問需要用戶登錄的內容 。
OpenAI 發現 , 許多用戶嘗試用 Operator 處理的任務 , 其實更適合用 deep research , 因此決定將二者的優勢整合在一起 。
通過將這些互補能力集成進 ChatGPT , 并引入更多工具 , OpenAI 在一個模型中解鎖了全新的能力 。 它現在可以主動與網站交互 —— 點擊、篩選并收集更精準、高效的結果 。 yonghu 也可以在同一個對話中 , 從自然的交流無縫過渡到發出具體操作請求 。
OpenAI 為 ChatGPT Agent 配備了一整套工具:包括一個通過圖形用戶界面與網頁交互的可視化瀏覽器、一個用于處理簡單推理類網頁查詢的文本瀏覽器、一個終端(命令行界面)、以及直接調用 API 的能力 。
該 agent 還可以利用 ChatGPT Connectors , 將 Gmail、GitHub 等應用連接進來 , 使 ChatGPT 能夠查找與你提示相關的信息 , 并將其用于回答中 。 用戶也可以通過接管瀏覽器 , 在任意網站上登錄賬戶 , 從而幫助它在信息檢索和任務執行方面更深入、更廣泛 。
為 ChatGPT 提供多種訪問和交互網頁信息的方式 , 意味著 ChatGPT Agent 能夠選擇最優路徑 , 以最高效地完成任務 。 例如 , 它可以通過 API 獲取用戶的日歷信息 , 使用文本瀏覽器高效處理大量文本內容 , 同時也具備通過可視化界面與專為人類設計的網站進行交互的能力 。
所有這些操作都是在 ChatGPT Agent 自己的虛擬計算機上完成的 , 這可以在使用多個工具時保留任務所需的上下文信息 。 ChatGPT Agent 可以根據需要選擇用文本瀏覽器或可視化瀏覽器打開網頁 , 從網上下載文件 , 在終端中運行命令處理文件 , 然后再通過可視化瀏覽器查看輸出結果 。 同時也會根據任務調整策略 , 以快速、準確和高效的執行 。
ChatGPT Agent 專為迭代式、協作式的工作流程而設計 , 遠比以往的模型更加互動和靈活 。 在 ChatGPT 執行任務的過程中 , 用戶可以隨時打斷它 , 進一步澄清指令 , 令其朝著期望的方向發展 , 或完全更換任務內容 。 它會在新的信息基礎上繼續工作 , 而不會丟失此前的進度 。
同樣地 , ChatGPT 也會在需要時主動向用戶請求更多細節 , 以確保任務始終與目標保持一致 。 如果某項任務耗時超出預期或陷入停滯 , 用戶可以選擇暫停任務、請求進度摘要 , 或者直接終止任務并獲取當前已有的部分結果 。 如果用戶在手機上安裝了 ChatGPT 應用 , 它還會在任務完成后發送通知 。
基準測試結果:拓展現實世界的實用性
ChatGPT Agent 及背后模型的能力提升體現在多個基準測試中的頂尖表現 , 評估內容包括網頁瀏覽和現實世界任務的完成能力 。
其中在「人類最后考試」(Humanity's Last Exam)評估中(這項評估衡量了 AI 在各個領域的專家級問題上的表現) , 支持 ChatGPT Agent 的模型在該評估中的 Pass@1 分數為 41.6 。
由于該 Agent 能夠動態規劃并自主選擇工具 , 它可以通過不同的方式處理相同的任務 。 在通過簡單的并行策略進行擴展時 —— 同時運行最多八次嘗試并選擇自我報告信心最高的結果 —— 該 Agent 的 HLE 得分提高到了 44.4 。
FrontierMath 是目前已知最難的數學基準測試 , 包含全新且未公開發表的問題 , 通常需要數學專家花費數小時甚至數天才能解決 。 在具備工具使用能力(例如可訪問終端以執行代碼)的情況下 , ChatGPT Agent 在該測試中達到了 27.4% 的準確率 , 遠遠超越此前的所有模型 。
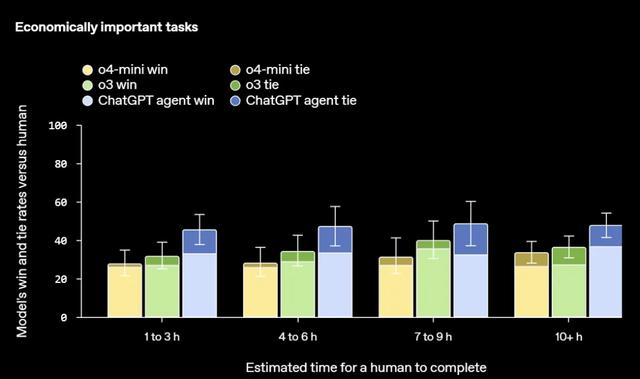
OpenAI 還使用模擬復雜真實任務的基準測試對該模型進行了評估 。 在一個用于評估模型在復雜、具有經濟價值的知識型工作任務中表現的內部基準中 , ChatGPT Agent 的輸出在大約一半的情況下可與人類相媲美 , 甚至優于人類 , 任務完成時間范圍不等 , 并且顯著優于 o3 和 o4-mini 模型 。
在 DSBench 基準測試中 , 用于評估 Agent 在涵蓋數據分析與建模的真實數據科學任務的表現 。 ChatGPT Agent 超越了人類的平均表現 , 且優勢明顯 。
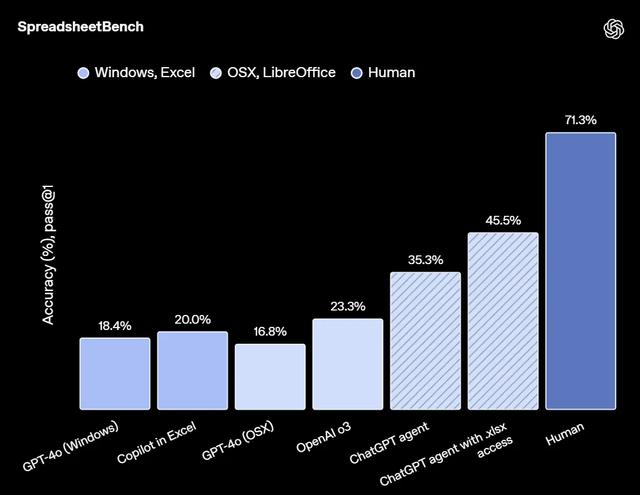
在 SpreadsheetBench 基準測試中 , 用于評估模型處理真實場景電子表格編輯任務的能力 。 ChatGPT Agent 表現遠超現有模型 。 當賦予直接編輯電子表格的能力時 , 它的得分更是高達 45.5% , 而 Excel 中的 Copilot 僅為 20.0% 。
方法概覽如下:SpreadsheetBench 的作者使用的是基于 Windows 系統的 Microsoft Excel 環境來評估電子表格任務 。 而 OpenAI 使用的是 macOS 系統和 LibreOffice , 這可能會導致評分上的細微差異 。 例如 , 作者報告 GPT-4o 在「整體高難度限制」項上的得分為 15.02% , 而 OpenAI 測得的結果為 13.38% 。 OpenAI 使用的是包含全部 912 道題目的完整基準測試集 。
在一個內部基準測試中 , OpenAI 評估了模型處理投資銀行分析師一至三年級建模任務的能力 , 例如:為一家《財富》500 強公司制作帶有規范格式和引用的三大財務報表模型 。 ChatGPT Agent 所依托的模型在這一評估中顯著優于 deep research 和 o3 。
OpenAI 還在 BrowseComp 基準測試中評估了 ChatGPT Agent 。 該基準由 OpenAI 于今年早些時候發布 , 用于衡量瀏覽型 Agent 在網絡上查找難以獲取信息的能力 。 ChatGPT Agent 在該測試中創下了新的 SOTA(當前最優表現) , 得分為 68.9% , 比 deep research 高出 17.4 個百分點 。
最后 , 在 WebArena 基準測試中 , 用于評估網頁瀏覽型 Agent 完成真實網頁任務的能力 。 ChatGPT Agent 在表現上超越了由 o3 驅動的 CUA(即驅動 Operator 的模型) 。
更多基準測試細節請參閱 ChatGPT agent 系統卡(System Card):
系統卡地址:https://cdn.openai.com/pdf/839e66fc-602c-48bf-81d3-b21eacc3459d/chatgpt_agent_system_card.pdf
最后 , 山姆?奧特曼發表了一篇長推介紹了 ChatGPT Agent 的安全限制 。
Agent 代表了 AI 系統能力的新高度 , 它能夠利用自身的計算機為你完成一些特殊而復雜的任務 。 它融合了 Deep Research 和 Operator 的精髓 , 但實際功能遠超想象 —— 它可以進行長時間思考 , 使用一些工具 , 進行更深入的思考 , 采取一些行動 , 再進行更深入的思考等等 。
例如 , 我們在發布會上展示了一個為朋友的婚禮做準備的演示:購買服裝、預訂行程、挑選禮物等等 。 我們還展示了一個分析數據并創建工作演示文稿的示例 。
盡管其效用很大 , 但潛在的風險也很大 。 我們已在其中構建了大量的安全措施和警告 , 以及比以往任何時候都更廣泛的緩解措施 , 從強大的訓練到系統安全措施再到用戶控制 , 但我們無法預見一切 。 本著迭代部署的精神 , 我們將向用戶發出很多警告 , 并給予用戶自主選擇是否謹慎采取行動的自由 。
我會向我的家人解釋這是前沿和實驗性的 。 這是一個嘗試未來的機會 , 但在我們有機會在現實世界研究和改進它之前 , 我不會將它用于高風險用途或獲取大量個人信息 。 我們尚不清楚具體會造成什么影響 , 但惡意行為者可能會試圖「誘騙」用戶的 AI Agent , 使其提供不該提供的隱私信息 , 并采取不該采取的行動 , 而這些行為的方式我們無法預測 。
我們建議授予 Agent 完成任務所需的最低訪問權限 , 以降低隱私和安全風險 。 例如 , 我可以授權 Agent 訪問我的日歷 , 以便安排一個合適的聚餐時間 。 但如果我只是讓它幫我買衣服 , 就不需要授予它任何訪問權限 。 諸如「查看我昨晚收到的電子郵件 , 并采取一切必要措施處理 , 不要問任何后續問題」之類的任務風險更大 。 這可能會導致惡意電子郵件中不可信的內容誘騙模型泄露你的數據 。
我們認為 , 重要的是從接觸現實開始學習 , 并且隨著我們更好地量化和降低潛在風險 , 人們應該謹慎而緩慢地采用這些工具 。 與其他新的能力水平一樣 , 社會、技術和風險緩解策略需要共同發展 。
網友一手體驗
至于這款 Agent 是否好用 , 不少網友現身說法 。
X 網友 @rowancheung 提前獲得訪問權限 , 并讓 ChatGPT Agent 在 20 分鐘內為他創建一個完整的提前退休計劃 。
拿到任務 , ChatGPT Agent 就開始查找溫哥華的當地稅法、分析平均每月支出率、計算 30 歲退休所需的儲蓄金額、研究最佳投資分配 , 還發現了 Rowan 從未聽說過的稅務優化策略、構建多種財務獨立提前退休(FIRE)場景 , 最終創建一個可下載的演示文稿 , 總結結果 。
Rowan 表示 , 這項工作如果由財務顧問完成 , 可能會花費 5000 美元以上 , 并且需要數周時間 。 其中電子表格和幻燈片生成能力確實不錯 , 但與 Manus 或 Genspark 等工具得到的結果類似 。
于是 , Genspark 聯合創始人、CEO Eric Jing 將 Rowan Cheung 的提示詞進行了 OCR , 并將其輸入到 Genspark 中 。
他表示 , 在相同的提示下 , Genspark 僅用了一小部分時間和成本 , 就生成了比 ChatGPT Agent 質量高得多的結果 。
還有網友讓 ChatGPT Agent 去 Tesco 食品店完成購物 , 訂購烤肉晚餐和粘稠焦糖布丁 。
他給出的提示詞也相當簡單:Help me do a tesco shop for a roast dinner this weekend for two people. Include a treat for desert.
「我看著它瀏覽網站、提示我輸入登錄信息、將商品加入購物車 , 并自主完成整個過程 , 真是太不可思議了 。 」
不過 , 該網友也坦言 , ChatGPT Agent 干活的整個過程大約花了 20 分鐘 , 如果自己手動操作可能會更高效一些 , 未來還有改進的空間 。
參考內容:
https://openai.com/index/introducing-chatgpt-agent/
https://x.com/OpenAI/status/1945890050077782149
https://x.com/rowancheung/status/1945896543263080736
https://x.com/ericjing_ai/status/1945915234784588272
https://x.com/thealexbanks/status/1945921363237052589
推薦閱讀












- AI辦公大戰升溫,OpenAI也要加入飛書和WPS的戰場?
- Meta又挖走OpenAI兩名頂尖AI人才 上月底已挖走3人
- 剛剛,OpenAI 發布 ChatGPT 版 Manus!奧特曼:感受 AGI 時刻
- 剛剛,OpenAI 發布了自己的 Agent模式,Manus Style
- 499元,小米剛剛公布的6000mAh新品,有點騷啊
- 剛剛,亞馬遜推Agent全家桶!5招連發,狂堆猛料,吹響AI集結號
- OpenAI正式引入谷歌云作為戰略供應商,強化ChatGPT全球算力部署
- 剛剛發布的小屏手機銷量榜,把我看懵了
- 種子輪就估值120億美元,她能打造另一個OpenAI嗎?
- 又一華人逃離OpenAI!“思維鏈第一人”加入Meta