
文章圖片
文章圖片
文章圖片
本文第一作者郭源是上海交通大學計算機系三年級本科生 , 研究方向為自主智能體和智能體安全 。 該工作由上海交通大學與瀾舟科技共同完成 。
- 論文標題:Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
- 項目主頁:https://ui-nexus.github.io/
- 論文鏈接:https://arxiv.org/abs/2506.08972
從原子任務自動化
到系統級端側智能
多模態大模型 (MLLM) 驅動的 OS 智能體在單屏動作落實(如 ScreenSpot)、短鏈操作任務(如 AndroidControl)上展現出突出的表現 , 標志著端側任務自動化的初步成熟 。
但是 , 真實世界的用戶需求常常包含復合長程任務 , 例如 “比較價格并在便宜的平臺下單” 任務 , 需要在多個應用程序中操作 , 收集和比較異源信息 , 并據此確定后續的操作步驟;“查看今日熱點新聞 , 概括并記錄” 的任務 , 需要在多個網頁之間導航 , 將設備操作與文本概括的通用推理能力交錯融合 , 并完成適時的信息傳遞 。 從簡單有序任務到復雜有序和復雜無序任務的過渡是從單智能體基座增強到 AI 操作系統的必經之路 。 當前主流的環境感知、動作落實和短序列軌跡微調等訓練方式顯著地提高了前述原子任務上的表現 , 但是復合長程任務帶來了長鏈條進度管理、信息收集和傳遞、操作與通用思考的結合等全新的挑戰 。
研究人員針對主流的移動端 GUI 智能體展開系統的研究 。 實驗顯示 , 現有的移動端 GUI 智能體在面對復合長程任務時都具有明顯的能力缺陷 , 展現出顯著的原子任務到復合任務的泛化困難 。
針對這一缺口 , 研究人員提出:
1. 動態評測基準 UI-Nexus:構建可控的動態測評平臺 , 覆蓋復合型、傳遞型、深度分析型等復雜長程任務 , 涵蓋 50 類中英文應用(包括本地功能應用和第三方在線應用) , 共設計 100 個任務模板 , 平均最優完成步數為 14.05 步 。
2. 多智能體任務調度系統 AGENT-NEXUS:提出輕量化調度框架 , 支持指令分發、信息傳遞與進程管理 。 該系統無需修改底層智能體模型 , 便于高效接入與多體協同 。
該工作為復合長程任務下的移動端智能體提供了有挑戰性的測試基準和開發平臺 , 也為展望未來復雜、精細的 AI 原生操作系統建立了雛形 。
移動端智能體
在復合長程任務中的能力瓶頸
隨著基座模型的持續增強和環境感知、單屏動作落實、靜態軌跡微調、強化學習等訓練策略的優化 , 基于多模態大模型的設備操控 GUI 智能體在單屏動作落實(grounding)和短鏈操作任務上的測試表現持續提升 , 已經能夠端到端地自動化執行網絡搜索等原子任務 。
但是 , 真實場景中的用戶指令常常包含長程場景與復合依賴需求 。 本文依據子任務的依賴關系分類 , 給出了常見的三種任務復合類型:
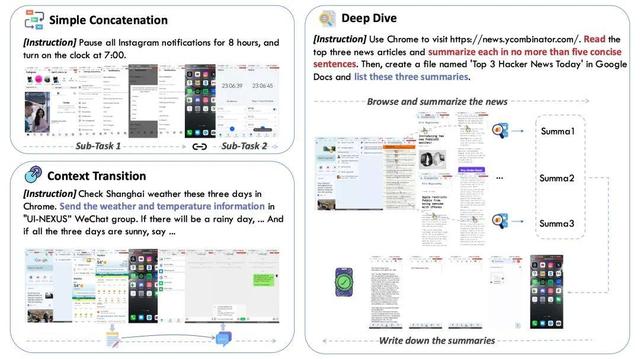
- 獨立組合型(Simple Concatenation):若干無依賴關系的原子子任務的拼接 。 如圖中的睡前設定指令 “Instagram 開啟消息免打擾 8 小時 , 并設定明早 7:00 的鬧鐘”
- 語境傳遞型(Context Transition):后續子任務需要繼承并利用前序任務產生的中間結果或界面狀態 , 需要把信息 / 上下文正確地帶到下一個 App 或頁面 。 如圖中先上網搜索天氣預報 , 并根據搜索結果發送微信消息的任務 。
- 深度分析型(Deep Dive):是語境傳遞型任務的一種特殊情況 。 在設備操控中不僅需要進行動作導向的推理以及信息的簡單記憶 , 還需要融入通用推理能力對中間信息進行深度的處理和分析 。 如圖中的今日 Hacker News 摘要任務 , 不僅需要在瀏覽器、Google Doc 中進行點擊、滑動等導航操作 , 還需要利用通用推理能力對當前頁面的新聞內容做摘要分析 。
依據子任務依賴結構的復合任務分類
研究人員在常用手機應用上構造代表性的測試任務 , 針對主流的 OS-Atlas UI-TARS Mobile-Agent 系列 , M3A 等移動端 GUI 智能體進行初步實驗 , 發現主流智能體在復合長程任務上明顯表現欠佳 。
對錯誤案例的細致分析顯示 , 主流移動端智能體由于缺乏有效的進度管理和信息管理機制等 , 展現出典型的失敗類型 , 如:
- 注意力渙散:直接給定復合任務指令時 , 容易造成語境過載(Context Overflow) , 導致智能體遺漏部分指令或子任務;
- 信息傳遞失敗:智能體缺乏信息管理和傳遞的能力 , 導致在傳遞型任務中胡亂執行需要前序信息的任務;
- 進度管理混亂:在未完成的子任務之間反復跳轉 。
針對移動端智能體復合任務的
全面測試基準
為了對移動端智能體在復合長程任務上的表現提供科學全面的測試基準與開發平臺 , 研究人員提出了 UI-NEXUS:一個針對移動端智能體復合任務的交互式測試基準 。
UI-NEXUS 測試基準概覽
如概覽圖所示 , UI-NEXUS 基準有如下的特點:
- 數據覆蓋:50 款 App(20 本地功能應用 + 30 中英在線服務應用) , 5 大應用場景;100 條指令模板 , 最優路徑 14.05 步 , 難度顯著高于同類基準 。
- 三類依賴結構:依據子任務的依賴關系 , 系統研究三種復合任務類型 —— 獨立組合型(Simple Concatenation)、語境傳遞型(Context Transition)、深度分析型(Deep Dive) 。
- ANCHOR 子集:為了提供可控、可擴展的測試開發環境 , 研究人員基于 AndroidWorld 的 20 個本地功能 App 構建了本地離線任務子集 UI-NEXUS-Anchor 。 該測試集中的任務環境可以通過數據庫、文件系統、adb 工具精準設定 , 支持任務指令可擴展性和測試環境可控性 。
- 細粒度指標:記錄端到端任務成功率、終止原因、Token 成本與推理時延 , 對智能體的表現進行細粒度分析 。
1. 單模型微調(Agent-as-a-Model):OS-Atlas-7B-Pro 和 UI-TARS-7B-SFT 都是基于 Qwen2-VL-7B 進行大量 GUI 領域訓練得到的智能體基座 , 可以通過單模型推理逐步執行手機操作任務 。
2. 工作流搭建(Agentic Workflow):通常利用 GPT-4o 等閉源模型輔以模塊化設計來構建智能體工作流 。 如 M3A 是 AndroidWorld 中提出的手機智能體 , 每步推理時利用 a11y tree 提取出元素列表作為輔助輸入 , 并使用 React 和 Reflexion 來進行動作推理和結果反思 。 Mobile-Agent-V2 和 Mobile-Agent-E 采取多智能體協作的模式 , 并輔以 OCR 和元素標記等模塊 , 進行手機任務自動化 。
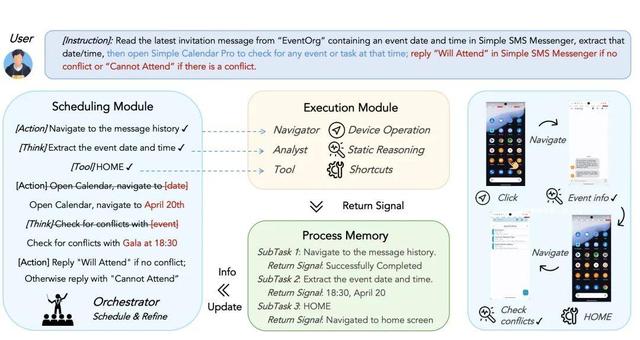
除了上述基線以外 , 本文還提出了 Agent-NEXUS:針對復合設備操作任務的調度系統 。 Agent-NEXUS 將高階調度與低階執行解耦 , 通過 Scheduling Module Execution Module 和 Process Memory 的協同工作完成復合長程任務的調度 。
在每個子任務完成后 , 調度模塊根據歷史進程信息和當前環境感知更新高階任務規劃 , 并將后續的第一個子目標傳給執行模塊的 Navigator/Analyst/Tool 進行具體落實 。 這樣的層次化調度模式讓低階執行模塊每次都收到意圖明確的原子任務 , 減輕了語境過載的風險 。
Agent-NEXU 架構示意圖
Agent-NEXUS 支持智能體的可插拔接入 。 在本實驗中 , 研究人員嘗試了用 UI-TARS-7B-SFT 和 M3A 作為低階執行模塊的智能體 。
實驗分析:
從原子到復合任務的泛化之路
研究人員在本地功能應用(UI-NEXUS-Anchor)、中文在線服務應用、英文在線服務應用三個測試子集 , 共 100 個指令模板上進行了測試 , 主要結論有:
- UI-NEXUS 測試基準對各個移動端 GUI 智能體 baseline 都造成很大挑戰 , 各智能體的任務完成率均低于 50%;
- 基于 Agentic Workflow 實現的智能體在復合長程任務上的魯棒性顯著優于基于 Agent-as-a-Model 的方法 , 但是基于 GPT-4o 的工作流帶來很高的推理成本和時延 , 限制了實際場景的應用潛力;
- AGENT-NEXUS 顯著提升任務完成率(+24% ~ +40%) , 同時僅帶來約 8% 的推理開銷增長 。
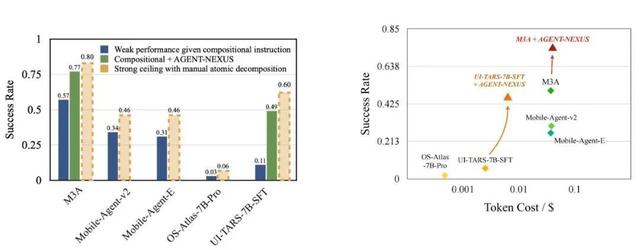
主要實驗結果
為了深入分析原子到復合泛化的表現 , 研究人員選取部分獨立組合型和語境傳遞型任務進行了進一步的分析實驗 。 研究人員對比了三種任務成功率:
1. 直接將復合指令給定智能體 , 測試智能體的任務完成率 , 作為原子 - 復合泛化中的 Weak Performance 。
2. 人為將復合指令拆分成多個原子指令(如將 \"In the Tasks app create and save a new task named 'Exercise' repeating every day. Then open the Broccoli recipe app and delete the 'French Fries' recipe.\" 拆分成 \"In the Tasks app create and save a new task named 'Exercise' repeating every day.\" 和 \"Open the Broccoli recipe app and delete the 'French Fries' recipe.\" 兩個原子指令 , 分別交付智能體執行 , 均成功則視為該任務成功 , 測定任務完成率 , 作為原子 - 復合泛化中的理論上的 Strong Ceiling 。
3. 將 UI-TARS-7B-SFT 和 M3A 接入 Agent-NEXUS 調度系統后的任務完成率 。
結果如下圖所示:
所有移動端智能體 baseline 在給定手動拆分后的原子指令時表現都顯著更優 , 其中 UI-TARS 的差異尤其顯著 , 從 11% 直接提升到了 60% 。 這是由于其在微調后已經訓練了充分的 GUI 操作能力 , 而直接給定復合指令時的極低完成率主要受制于進度管理和信息管理功能的缺失 。
Agent-NEXUS 調度框架有效地彌補了原子到復合任務的泛化損失 , 在成本提升可控的同時讓任務完成率大幅提升 , 逼近了 strong ceiling 的表現 。
此外 , 針對不同智能體構建方案的進一步討論和分析顯示:
1. 在線服務類 App 因信息動態性強、UI 結構復雜及環境干擾頻繁 , 構成了更大的挑戰;
2. 基于 GPT-4o 搭建的 Agentic Workflow 由于具有多智能體協作 , 復雜推理等機制 , 在復合任務上的表現顯著更優 。 但是 , GPT-4o 在 GUI 操作任務上的原生領域能力比較有限 , 需要借助元素列表、屏幕解析工具等輔助 , 加之本身調用成本較高 , 限制了實際應用的可行性 。
相比之下 , 基于開源規模領域微調的 Agent-as-a-Model 在短鏈操作內部邏輯、動作落實、推理速度等方面有顯著優勢 , 但由于訓練方式的限制 , 當面對選擇等復合邏輯、動作和通用推理交錯等任務需求時完全無法應對 , 容易出現盲目執行的現象 , 需要借助系統級的設計來增強 。
3. Memory 機制的設計在處理復合長程任務中至關重要 。 當前移動端智能體的 Memory 機制主要包含無記憶(如 OS-Atlas-Pro , 只根據動作歷史和當前屏幕預測下一步動作 , 沒有儲存歷史信息的機制)、部分記憶(如 UI-TARS , 每次輸入前 N 張屏幕觀察 , 一定程度上可以利用前 N 張屏幕中的有利信息 , 但是在多源、跨越較大的信息傳遞和整合中收到較大限制)、主動記憶(如 Mobile-Agent-V2 和 Mobile-Agent-E 每一步都會主動判斷當前是否有信息要存儲到記憶模塊) 。
主動記憶在復雜信息依賴的復合長程任務中帶來更優的表現 , 但是每一步都判斷是否記憶帶來較大的計算冗余 。 Agent-NEXUS 通過將界面導航 。 信息收集、信息處理都顯式在高階調度中分配好次序 , 在開銷可控的同時實現了多源信息的管理和整合 。
未來展望:
面向新一代 AI 操作系統
本文不僅全面、深入地探討了當下移動端智能體研究中迫切需要深入發掘的一個方面:復合長程任務 , 也暢想了新一代 AI 操作系統的雛形 。
【手機AGI助手多遠?移動智能體復合長程任務測試基準與調度系統發布】在未來 , 我們不僅需要能依據一個指令為人類自動化完成簡單操作的智能體模型 , 更希望構建能夠高效協調、處理、調度復合任務需求的系統級端側智能 。 我們相信 , 當這樣的評測基準與調度框架被廣泛采用并不斷演進 , 移動設備將真正蛻變為具備類操作系統層次智能的個人助手 , 為人機協作打開新的想象空間 。
推薦閱讀













- 手機的NFC功能,到底有什么用?這4個功能,非常哇塞
- 榮耀Magic8 Pro再次被確認:雙兩億像素+雙3D,還有對手嗎?
- 國內手機榜單更新:蘋果第三,小米第二,第一名意料之中
- eSIM卡到底適合用在手機上嗎?或許像5G一樣并不太實用!
- “銷量爆棚”的小屏手機,驍龍8至尊版+徠卡三攝,降幅高達1000元
- 主攝潛望雙2億?榮耀Magic 8 Pro陷鏡頭羅生門!數碼博主爆料分歧
- 螞蟻集團或新設立AGI研究中心,由藍振忠領導
- iQOO Z10 Turbo+預熱:全球首款8000mAh高性能手機
- 杜絕“性能過剩”,手機品牌可不會說真話,因為你只是“韭菜”
- 明年旗艦手機“主攝”普遍大升級,但代價是什么