
文章圖片
文章圖片

文章圖片
機器之心原創
作者:張倩
在 Transformer 問世并統治大模型領域八年之后 , 親手創造它的谷歌也有了另起爐灶的苗頭 。
上個月 , 谷歌產品負責人 Logan Kilpatrick 指出現有注意力機制的局限性 , 緊接著谷歌就推出了新架構 MoR 。 這些動作表明 , AI 領域的「架構革新」已成為廣泛共識 。
在最近開幕的 WAIC 世界人工智能大會上 , 我們也看到了這種趨勢 , 甚至國內企業的做法比谷歌的變革還要徹底 。
視頻中的這個靈巧手是由一個離線的多模態大模型驅動的 。 雖然模型只有 3B 大小 , 但部署到端側后 , 無論是對話效果還是延遲幾乎都可以媲美云端運行的比它要大得多的模型 , 而且它還擁有「看、聽、想」等多模態能力 。
重要的是 , 它并非基于 Transformer , 而是基于國內 AI 創企 RockAI 提出的非 Transformer 架構 Yan 2.0 Preview 。 這個架構極大地降低了模型推理時的計算復雜度 , 因此可以在算力非常有限的設備上離線運行 , 比如樹莓派 。
而且 , 和其他在設備端運行的「云端大模型的小參數版本」不同 , 這個模型擁有一定的原生記憶能力 , 能夠在執行推理任務的同時把記憶融入自己的參數 。
也就是說 , 在和其他大模型對話時 , 你每次打開一個新的窗口 , 模型都不記得你們之前聊過什么 , 就像一個每天睡一覺就會把你忘了的朋友 , 每天都見但每天都是「初見」 。 相比之下 , 基于 Yan 架構的模型會隨著時間推移越來越了解你 , 并基于這些信息去回答你的每一個問題 。 這是當前大多數基于 Transformer 的云端大模型都做不到的 , 更不用提被剪枝、蒸餾等手段破壞了再學習能力的「小模型」 。
為什么 RockAI 要對 Transformer 進行如此徹底的變革?這些變革是怎么實現的?對于 AGI 的實現有何意義?在和 RockAI 的創始團隊深入對談后 , 我們得到了一份有價值的答案 。
Transformer 火了那么久 , RockAI 為什么要「另起爐灶」?
RockAI 對 Transformer 的挑戰不是今年才開始的 。 其實早在 2024 年 1 月 , 他們就推出了 Yan 架構 1.0 版本 , 在此之前已經花了兩年時間探索架構創新 。
眾所周知 , Transformer 存在「數據墻」和「算力依賴」等問題 。 一方面 , 現有的大模型都是用海量數據進行預訓練 , 但隨著高價值數據獲取難度越來越大 , 這條路變得越來越難走 。 另一方面 , Transformer 模型的推理對算力要求非常高 , 如果不經過量化、裁剪等操作 , 模型很難在低算力設備上直接部署 。 而且 , 即使能夠部署 , 這樣的模型也很難再進行大的更新 , 因為反向傳播所需的計算量非一般設備可以負荷 , 「訓推同步」(即讓模型在執行推理任務的同時還能進行學習和參數更新 , 就像小孩在和大人相處的過程中學習新東西)很難實現 。 而量化、裁剪等操作更是破壞了模型的再學習能力 。
如此一來 , 設備端的 Transformer 模型就成了一個「靜態」的模型 , 其智能水平在模型部署時就被鎖死 。
為了從根本上解決這些問題 , RockAI 從一開始就走了一條非常徹底的變革路線 , 從 0 到 1 探索非 Transformer、非 Attention 機制的 Yan 架構 。更難能可貴的是 , 他們不僅快速找到了有效的技術路徑 , 還成功在算力有限的設備上實現了商業落地 。
Yan 2.0 Preview:全球首個擁有「原生記憶力」的大模型
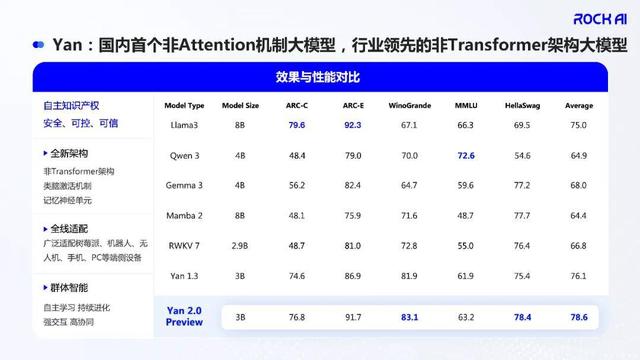
下圖展示了 Yan 2.0 Preview 與其他架構的效果與性能對比結果 。 從中可以看出 , 無論是相比于 Transformer 架構下的核心主流模型 , 還是非 Transformer 架構的新一代模型 , Yan 2.0 Preview 在生成、理解以及推理等多個關鍵指標上都有不錯的優勢 , 這充分說明了 Yan 架構在「性能 / 參數」比(即效率)上的巨大優勢 。
當然 , 這還不是核心看點 , 畢竟在 Yan 1.3 的時候我們就已經見識過它驚艷的計算效率 。 這次的看點是「記憶」 。
我們觀察到 , 無論是最近的新論文、新產品還是公共討論 , 「記憶」都在成為一個焦點 —— 它既被視為當前 LLM 的關鍵短板 , 也被看作下一輪 AI 應用的商業化落地突破口 。 想象一下 , 一個會說話、擁有和你之間專屬記憶的 Labubu 在和你相處多年之后 , 是不是情感羈絆更深?
不過 , 在技術路線上 , 當前業內主要還是用一種「外掛」的方式(如長上下文疊加搜索引擎或 RAG)來幫大模型加長記憶 。 RockAI 并不看好這種方式 , 因為首先 , 它把信息作為一串序列來處理 , 沒有真正的「時間」概念(這點對于隨時間演進的真實學習至關重要) , 這和人類的記憶方式有著本質的區別 。 其次 , 它無法實現真正的個性化 。
「回顧人類社會 , 每個人都擁有獨特的記憶 。 人與人之間的差異正是源于不同的記憶和經驗 , 這些差異最終形成了人類社會的多樣性 , 塑造了我們各自不同的行為方式和表達風格 。 目前 , 我們使用的商業模型本質上都是云端的同一個模型 , 缺乏真正的個性化 , 只能通過調取聊天記錄來提供上下文 。 這種模式存在明顯局限 —— 比如在寫作時 , 模型無法根據用戶的個人風格來生成內容 。 」RockAI CEO 劉凡平指出 。
【WAIC現場,全球首個擁有原生記憶力的大模型亮相,不是Transformer】他認為 , 只有在模型中融入原生記憶能力 , 這種情況才能發生改變 。 因此 , 他們的 Yan 2.0 Preview 選擇了另一條路線 —— 將模型理解后的信息內化到神經網絡的權重中 , 使其成為模型自身的一部分 , 這更接近生物的記憶方式 。
下圖是 Yan 2.0 Preview 架構示意圖 。 它通過一個可微的「神經網絡記憶單元」實現記憶的存儲、檢索和遺忘 。
在原理上 , 這種機制與人工智能從早期機器學習到深度學習的演進有相似之處 。 早期機器學習需手動設計或提取特征 , 可解釋性強 , 但定制化嚴重 , 對專家經驗依賴度高 。 深度學習則可自動提取特征 , 通過設計神經網絡、設定優化目標和策略 , 在數據語料上完成模型訓練 , 實現端到端學習 。 與之類似 , Yan 2.0 Preview 也實現了端到端的記憶 , 無需用戶去手動管理外掛知識庫(增刪改查) , 使用起來更加便捷 。
在現場 , 我們通過一個「現學現會」的機器狗感受到了 Yan 2.0 Preview 的原生記憶能力 。 在「聊天窗口」重開后 , 機器狗依然能記得它學過的動作和偏好 。
當記憶深度融合進模型架構 , 它所帶來的不再是短暫的「緩存」 , 而是一種具備時間維度、個性化特征和交互上下文的「智能積累」 。 這種模式成熟后 , 或將打破現有大模型依賴海量數據的學習范式 。
模型角色也將隨之轉變 —— 從單純的回答者 , 逐步成為用戶思維與決策的延伸體 , 真正實現「長期陪伴、個性服務」 。 當這一能力在本地終端部署時 , 結合端側的隱私保障與實時響應優勢 , 設備便從被動工具蛻變為擁有感知、記憶和學習能力的「數字大腦」 。
離線智能:「讓世界上每一臺設備擁有自己的智能」
每個嘗試挑戰 Transformer 的研究者 , 都深知這件事做成有多難 。 RockAI CTO 楊華表示 ,RockAI 之所以能堅持至今 , 背后是團隊多年來所秉持的三個核心理念:
第一 , 他們認為 , AI 應該是普惠的 , 不應只存在于云端 。 AI 必須與物理世界交互才能發揮最大價值 , 這要求它必須存在于設備上 。 這點已經成為業界共識 , 也是當前具身智能、空間智能等方向火爆的原因之一 。
第二 , 從長遠來看 , 一個真正的智能設備不應是靜態的 , 而應能成長和進化 。 具備學習能力才能確保「個體」智能足夠聰明 。 這點也在最近業界對「自我進化 AI」的討論中得到了體現 。 不過 , RockAI 強調 , 這種自我進化應該發生在「個體」設備上 , 而不是一個云端的大模型上 。
第三 , 在「個體」變得足夠聰明之后 , 它們所組成的網絡有望涌現出群體智能 , 就像已經創造出如此璀璨文明的人類社會 。 RockAI 認為 , 群體智能是邁向通用人工智能(AGI)的關鍵路徑 。
這些理念落實到行動 , 就形成了 RockAI 當前的主要使命 ——「讓世界上每一臺設備擁有自己的智能」 。
這個使命聽上去很像「端側智能」 。 但楊華強調說 , 他們追求的其實是「離線智能」 , 只使用本地設備的算力 , 不像很多采用「端云結合」的設備一樣需要聯網 。 而且在這種離線運行的模式下 , 模型能夠實現自主學習 , 而不是部署的時候就被鎖死 。 擁有這種自主學習能力的模型可以理解為一個有學習潛力的孩子 , 盡管剛走出家門時能力不及 30 歲的博士 , 但隨著后續成長會變得越來越強 。
不要小看這種「成長」的價值 , 未來的設備 PK 的可能就是這種能力 。 劉凡平提到 , 現在我們買硬件主要看配置 , 都是一次性買賣 , 買到手里就開始貶值 。 但有了記憶和自主學習能力之后 , 硬件的長期價值才開始顯現 , 智能的程度和進化能力會成為硬件的差異化賣點 。
此外 , 這種「成長」也為群體智能的涌現提供了可能 —— 只有當每臺設備都具備自主學習能力時 , 它們才能真正實現知識共享、協同進化 , 最終涌現出超越單體智能簡單相加的集體智慧 , 這也是 RockAI 的終極愿景 。
從「質疑」到「共識」:RockAI 一直在做「難而正確」的事情
回顧過去幾年的研發歷程 , RockAI 能夠明顯感覺到外界對他們所選擇的技術路線的態度轉變 。
幾年前 , 提到要做群體智能、要另起爐灶研發新架構 , 外界的反應更多是新奇、不解和質疑 , 因為這不像一個初創團隊該做的事情 。
這次原生記憶能力的展現 , 讓大家看到了 RockAI 的與眾不同 。 他們并非停留在簡單的模型訓練與參數堆疊層面 , 而是在堅持「難而正確」的技術路徑上 , 以「記憶」為核心重新定義大模型的能力邊界 , 帶來了驚人的使用體驗 。
RockAI CMO 鄒佳思說 , 這一技術路線的選擇讓他們在整個 WAIC 會場顯得非常與眾不同 , 很多對端側部署、記憶能力有需求的硬件廠商來找他們了解技術方案 。 這些廠商也嘗試過基于 Transformer 的模型 , 但體驗明顯沒有滿足需求 。 此外 , 還有一些廠商已經和 RockAI 達成了合作 。 非 Transformer 的 Yan 架構正在 AI 硬件市場擴散開來 。
不得不承認 , RockAI 幾年前的決定非常有前瞻性 , 也用科研、商業化成果回應了外界的質疑 。
楊華表示 , 未來 , 他們要繼續做這件「難而正確」的事情 。 甚至為了實現更高效的自主學習能力 , 他們在持續向人工智能的根基 —— 反向傳播算法發起挑戰 , 目前的解決方案已經在小規模數據上完成了指標測試和訓練收斂性驗證 , 證明了方案的基本可行性 。
在眾多 AI 創業公司中 , 這種前瞻性和堅持自己道路的韌性非常少見 , 很像 OpenAI 等前沿實驗室的來時路 。 畢竟在 Ilya 忙著擴大規模時 , scaling law 也還沒成為共識 。 從 RockAI 身上 , 我們看到了一種難能可貴的「長期主義」精神 —— 在浮躁的創業環境中 , 依然愿意花費數年時間去攻克底層技術難題 , 去驗證那些看似「不切實際」的技術理念 。
創新是孤獨的 , 期待 RockAI 和更多探索者在這條路上走得更遠 。
文中視頻鏈接:https://mp.weixin.qq.com/s/SMGF77V0z6yoa6G6fDe7WQ
推薦閱讀















- 智元四大明星機器人集體亮相WAIC2025 大秀才藝 干活給力
- 穩居Mini LED全球第一,TCL電子增收更增利
- iQOO Z10 Turbo+預熱:全球首款8000mAh高性能手機
- 猛瑪新LOGO全球首秀!影視颶風助陣,引爆BIRTV
- 英特爾啟動重大重組:裁撤15%員工、收縮全球產能,押注AI與先進制程
- 一臺30億!全球頂級光刻機出貨,英特爾搶跑,臺積電三星分道揚鑣
- 36氪攜手WAIC2025打造「氪話未來直播間」,聊透AI的未來信號
- 星鏈翻車了,全球化事故,馬賽克致歉!
- TCL上半年Mini LED電視出貨全球第一,Q10L系列成關鍵利器
- 2025年全球折疊手機市占預估:華為市占有望達34.3%