文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
CAFT團隊 投稿
量子位 | 公眾號 QbitAI
告別Next-token , 現在模型微調階段就能直接多token預測!
從GPT到Claude , 當前主流LLM都依賴next-token prediction(下一token預測)進行訓練 , 但它卻讓AI很難真正理解跨越多token的完整概念 。
于是南洋理工大學最近提出了一項新技術——概念感知微調(CAFT) , 首次實現將multi-token prediction(多token預測)引入微調階段 , 讓模型能夠像人類一樣理解和學習完整概念 。
原來LLM只能碎片化理解每個token , 現在CAFT可以為模型添加額外的輔助頭 , 在主模型學習下一個詞的同時 , 幫助學習后續token , 并通過動態調整權重 , 確保模型始終優先優化主要任務的損失 。
【突破單token預測局限!南洋理工首次將多token預測引入微調】最終LLM可以兼顧多token概念學習 , 形成更為完整的認知 , 在推理和生成能力增強的同時 , 既不會影響模型本身 , 也不會額外增加多余成本 。
另外研究人員通過實驗發現 , CAFT在編程、數學、生物醫學等多個領域都能顯著提升模型性能 , 或許未來將會讓AI訓練范式迎來根本性轉變 。
下面是有關CAFT的更多詳細內容 。
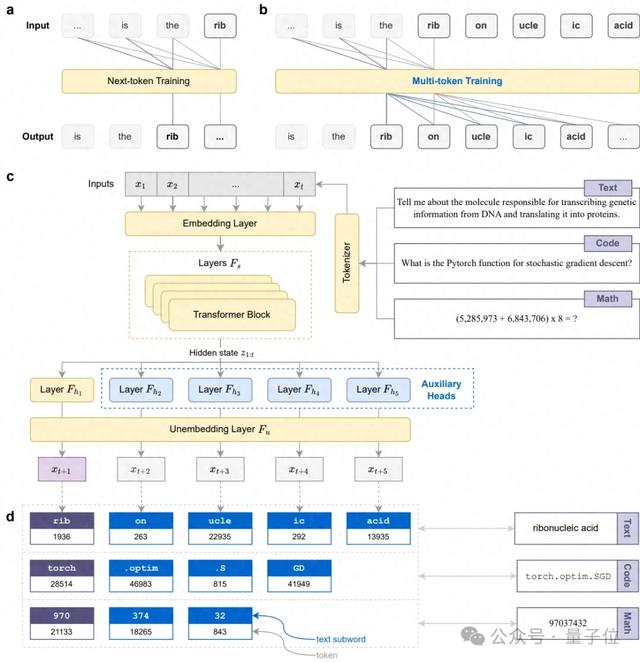
Next-token預測:AI的“基因密碼”首先 , next-token prediction的基本思想是在已知上下文的基礎上 , 預測最有可能的下一個token 。
舉個例子 , 針對句子“人工智能將改變_” , 你可能會直接預測出“世界”、“未來”或“社會” , 但是next-token prediction的預測流程則分為以下三步:
分詞:例如將“人工智能”拆分為“人工”和“智能” 。序列建模:讓模型逐個學習每個token與其前文的關系 。概率預測:為所有候選token分配概率 , 并選擇最高者作為輸出 。Next-token將會在預訓練里的大規模語料上學習語言統計規律與通識知識 , 然后在微調中通過特定任務數據學習具體行為模式 , 決定模型實際表現 。
但無論是預訓練還是微調 , next-token prediction都只會在每一步中只預測下一個token , 再依次進行 。
與此同時 , 這也帶來了一個根本性缺陷 , 即它將完整概念拆解為碎片 , 阻礙模型形成整體認知 。
例如“ribonucleic acid”(核糖核酸) , Llama 3分詞器就會將其拆解為:“rib”→“on”→“ucle”→“ic”→“acid” , 當模型預測“rib”時 , 無法預見“onucleic acid” , 因此無法理解這是一個生物學分子概念 。
又比如說將“北京大學”拆成“北”、“京”、“大”、“學”分開記憶 , 這嚴重破壞了語義完整性 。
所以next-token prediction存在前瞻能力差、不擅長處理跨概念的復雜推理、學習效率低、結果高度依賴具體分詞器等問題 。
Meta等機構對此提出可以在預訓練階段嘗試multi-token prediction , 但同樣也面臨以下限制:
預訓練成本過大 , 是微調階段的上千倍 。僅能提升通用語言能力 , 對具體概念理解幫助有限 。直接應用于微調時會造成分布偏移 , 從而導致性能下降 。這讓multi-token prediction只適用于預訓練階段 , 難以普及 , 所以研究團隊提出了新技術CAFT , 將multi-token prediction引入微調 。
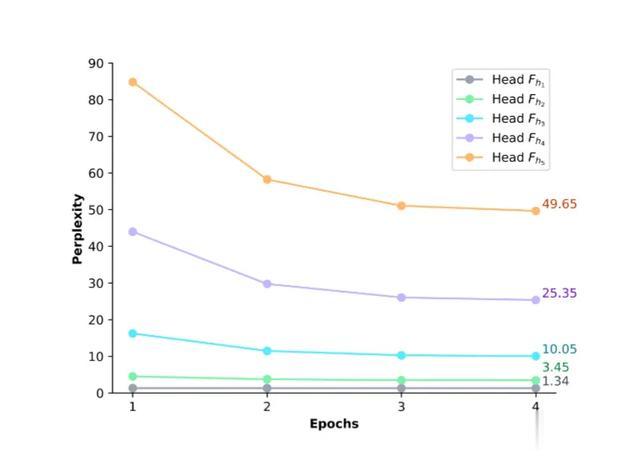
CAFT:打破瓶頸的概念感知微調方法CAFT在架構上主要包括輔助頭、損失函數兩部分 , 輔助頭含獨立隱藏層 , 且共享輸出層 , 以降低參數成本 , 損失函數為:
其中L?指原始next-token損失 , β是控制輔助損失的權重(設為0.01 , 確保主任務優先) , γ是反射正弦動態調整因子 , 訓練初期高 , 后期低 , α是幾何衰減因子 , 越遠的token權重越小 , t指token位置 。
在微調結束后 , 還可以直接丟棄輔助頭 , 讓推理開銷為零 。
CAFT采取分階段訓練策略 , 可分為兩個階段:
輔助頭預訓練在原模型上添加n-1個輔助預測頭 , 然后使用通用指令數據集訓練輔助頭 , 分別預測第2、3、4…個未來token 。
其中需要使用原模型自己生成的回答作為“偽標簽” , 避免分布偏移 , 且輔助頭訓練一次即可 , 多任務可通用復用 。
概念感知微調在特定任務上同時優化原始預測頭和輔助頭 , 然后用特殊設計的損失函數確保主目標仍是第一個token 。
利用動態權重調整策略 , 訓練初期關注多token概念學習 , 后期聚焦任務表現 。
最終CAFT可實現極低的使用門檻 , 只需要幾行代碼 , 就能結合任意預訓練模型 , 在成本上遠低于重新預訓練 , 只略高于傳統微調 。
CAFT的全面驗證:從代碼到生命科學研究團隊在五個不同領域任務上測試了CAFT , 將其與傳統的next-token微調(包括全量微調與LoRA微調)進行對比 。
所有結果均為5次獨立評估的平均值及95%置信區間 , 部分任務在微調前會對輔助頭進行1個epoch的預訓練 。
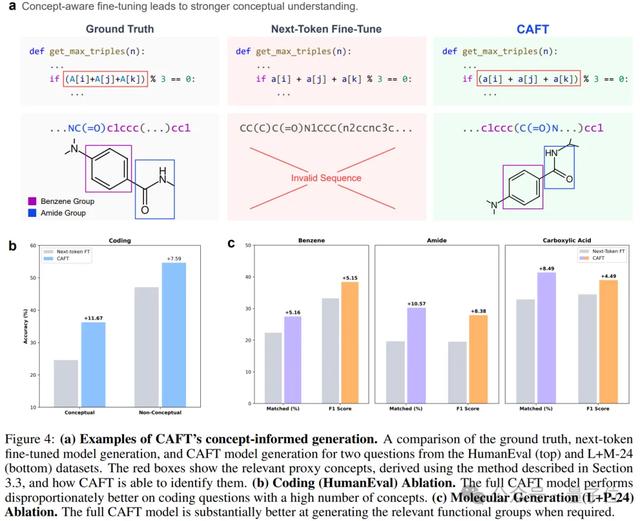
在編程任務中 , 由于存在大量跨token的語義單元 , 例如Python中的“_name_”會被分為“_”、“name”、“_”三個token , 但需整體理解 , 所以借助HumanEval數據集 , 判斷CAFT能否讓模型能夠整體理解這類編程概念 。
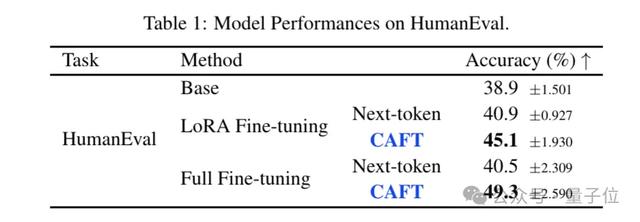
實驗結果表明 , LoRA CAFT在準確率上從40.9%提升至45.1% , Full CAFT則從40.5%提升到49.3% 。
然后將題目按概念密度分類 , 發現CAFT在高概念密集題目上提升更顯著(+11.67%vs+7.59%) , 證實了概念學習的有效性 。
在數學推理上 , LoRA CAFT在MATH-500數據集里性能提升了1.7%(22.9%到24.6%) , Full CAFT則是1.5%(23.7%到25.2%) 。
而當CAFT置于臨床文本中 , 由于醫學文本充滿復雜專業術語 , 被拆分后往往失去意義 , 此時讓CAFT完成醫學術語整體理解極具挑戰性 。
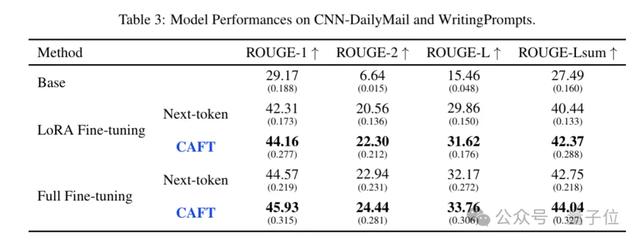
但CAFT仍然在MIMIC-IV-BHC數據集上表現良好 , 在ROUGE等指標上全面優于傳統方法 , 其中ROUGE-1從44.57提高到45.93 , ROUGE-2從22.94提高到24.44 , ROUGE-L從32.17提高到33.76 , 說明其能更好地捕捉長文本中的概念 。
在官能團結構理解上 , 由于化學分子包含功能性“官能團” , 如苯環、酰胺基團等 , 而SMILES序列中的官能團是典型的多token概念 , 傳統方法很難整體學習 。
CAFT可以很好地彌補這一點 , 準確匹配率從原來的0.14% , 提升了4倍 , 到0.54% , 有效分子比例從92.38%改進到97.14% , 結構相似性也得到了顯著改善 。
進一步進行官能團學習驗證 , 發現苯環識別中F1分數大幅提升、酰胺識別中準確率和召回率雙重改善、羧酸識別中復雜分子的識別能力增強 。
另外為考驗CAFT泛化能力 , 讓CAFT根據功能設計蛋白質序列 , 由于蛋白質使用氨基酸編碼 , 與自然語言差異極大 , 測試環境相當極限 。
實驗結果顯示 , 序列同一性從20.32%提升到22.14% , 序列對比分數也從原來的負值(-16.01)提升到正值(3.18) , 結構置信度從52.60變為54.30 , 結構相似性從33.07%變為35.12% 。
其中 , 25.0%的生成序列具有高結構置信度(70) , 比傳統方法的20.0%有了顯著提升 。
最終 , 研究團隊通過在廣泛領域中實驗 , 驗證了CAFT實現multi-token prediction在微調階段的可行性 , 其易用性和低成本也展示了其可能替代現有next-token prediction的巨大潛力 , 為理解模型內部機制提供了新視角 。
論文鏈接:https://www.arxiv.org/abs/2506.07833項目鏈接: https://github.com/michaelchen-lab/caft-llm
— 完 —
量子位 QbitAI
關注我們 , 第一時間獲知前沿科技動態
推薦閱讀














- 鴻蒙OS6開發者預覽版Beta:招募再次開啟!鴻蒙OS5:終端數量突破千萬
- 撐起單卡到十萬卡算力!無問芯穹發布“三個盒子”,全場景提升智能效率
- 余承東宣布: 鴻蒙 5 終端數量突破 1000 萬臺 華為“純血鴻蒙”進入加速跑
- 中興在巴基斯坦取得重要突破!
- 華為研發再突破,萬億投入見成效,又創下一個“全球第一”
- 款款爆品!年輕人為何愿為“會發光的深淵音箱”瘋狂買單?
- 三星救星駕到:1200億芯片大單,砸向3nm/2nm
- 中國貢獻超五成,RISC-V芯片出貨量突破百億顆
- 三星Exynos 2600跑分飆升!三星2納米芯片單核突破2800分
- WAIC見證中國AI突破:Rokid Glasses定義下一代交互標準