
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
智東西
作者 | 陳駿達
編輯 | 漠影
最近幾周 , 國產開源模型迎來一波集中爆發 , 互聯網大廠和AI獨角獸們紛紛甩出自家的開源王炸 , 接力登頂全球開源模型榜首 。 而就在本周 , 又有一款國產開源模型火爆全網 。
這一模型來自素有“中國OpenAI”之稱的智譜 , 是其最新一代旗艦模型GLM-4.5 。 發布時機也十分湊巧——剛好卡在網傳的OpenAI的GPT-5發布之前 , 同樣主打推理、編程、智能體等能力 。
不過 , 智譜已經憑借開源搶占了先機 , 在國內外提前收獲了一波流量 , 官宣推文獲得77萬+閱讀 , 還獲得開源托管平臺HuggingFace CEO的轉發支持 。
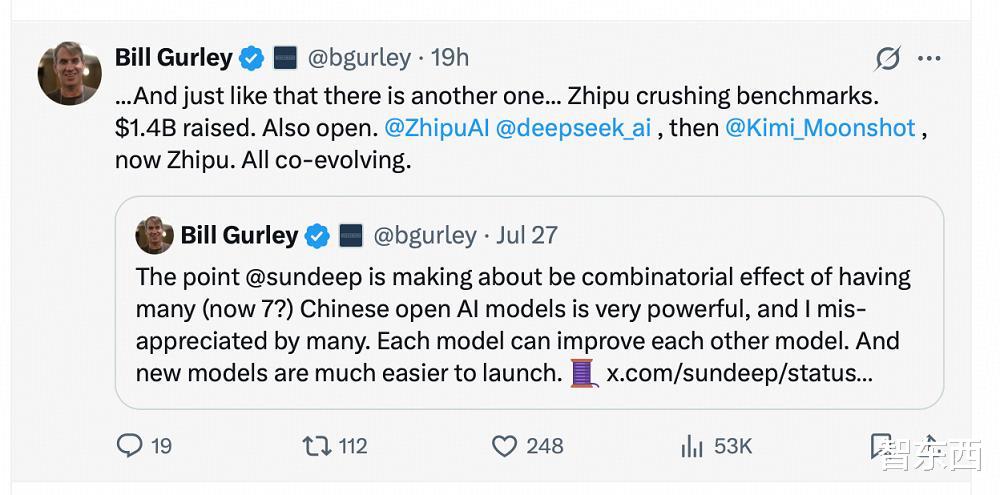
發布后不到48小時 , GLM-4.5已經沖上了HuggingFace趨勢榜第一名 , 成為全球最受關注的開源模型之一 , GLM-4.5-Air則位列第六 。 硅谷BenchmarK風投公司合伙人Bil Gurley發文稱:中國開源AI模型所產生的組合效應非常強大 , 模型之間都可以互相改進 , 新模型的推出也更為容易 。
值得注意的是 , 在WAIC前后 , 中國大模型的開源相繼“出圈” , 月之暗面的K2、阿里的多款模型均有不俗表現 , 之后智譜GLM模型接力 。 就在今天 , Hugging-Face開源模型榜單前10名幾乎全是中國大模型 , CNBC認為 , 中國企業正在研發的人工智能模型不僅智能化水平提升 , 使用成本也持續降低 。
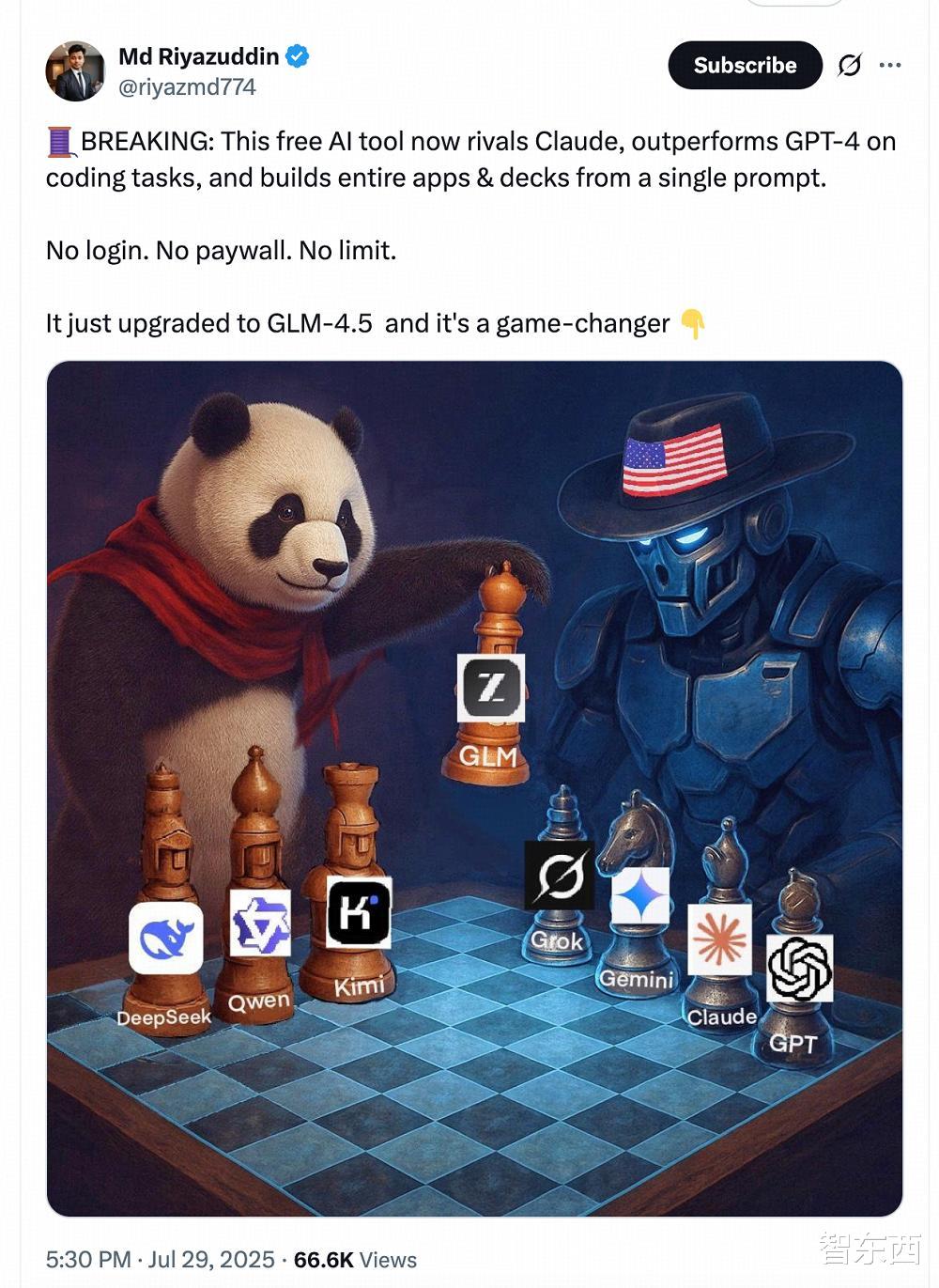
更有一位海外AI博主制作了一張形象的梗圖 , 形容當前AI競爭格局的演變:全球AI大模型現已分裂為以中國模型為代表的開源派 , 與美國模型為代表的閉源派 。 近期 , 繼DeepSeek、Qwen之后 , Kimi、GLM等國產模型也相繼重磅開源 , 給中國開源模型再添猛將 , 仿佛形成了中國AI“開源四杰” , 與國際上的GPT、Claude、Gemini、Grok組成的“閉源四強”分庭抗禮 。
GLM-4.5定位為融合推理、編碼和智能體能力的智能體基座模型 , 在涵蓋推理、編程、智能體等場景的12項基準測試中 , GLM4.5的綜合性能取得了全球開源模型SOTA(即排名第一)、國產模型第一、全球模型第三的成績 。
榜單之外 , 智譜還在真實場景中測試了模型的智能體編程能力 , 平行比較了Claude-4-Sonnet、Kimi-K2、Qwen3-Coder等模型 。 為確保評測透明度 , 智譜公布了上述測試中涉及的全部52道題目及Agent軌跡 , 供業界驗證復現 。 這點也獲得網友們的贊許 。
同時 , 智譜為模型提供了極具性價比的API定價 , API調用價格低至輸入0.8元/百萬tokens、輸出2元/百萬tokens;高速版最高可達100 tokens/秒 。 此外 , 用戶也可在智譜清言和z.ai上免費使用滿血版的GLM-4.5 。
近期 , 智東西已對GLM-4.5的多項能力進行了深度體驗 , 這款模型在實際生產場景中的效用令人驚喜 。
體驗鏈接:
https://chatglm.cn
https://chat.z.ai/
模型倉庫:
https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b
一、GLM-4.5一手實測:一句話打造完整數據庫 , 思考過程簡潔明晰目前 , 已有許多國內外網友上手體驗GLM-4.5模型 , 用它打造AI私人健身教練、生成網頁游戲、3D動畫等 , 其編程能力、完成長序列復雜任務的能力給人留下深刻印象 。
這得益于GLM-4.5本次主打的智能體能力 。 相較于傳統的問答、摘要、翻譯等靜態任務 , 智能體任務對模型提出了更加嚴苛且立體的能力要求 。 集中展現了大模型在感知、記憶、規劃、執行等方面的關鍵要素 , 也為后續多維能力提供了基礎 。
智能體往往面向開放式環境 , 需要模型具備持續感知、長期規劃與自我修正能力 。 同時 , 智能體任務是一種復合流程 , 不僅涉及語言處理能力 , 還要求模型統籌調用工具、執行代碼、操控接口 , 甚至進行多輪交互協作 , 真正考驗模型的綜合調度能力 。 由此可見 , 智能體任務不僅是一種普通的任務形態 , 也可以說是一種“壓力測試” 。
全棧開發便是一種典型的智能體任務 。 為測試相關能力 , 智東西向GLM-4.5提出了一項較為完整的開發任務——使用PHP+MySQL打造一個具有增刪改查功能中英雙語的術語庫 。 這項任務的難點之一在于 , 模型需要自行規劃項目的框架、明晰功能需求、數據庫具體設計等元素 , 如真正的工程師一般全面思考、解決問題 。
智東西也曾將類似的題目交給其他模型 , 不過 , 許多模型都無法對項目框架進行合理規劃 , 甚至選擇在一個網頁文件中開發所有功能 。 因此 , 最終交付的結果無法部署在生產場景 , 更別提進一步修改、擴展了 。
令人驚喜的是 , GLM-4.5交付的結果較為完整 , 實現了既定的功能 , 并且速度較快 , 2分鐘左右便完成了3個核心頁面的開發 , 最終部署的效果如下:
這一結果或許得益于GML-4.5正式開始生成代碼前清晰的思考過程:它準確地判斷了項目性質 , 也明白應該生成哪些文件 , 這為后續的開發提供了明確的指引 。 思考過程也不拖泥帶水 , 看上去簡潔清晰 。
部分對話記錄:
https://chat.z.ai/s/50e0d240-2034-407b-a1b3-94248dd5f449
智譜的官方Demo則展示了GLM-4.5的更多能力 , 例如 , 它可以根據用戶需求 , 準確地復刻YouTube、谷歌、B站等網站的UI界面 , 可用于Demo展示等需求 。
對話記錄:
https://chat.z.ai/s/01079de2-a76d-41ee-b6ee-262ea36c4df7
或是打造一個讓用戶自主設計迷宮 , 系統查找路徑的網頁 。
對話記錄
https://chat.z.ai/s/94bd1761-d1a8-41c9-a2f4-5dacd0af88e9
這種全棧能力不僅能用于實際生產場景 , 拿來整活兒也是不錯的 。 智譜官方打造了一個量子功德箱 , 能實際互動 , 并將數據保存到后臺 。
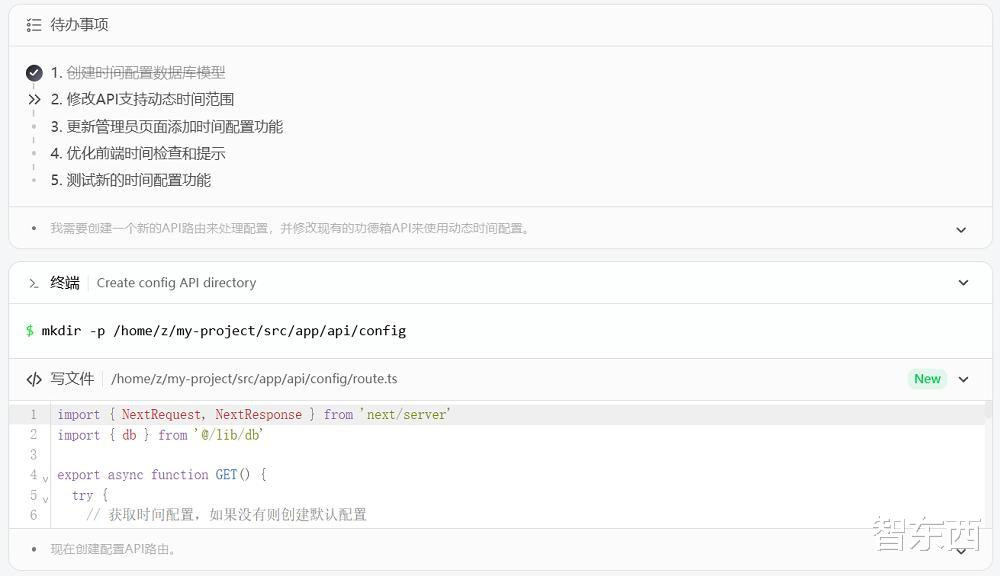
不過 , GML-4.5開發上述項目的過程或許更值得深入探討 。 翻看智能體的執行軌跡 , 可以看到 , 在與開發工具結合后 , GLM-4.5可以更為端到端地完成任務 。 它先是創造了待辦清單 , 然后逐步完成任務 , 總結開發進展 , 并在用戶提出修改意見時 , 進行全面的核查和調試 。
對話記錄:
https://chat.z.ai/s/1914383a-52ac-48b7-9e92-fa105be60f3e
GLM-4.5還在PPT制作這一場景展現出不錯的能力 。 它可以按照用戶指定的頁數、內容等打造完整、美觀的PPT , 并結合搜索工具豐富PPT的視覺體驗 。 例如 , 下圖中 , GLM-4.5為傳奇短跑運動員博爾特打造了一份職業生涯回顧PPT 。
對話記錄:
https://chat.z.ai/s/544d9ac2-e373-4abc-819b-41fa6f293263
我們已經在上述多個案例中直觀感受到了GLM-4.5的能力 。 那么 , 這款模型背后究竟依靠哪些技術創新 , 才能實現如此表現?對此 , 智譜在同期發布的技術博客中給出了答案 。
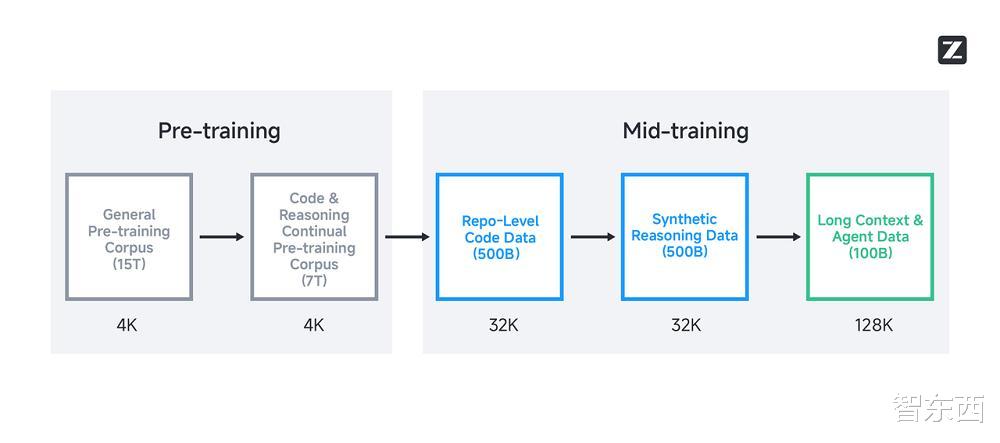
二、參數效率實現突破 , 兼容多款編程智能體GLM-4.5在訓練流程整體分三步走 , 從底層架構、任務選擇到優化策略 , 每一階段逐步推動模型能力提升 。
首先在預訓練階段 , GLM-4.5系列模型借鑒了DeepSeek-V3的MoE架構 , 不過在注意力機制方面仍然使用結合部分旋轉位置編碼(Partial RoPE)的分組查詢注意力(Grouped-Query Attention) 。
這一機制從ChatGLM2沿用至今 , 能規避多頭潛在注意力(MLA)對張量并行處理帶來的挑戰 。 智譜還配置了較多的注意力頭 , 因為該團隊發現 , 增加注意力頭能在推理基準測試中顯著提升模型性能 。
GLM-4.5和GLM-4.5-Air均擁有MTP(多token預測)層 , 讓模型在一次前向計算中 , 同時預測多個后續token 。 實測證明 , 這一機制可顯著加速推理過程 。
進入中期訓練階段后 , 智譜開始針對更復雜、更實用的任務進行專項優化 , 重點強化模型在代碼和推理方面的能力 。
例如 , GLM-4.5針對代碼庫場景進行了專門優化 , 學習了跨文件之間的依賴關系;整合了GitHub上的issues和PR , 進一步提升軟件工程能力;并將訓練序列長度擴展至32K , 從而具備了處理大型代碼庫的能力 。 這正是第一部分案例中 , GLM-4.5能夠自行查驗和修改代碼的能力來源之一 。
為了進一步提升模型處理長上下文的能力 , 智譜將訓練序列的長度從32K進一步擴展到了128K , 并對預訓練語料庫中的長文檔進行了上采樣 , 還在這一階段加入了編程agent的軌跡 。
到了后訓練階段 , GLM-4.5全面引入了強化學習 , 并圍繞高級數學編程推理能力、復雜agentic任務和通用能力這三大關鍵領域 , 展開系統性優化 。
GLM-4.5在后訓練階段的強化學習部分是按照不同任務需求有側重地展開的 。 針對推理任務 , 訓練時引入了按難度遞進的課程學習策略 , 還用動態采樣溫度來控制探索強度 , 并通過基于token 級熵的PPO自適應裁剪機制 , 提升策略更新的穩定性 。
當模型面對的是網頁搜索、代碼生成這類任務時 , 訓練方式轉向了更具agentic特征的RL 。 數據不僅來源于自動流程 , 還引入了人類參與 , 以構建更真實的復雜多步交互場景 。
編程任務則用GitHub 上的真實PR和issues來作為標準 , 訓練中結合準確率獎勵和格式懲罰 , 引導模型學會規范、可靠地行動 。
在更通用的實際應用場景里 , 比如工具調用和長文檔推理 , GLM-4.5又采用了不同策略來補強 。 函數調用任務中 , 使用的是雙軌策略:一部分是基于規則的逐步強化學習 , 確保工具調用準確性;另一部分則是通過獎勵最終任務完成效果的方式 , 引導模型學會自主規劃與調用工具 。
同時 , 為了讓模型更好地理解和利用長文本 , 智譜也安排了一個專門的長上下文RL階段 , 讓GLM-4.5在處理大規模文檔時具備更強的推理能力 。
總體來看 , GLM-4.5的整個訓練過程是高度工程化的:架構上通過MoE提升計算效率 , 訓練流程中針對關鍵任務進行能力注入 , 強化學習階段進一步拉高模型的推理上限和實用表現 , 最終實現推理、編碼和智能體能力的原生融合 。
也正是由于在工具調用、網頁瀏覽、軟件工程、前端編程等領域的優化 , GLM-4.5系列模型與Claude Code、Cline、Roo Code等主流編程智能體實現了完美兼容 , 也可以通過工具調用接口支持任意的智能體應用 。
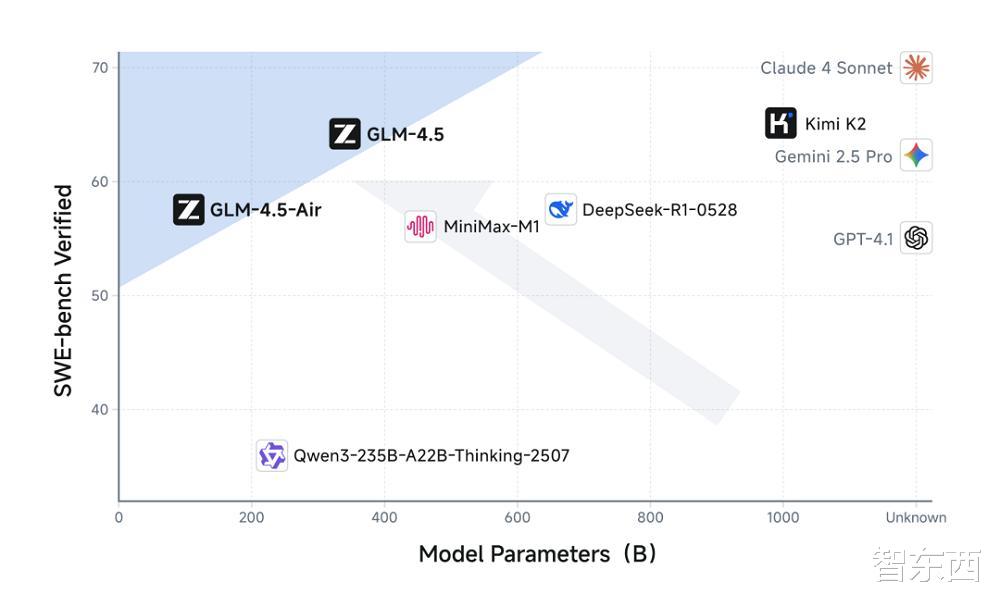
值得注意的是 , GLM-4.5還展現出更高的參數效率 , 參數量為DeepSeek-R1 的 1/2、Kimi-K2的 1/3 , 但在多項標準基準測試中表現得更為出色 。 在衡量模型編程能力的SWE-bench Verified榜單上 , GLM-4.5系列位于性能/參數比帕累托前沿 , 表明在相同規模下GLM-4.5系列實現了最佳性能 。
高參數效率代表了模型架構和訓練策略的有效性 , 即在更少的參數下學到了更多、更有用的能力 , 這也意味著 , 在同等算力預算下 , GLM-4.5能實現更高的性價比 。
結語:開源大模型突圍 , 智能體賽道迎來“平替”時代?當前 , 以智能體為標簽的AI產品層出不窮 , 數量龐雜 , 卻鮮少有產品能真正獲得用戶的長期使用和信賴 。 這在一定程度上也是所有AI產品的共性問題 , 要解決這一問題 , 除了進一步打磨用戶體驗之外 , 底層模型能力的提升也至關重要 。
【又一國產旗艦模型開源,海外網友:中國AI開源四巨頭已成】隨著Claude、GPT等海外大模型的獲取越來越困難且價格愈發昂貴 , 國產開源模型正為開發者提供更高效的本土化解決方案 。
推薦閱讀













- 加碼小屏!下個月就來的小米16系列,可能有兩款6.3小屏旗艦
- 河北移動攜中興GoldenDB完成CRM域能力開放平臺數據庫國產化改造
- 千元平板天花板!旗艦芯+3.2K超清LCD屏,聯想推出小新平板Pro GT
- 三星新旗艦 Exynos 2600 將搭載 HPB 散熱技術
- 又一家要做游戲手機,但是不是手機品牌,而是一個掌機品牌
- 國產視頻生成再突破!從影視級短片到遠洋親情連線,AI讓天涯變咫尺
- 紅米Note15系列再次被確認:小長焦+滿級防水,外圍體驗直逼旗艦
- 鑲鉆小折疊,讓我們想起了國產手機的“至暗時刻”
- 全國產智能體MasterAgent:一句話造專屬AI團隊,專業協同交付
- 美國麻煩了,中國CPU國產率超20%,GPU國產率超30%了