文章圖片
頭圖來源:視覺中國
7月28日晚間 , 智譜發布了其新一代旗艦模型GLM-4.5 。
與早期追求參數規模的競賽不同 , GLM-4.5的發布重點突出地體現在三個方面:明確面向智能體(Agent)應用的設計、通過技術優化實現的高性價比 , 以及全面擁抱開源和開發者生態的戰略布局 。
之前在今年4月 , 智譜就發布了「AutoGLM沉思」——一個能探究開放式問題 , 并根據結果執行操作的自主智能體 。 今天GLM-4.5的推出 , 不僅是智譜自身模型矩陣的一次升級 , 也從一個側面反映出AI行業發展的趨勢性變化:模型的價值正在進一步加速向解決實際問題、降低應用門檻的方向遷移 。
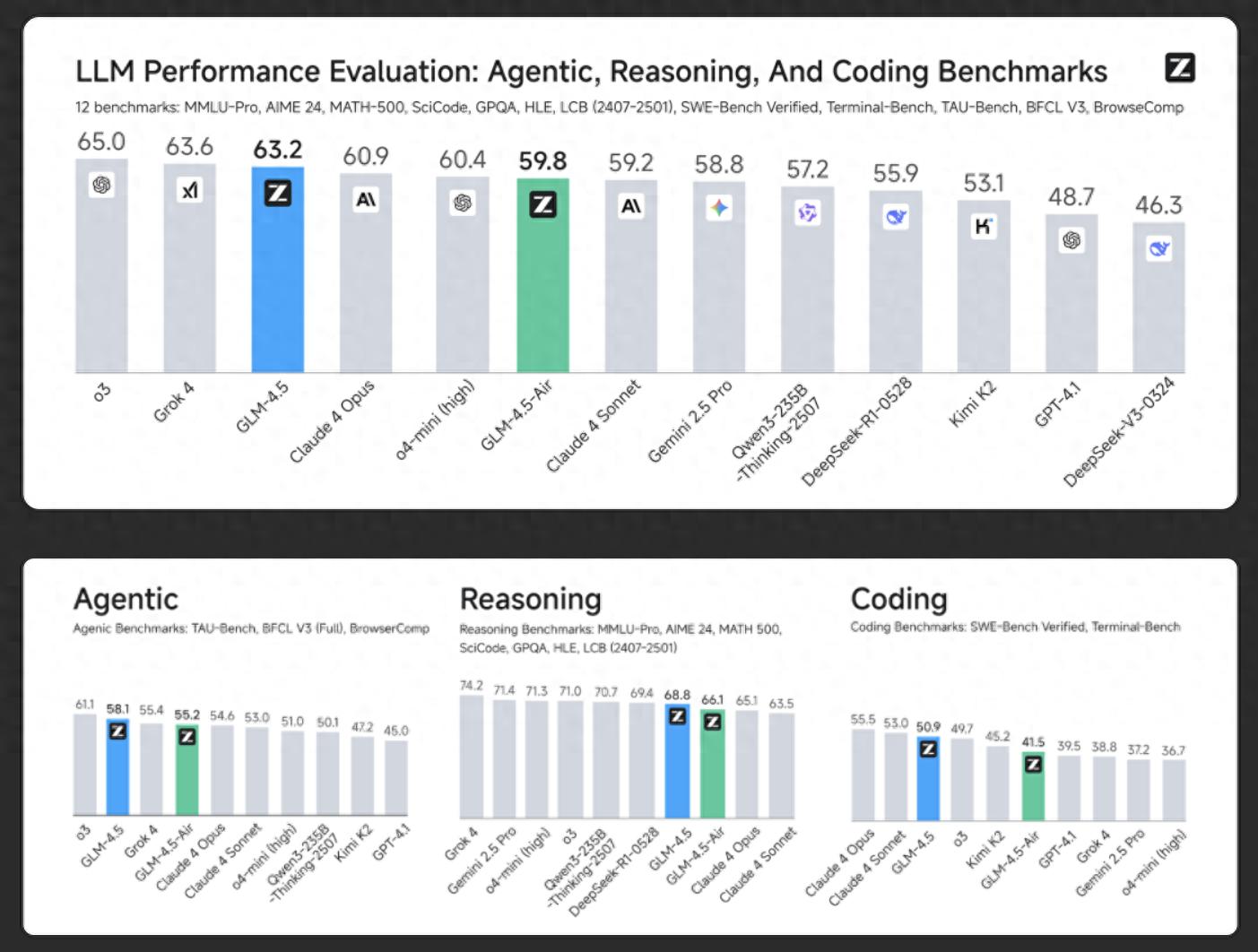
為「智能體」而生的模型設計衡量一個大模型的優劣 , 綜合能力基準評測是業內的通行做法 。 智譜此次公布了GLM-4.5在一系列評測集上的表現 。 這份評測涵蓋了推理、代碼、科學、智能體等12個不同維度的基準測試 , 旨在全面評估模型的綜合素質 。
根據智譜提供的數據 , GLM-4.5在這些測試中的綜合得分位列全球參評模型的第三位 , 在開源模型中排名第一 。
圖片來源:智譜
優秀的評測成績是模型能力的基礎 , 但更值得關注的是其背后的設計理念 。 GLM-4.5從一開始就將目標鎖定在「智能體應用」 。 智能體要求模型具備任務理解、規劃分解、工具調用和執行反饋等一系列復雜能力 , 這超出了傳統聊天機器人的范疇 。
智譜將「在不損失原有能力的前提下融合更多通用智能能力」作為其對AGI的理解 , 而GLM-4.5正是這一理念的實踐 。
為了支撐智能體所需的強大而靈活的能力 , GLM-4.5在技術架構上做出了針對性的選擇:
【智譜發布新一代基座模型GLM-4.5:開源、高效、低價,專為智能體而生】
混合專家(MoE)架構:GLM-4.5采用了MoE架構 , 總參數量達到3550億 , 而單次推理中被激活的參數量為320億 。 這種架構允許模型在保持巨大知識儲備和能力上限的同時 , 能根據具體任務 , 只調用部分「專家」網絡進行計算 。 其直接好處是在保證高質量輸出的前提下 , 有效控制了推理成本和能耗 , 為大規模應用部署提供了可行性 。雙模式運行:模型被設計為兩種工作模式——「思考模式」和「非思考模式」 。 「思考模式」為復雜的推理和工具調用任務設計 , 允許模型投入更多計算資源進行深度規劃;「非思考模式」則服務于需要快速響應的場景 。 這種設計兼顧了智能體在執行復雜任務時的「深度」與日常交互時的「速度」 , 是對實際應用場景需求的細致考量 。針對性數據訓練:模型的訓練過程也體現了其應用導向 。 在15萬億token的通用數據預訓練之后 , 團隊使用了8萬億token的高質量數據 , 在代碼、推理、智能體等領域進行了針對性訓練 , 并通過強化學習進行能力對齊 。 這種「通識教育+專業深造」的訓練路徑 , 旨在讓模型不僅知識淵博 , 更在特定專業領域具備解決實際問題的能力 。綜合來看 , GLM-4.5并非一個泛泛的通用模型 , 其技術選型和訓練策略都清晰地指向了構建高效、可靠的AI智能體這一具體目標 , 這也反映了智譜對大模型下一階段應用形態的判斷 。成本、效率與生態的商業邏輯 性能是技術層面的核心 , 而成本和生態則是決定一項技術能否被市場廣泛接納的關鍵 。 GLM-4.5在此次發布中 , 展現了清晰的商業邏輯 。首先是參數效率帶來的成本優勢 。「參數效率」是評估模型訓練水平和架構設計的重要指標 , 即用相對更少的計算資源實現同等或更優的性能 。 智譜方面的數據顯示 , GLM-4.5的參數量顯著低于部分業界同類模型 , 但在多項基準測試中表現更佳 。 在代碼能力榜單SWE-bench Verified上 , 其性能與參數量的比值處于帕累托前沿 , 這證明了其較高的訓練和推理效率 。更高的效率直接轉化為更低的部署和使用成本 。 此次公布的API定價——輸入0.8元/百萬tokens , 輸出2元/百萬tokens——顯著低于當前市場主流閉源模型的定價水平 。 配合高速版可達100 tokens/秒的生成速度 , GLM-4.5為開發者提供了一個兼具高性能和低成本的選擇 。圖片來源:智譜 其次是降低門檻、構建開發者生態的戰略意圖 。低廉的價格并非目的 , 而是吸引開發者、繁榮生態的手段 。 AI應用的普及 , 根本上依賴于開發者社區的創造力 。 高昂的API費用一直是阻礙許多中小型團隊和個人開發者進行創新的主要障礙之一 。 通過大幅降低價格 , 能夠降低AI應用的開發門檻 , 激發更廣泛的創新 。在生態構建上 , 智譜采取了務實的策略 。 例如 , GLM-4.5的API被設計為可以兼容主流的Claude Code框架 。 這一舉措使得已經熟悉該框架的開發者能夠以極低的成本將工作流遷移至GLM-4.5 , 有效減少了技術選型和切換的阻力 。此外 , 將模型權重在Hugging Face和ModelScope等平臺遵循MIT License進行開源 , 也體現了其開放的姿態 。 MIT License對商業使用限制極少 , 這為企業和個人基于GLM-4.5進行二次開發和商業化應用鋪平了道路 。通過「高參數效率」實現「低使用成本」 , 再以「低成本」和「高兼容性」吸引開發者 , 從而構建起一個活躍的應用生態——這是一條清晰且務實的商業路徑 。從功能演示到實際應用的距離 但衡量一個模型最終價值的 , 仍然是它在真實世界中的表現 。智譜此次展示了多個基于GLM-4.5原生能力構建的應用案例 , 如可交互的搜索引擎、社交媒體網站 , 以及Flappy Bird小游戲等 。這些案例證明 , GLM-4.5 模型已經具備了相當程度的全棧開發和工具調用能力 , 能夠理解需求并自主生成可運行、可交互的應用程序 。這些演示作為技術能力的驗證是成功的 , 它們展示了GLM-4.5在智能體方向上的潛力 。 不過從功能演示到穩定可靠的生產級應用 , 仍然存在一段距離 。在智譜自己公布的真實場景對比測試中 , 這一點也得到了反映 。 測試結果顯示 , GLM-4.5在編程任務中的表現優于其他參評的開源模型 , 尤其在工具調用的可靠性方面 。 但報告也同時指出 , 與頂尖的閉源模型Claude-4-Sonnet相比 , GLM-4.5在提供近似效果的同時 , 仍存在一定的提升空間 。這種對比是對當前AI技術發展的普遍現狀的一種反應:頂尖的開源模型正在快速追趕 , 但在部分能力上與最前沿的閉源模型相比 , 尚有差距 。智能體在開放環境中的穩定性、對模糊指令的理解能力、以及在遭遇未知情況時的糾錯和適應能力 , 都是決定其真正成為「可靠的工具」的核心挑戰 。智譜此次選擇公開評測題目和Agent軌跡 , 邀請行業共同驗證和改進 , 也體現了一種積極和開放的態度 。GLM-4.5的發布 , 沒有將重點放在參數規模的數字上 , 而是聚焦于智能體這一明確的應用方向 , 并通過技術優化和商業策略 , 為開發者社區提供了一個高性價比的基礎平臺 。大模型行業正進入更加注重實際應用 , 更加注重成本效益 , 也更加注重開發者生態建設的階段 。接下來 , GLM-4.5的市場表現 , 以及在其之上能誕生出多少創新的AI原生應用 , 將是檢驗其最終成功與否的關鍵 。
推薦閱讀











- 魅族新一代旗艦機官宣:8月份,正式發布
- 榮耀新機即將預熱:全新小折疊屏,8月發布
- 新驍龍提前發布 四大國產旗艦超前預熱 最快國慶開售?
- 本月,榮耀多形態新機待發布
- 小米16系列再次被確認:Pro Max規格已清晰,或分批發布!
- AYANEO發布NEXT 2游戲掌機:引入發燒本同款銳龍AI Max+處理器
- 999元,小米又發布新機,這次主打學習!
- DJI Osmo 360發布!大疆全景相機一鳴驚人,全靠生態強大?
- 華為舍棄高利潤!發布三個月降至2826元,鴻蒙OS+5500mAh+100W
- 小米16 Ultra配置爆料匯總:1.5K直屏+連續光變,預計12月發布