
文章圖片

文章圖片
【AI推理時代來臨,云天勵飛攜“算力積木”架構破解國產化難題】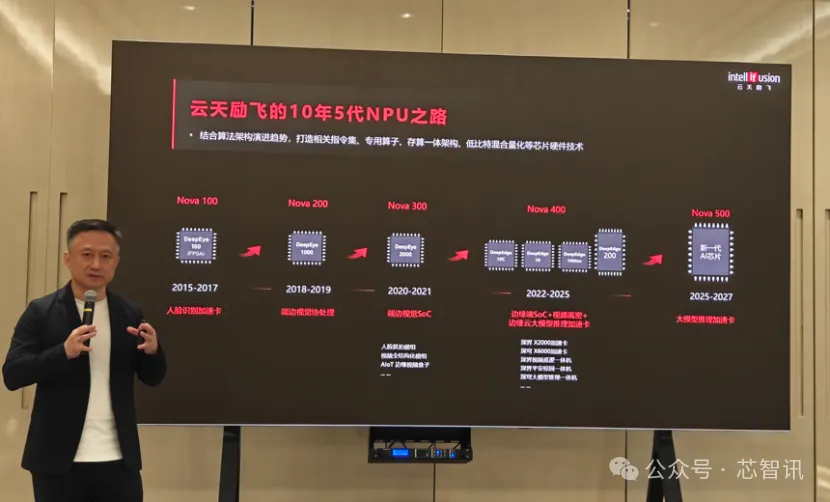
文章圖片

文章圖片
近日 , 云天勵飛召開了主題為“智能芯生·推理未來”的媒體溝通會 , 正式宣布未來將全面聚焦人工智能(AI)推理芯片 , 并將圍繞邊緣計算、云端大模型推理、具身智能三大核心布局 , 打造國產AI推理“加速器” 。
“第四次工業革命”來襲 , AI推理芯片將是“鑰匙”
2022年底 , 隨著OpenAI的生成式AI應用ChatGPT的發布 , 正式開啟了生成式AI的元年 。 ChatGPT其憑借大語言模型(LLM)的加持 , 展現出卓越的AI體驗 , 引發了全球的關注 。 隨后 , 各類大模型技術也開始呈現爆發式的發展 , 技術迭代周期從“三到五年”縮短至“三個月” 。 在此背景之下 , 業界也普遍預期 , 到2030年通用人工智能(AGI)將會實現 。
云天勵飛董事長兼CEO陳寧認為 , 隨著2030年AGI的實現 , 這將成為“第四次工業革命”開始的一個標志性里程碑的時間點 。 而AGI的實現離不開大算力AI芯片的加持 , 同樣中國的人工智能產業能否抓住這樣一個歷史機遇 , 關鍵也是在AI大算力芯片 。 這也是為什么過去五年來全球科技競爭都聚焦在AI大算力芯片領域的原因 。
過去多年來 , AI大模型技術的發展主要是依賴于英偉達的GPU來進行訓練 。 但是隨著AI大模型技術的逐漸成熟 , 模型調用成本顯著降低 , AI技術的發展也開始由訓練階段轉向以應用為導向的推理階段 , 特別是隨著端側及邊緣算力的提升 , 面向推理應用的AI智能體(Agent)開始在端側及邊緣加速落地 , 賦能千行百業 。
陳寧指出:“我們正在由AI訓練時代進入到AI推理時代(以Deepseek開源等為標志) 。 如果說AI訓練是‘發電’ , 那么AI推理就是‘用電’ 。 AI推理時代意味著AI應用普惠化、無處不在(Agent成本極大降低) , 人人將擁抱AI 。 ”
在陳寧看來 , 隨著“AI推理時代”的到來 , 中國人工智能產業也將迎來兩大機遇:未來五年 , 以AI大模型、算法和推理芯片為核心的AI技術重新定義所有電子產品;未來五到十年 , 全球將會構建一張無處不在的低成本、高效率的AI推理算力網絡 。 而要抓住這兩大機遇 , 那么就離不開AI推理芯片的支撐 。
11年五代NPU三大SoC系列 , 全面聚焦AI推理需求
成立于2014 年的云天勵飛 , 一開始就聚焦于通過自研的 NPU(神經網絡處理器) 來降低 AI 算法計算成本 , 并且當時還用 NPU 課題申報了政府的人才引進項目 , 并且獲得了第一名 , 得到了研發資金的支持 。 可以說 , 芯片技術 , 正是云天勵飛初期獲得投資的關鍵 。
云天勵飛的NPU內核是基于自研指令集架構 , 能夠深入匹配特定應用場景 , 并在指令層面實現更高效的優化 。 這種深度定制使NPU內核在性能、功耗與面積之間實現更優權衡 , 從而以合理成本推動AI芯片廣泛落地 , 真正發揮出場景中的最優效能 。
經過11年發展 , 云天勵飛陸續推出了五代NPU(最新的是Nova 500) 。 從Nova 100只支持簡單的CNN算法 , 迭代到2022年研發的Nova400就前瞻性布局了高效的Transformer計算范式 。 目前正在研發的Nova500 , 目標是可以高效支持萬億級參數的大模型以及面向具身智能的端到端的運動大模型 。
與此同時 , 云天勵飛還針對邊緣推理場景(深界系列芯片)、大模型推理場景(深穹系列芯片)、具身智能場景(深擎系列芯片)推出了融合其NPU內核的三大SoC系列芯片平臺 。
“我們花了10年時間沉淀了一個豐富的產品矩陣 , 從IP、軟件棧、天書多模態大模型 , 再到以算法的基礎的AI推理芯片平臺 , 以及基于這些芯片的一系列設備 。 還有一系列面向智慧城市、智慧商業、智慧交通等應用的解決方案 。 ”陳寧還特別舉例道 , 去年初收購的智能穿戴設備IDH公司岍丞技術 , 在云天勵飛的NPU IP技術加持下 , 去年無線藍牙耳機的銷量突破了3000萬部 , 占中國的無線藍牙耳機市場的35%份額 。
得益于在AI推理芯片及相關產品矩陣上的持續投入 , 云天勵飛的業績也實現了快速增長 。 財報顯示 , 云天勵飛2024年營業收入超9億元 , 同比增長81.3% 。 2025年第一季度營收2.64億元 , 同比增長168.23% 。 “基于AI推理算力需求的增長 , 相信下半年會繼續保持高速增長的態勢 。 ”陳寧說道 。
首創“算力積木”架構 , 實現大算力AI推理芯片國產化
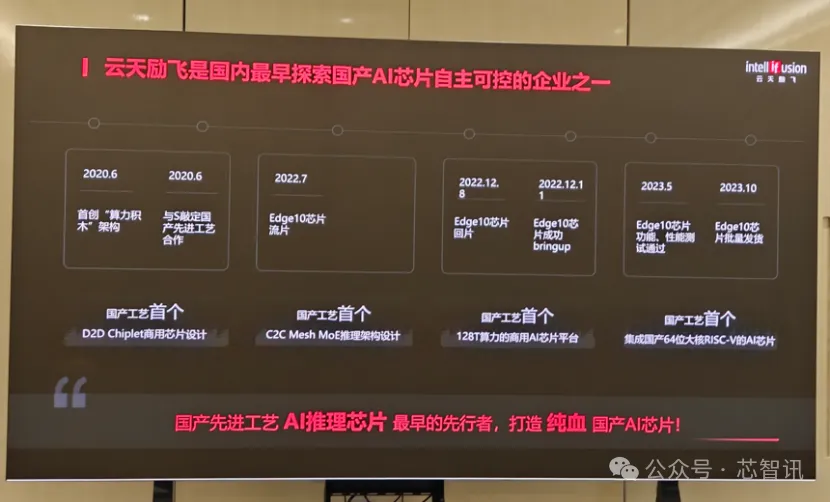
需要指出的是 , 在2020年 , 云天勵飛被美國列入了實體清單 , 這也迫使云天勵飛開始全面轉向了國產化供應鏈 , 成為了國內最早探索國產AI芯片自主可控的企業之一 。
云天勵飛CTO李愛軍告訴芯智訊:“2020年之時 , 國產的先進制程工藝并不成熟 , 絕大多數的芯片設計公司首選的一定不是國產工藝 。 但是我們當時就做了一個戰略性決定 , 全面切回國產工藝 , 跟國產工藝一起發展和迭代 。 為此 , 云天勵飛還首創了‘算力積木’ , 來解決單個大算力AI芯片的良率和成本問題 。 ”
所謂“算力積木”架構 , 簡單來說 , 就是在現有國產先進制程工藝的前提下 , 將原本基于國外更先進制程就能實現一顆單芯片的大算力AI芯片 , 拆分成多個小算力芯粒 , 然后利用現有的國產先進制程工藝來進行生產 , 以解決單個大算力AI芯片的良率和成本問題 。 之后再根據具體應用的算力需求 , 通過“搭積木”的方式 , 將小算力芯粒通過D2D(Die to Die)“Chiplet”的方式組合成一個大的AI芯片 , 來實現更大的算力 。 如果需要更高的AI算力 , 則還可以通過C2C(Chip to Chip) Mesh Torus 互連技術 , 將多個由小算力芯粒組合成的大算力AI芯片進一步互聯成一個計算集群 。
李愛軍解釋道:“我們選擇‘算力積木’的架構來規避當時國產工藝限制、密度的限制 , 通過D2D Chiplet技術實現了單個封裝內集成8個‘積木’ , 實現128T的大算力 。 另外通過C2C Mesh技術 , 可以形成一個更大規模的算力池 , 足以滿足千億級參數的MOE架構大模型的高效的推理 。 ”
為便于“算力積木”的小算力芯粒能輕松實現模塊化擴展與任務并行 , 云天勵飛還自研軟件棧和工具鏈 , 在算力調度、成本控制和封裝靈活性方面實現突破 。 使得該架構不僅支持一次設計、多種封裝 , 也顯著提升了芯片的適配效率與產品迭代速度 。
云天勵飛2023年正式發布的DeepEdge10系列芯片平臺 , 就是基于“算力積木”架構打造的 , 算力范圍覆蓋 8T 至 256T , 可實現7B、14B、130B、671B 等不同參數量大模型的高效推理 , 賦能各類智算推理硬件產品 。 目前 , DeepEdge10系列芯片平臺已成功適配DeepSeek R1系列模型、國產鴻蒙操作系統以及QwQ-32B模型 , 可為客戶提供全國產的軟硬一體化產品和解決方案 。
“目前我們的DeepEdge10和DeepEdge10Max是市面上性能和性價比最高的、能夠承載3B、7B、14B多模態大模型的單芯片SoC 。 ”李愛軍非常有信心地說道 。
另據李愛軍介紹 , 目前云天勵飛的DeepEdge10芯片平臺已經通過了自主可控國產化C級認證 , 板級方案通過100%國產化率驗證 。
小結:
正如前文所述 , 隨著AI的發展開始由“AI訓練時代”轉向“AI推理”時代 , AI推理芯片正在成為推動 AI 應用規模化部署的核心動力 。
雖然在“AI訓練”時代 , 英偉達憑借CUDA生態構筑了極高的生態壁壘 , 疊加美西方對中國半導體產業的限制 , 使得國產替代困難重重 。 但是 , AI推理場景更加的碎片化(端側/邊緣/云) , 不僅需要結合應用場景進行定制性優化 , 更需要有足夠的性價比 , 并且這一領域尚未形成一個足夠強大的生態壁壘 , 這也給國產廠商帶來了差異化競爭的機遇 。
在此背景下 , 云天勵飛從一開始就選擇繞開投入巨大且壁壘深厚的傳統的AI訓練戰場 , 集中有限力量持續聚焦未來更廣闊的AI推理市場進行創新可謂是明智之舉 。
憑借多年來在NPU領域的技術積累和“算力積木”架構創新 , 云天勵飛成功破解了國產先進制程薄弱所帶來的對于大算力AI推理芯片的瓶頸 , 堪稱國產替代的最優工程路徑 。 與此同時 , 云天勵飛長期聚焦邊緣計算、云端大模型推理加速以及具身智能等領域的持續深耕 , 也成功構建了一個涵蓋‘高性能、低成本、強適配’三大優勢的國產 AI 推理芯片與產品體系 。
“我們致力于成為中國 AI 推理芯片的領軍企業 , 打造面向 AI 大模型時代的關鍵‘加速器’ , 通過高性價比國產算力 , 推動人工智能在各類場景中的規模落地與快速發展 。 ”陳寧總結說道 。
編輯:芯智訊-浪客劍
推薦閱讀













- Zoom團隊:AI推理新突破提升ChatGPT效率80%
- 思維鏈監督和強化的圖表推理,7B模型媲美閉源大尺寸模型
- 馴服復雜表格:九天重磅開源,開啟「人與表格對話」智能新時代
- 華為吳輝:以服務升維破解數智化轉型矛盾,構建AI時代體系護城河
- VLA-OS:NUS邵林團隊探究機器人VLA做任務推理的秘密
- 英偉達全新開源模型:三倍吞吐、單卡可跑,還拿下推理SOTA
- SPIRAL:零和游戲自對弈成為語言模型推理訓練的「免費午餐」
- 用說的就能做 App,這家公司想做 AI 時代的 ins
- WAIC 2025觀察 | “沖上去”的超聚變,如何做智能體時代的探索者?
- 萬億美元新大陸!誰將主宰「人機共生」智能體經濟時代?