
文章圖片

文章圖片

文章圖片
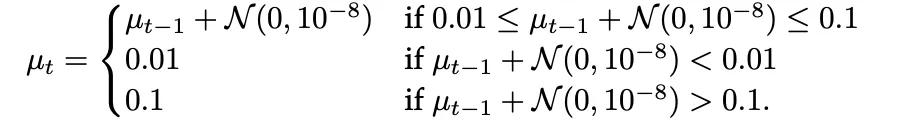
文章圖片
機器之心報道
編輯:冷貓
不知道大家是否還記得 , 人工智能先驅、強化學習之父、圖靈獎獲得者 Richard S. Sutton , 在一個多月前的演講 。
Sutton 認為 , LLM 現在學習人類數據的知識已經接近極限 , 依靠「模仿人類」很難再有創新 。
未來人工智能的發展需要從經驗中學習 , 而這一路徑始終是「強化學習」 。
這也是 Sutton 一以貫之的觀點 , 不論是過去的文章《苦澀的教訓(Bitter Lesson)》還是近期的研究工作 , 都能夠顯示出這位 AI 領域的核心人物 , 對于建立一個簡單通用的 , 面向下一個「經驗時代」的強化學習算法的熱情 。
近些天 , Sutton 再發新論文 , 在強化學習領域再次發力 , 將他在 2024 年的時序差分學習新算法 SwiftTD 拓展到控制領域 , 在與一些更強大的預處理算法結合使用時 , 能夠展現出與深度強化學習算法相當的性能表現 。
【圖靈獎得主Sutton再突破:強化學習在控制問題上媲美深度強化學習】
論文標題:Swift-Sarsa: Fast and Robust Linear Control 論文鏈接:https://arxiv.org/abs/2507.19539v1
Sutton 在 2024 年提出了一種用于時序差分(TD)學習的新算法 ——SwiftTD 。 該算法在 True Online TD (λ) 的基礎上進行了增強 , 融合了步長優化、對有效學習率的約束以及步長衰減機制 。 在實驗中 , SwiftTD 在多個源自 Atari 游戲的預測任務中均優于 True Online TD (λ) 和傳統的 TD (λ) , 且對超參數的選擇具有較強的魯棒性 。
在這篇論文中 , 作者將 SwiftTD 的核心思想與 True Online Sarsa (λ) 相結合 , 提出了一種基于策略的強化學習算法 ——Swift-Sarsa 。
此外 , 還提出了一個用于線性基于策略控制的簡單基準測試環境 , 稱為「操作性條件反射基準」(operant conditioning benchmark) 。
Swift-Sarsa
SwiftTD 能夠比以往的 TD 學習算法更準確地學習預測值 。 使其具備更優預測能力的核心思想 , 同樣也可以應用于控制算法中 。 將 SwiftTD 的關鍵思想與 True Online Sarsa (λ)(Van Seijen 等 , 2016)結合 , 是將其應用于控制問題最直接的方式 。
在控制問題中 , 智能體在每一個時間步的輸出是一個具有 d 個分量的向量 。 Swift-Sarsa 限于動作數量離散的問題 。 如果動作向量的每個分量只能取有限個數值 , 那么整個動作空間就可以表示為一個有限的離散動作集合 。
策略函數可以是任意函數 , 通常會被設計為:價值越高的動作被選擇的概率越大 。 兩種常用策略是:
1. ?- 貪婪策略(?-greedy policy):以 1 - ? 的概率選擇具有最高價值的動作 , 以 ? 的概率隨機選擇一個動作;
2. Softmax 策略:將動作價值轉化為離散概率分布 。
關于 SwiftTD 算法 , 請參閱論文:
論文標題:SwiftTD: A Fast and Robust Algorithm for Temporal Difference Learning 論文鏈接:https://openreview.net/pdf?id=JdvFna9ZRF
操作性條件反射基準測試
作者設計了一個名為操作性條件反射基準(operant conditioning benchmark)的測試基準 , 用于評估 Swift-Sarsa 的性能 。
該基準定義了一組控制問題 , 這些問題不需要復雜的探索策略 , 隨機策略也能偶爾選擇到最佳動作 。 這些問題的最優策略可以由線性學習器表示 。
在該基準中的問題里 , 觀測向量由 n 個二值分量組成 , 動作向量由 d 個二值分量組成 。 n 和 d 是超參數 , 只要 nd , 它們的任意組合都定義了一個有效的控制問題 。
在某些特定的時間步 , 觀測向量的前 m 個分量中恰好有一個為 1 , 其余時間步則全部為 0 。 當前 m 個分量中的第 i 個在某個時間步為 1 時 , 若智能體選擇的動作向量中第 i 個分量為 1 且其余分量為 0 , 則該智能體將在之后獲得一個延遲獎勵 。 該獎勵延遲 k_1 個時間步 , 其中 k_1 是一個變量 , 每次智能體選擇該獎勵動作時從區間 (ISI_1 ISI_2) 中均勻采樣 。 在所有其他時間步 , 獎勵為 0 。
每隔 k_2 個時間步 , 觀測向量的前 m 個分量中會隨機有一個被置為 1 , 其中 k_2 是一個變量 , 每次從區間 (ITI_1 ITI_2) 中均勻采樣 。
在每一個時間步 , 觀測向量中其余 n ? m 個分量中每一個以概率 μ_t 被置為 1 。 初始時 μ_1 = 0.05 , 之后按如下規則遞歸更新 。
操作性條件反射基準的靈感來源于 Rafiee 等人(2023)提出的動物學習基準 。 動物學習基準的設計靈感來自行為主義者在動物身上進行的經典條件反射實驗 , 而操作性條件反射基準則是受到了操作性條件反射實驗的啟發 。 兩者的關鍵區別在于:
在操作性條件反射實驗中 , 動物所選擇的行為會影響獎勵的出現頻率; 而在經典條件反射實驗中 , 動物無法控制獎勵的出現 , 只能學習去預測即將到來的獎勵(如巴甫洛夫的狗實驗) 。
實驗結果
本論文在操作性條件反射基準上針對不同的 n 值對 Swift-Sarsa 進行了實驗 。
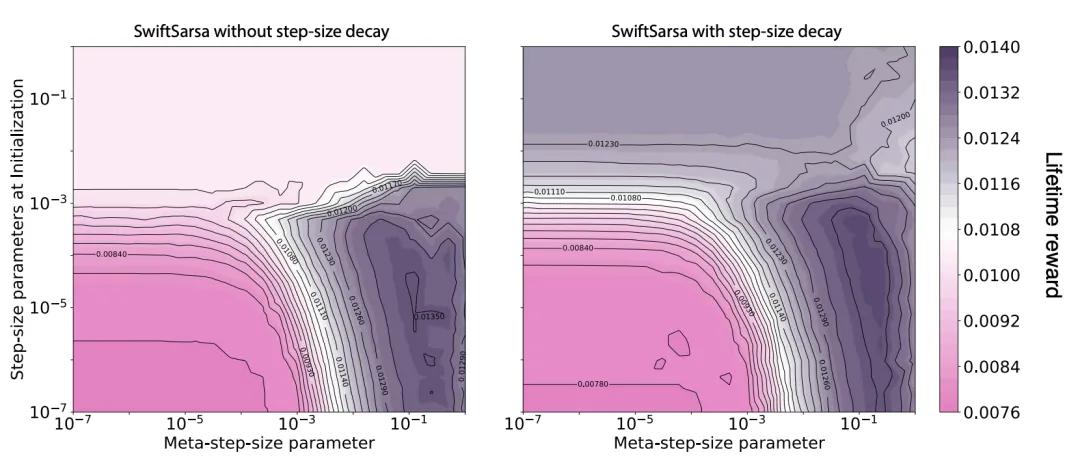
圖 1 展示了在兩種不同 n 值下 , 元步長參數(meta-step-size)和初始步長參數對平均獎勵的影響 。 類似于 SwiftTD 的表現 , Swift-Sarsa 的性能隨著元步長參數的增大而提升 , 表明步長優化帶來了明顯的好處 。 在較寬的參數范圍內 , Swift-Sarsa 實現的生命周期獎勵接近最優生命周期獎勵(約為 0.014) 。 當干擾特征數量增加時 , 問題變得更具挑戰性 , Swift-Sarsa 的表現也隨之下降 。
在第二組實驗中 , 我們比較了步長衰減(step-size decay)對 Swift-Sarsa 性能的影響 , 結果如圖 2 所示 。 與其在 SwiftTD 中的作用類似 , 當初始步長參數設置過大時 , 步長衰減能夠提升 Swift-Sarsa 的性能 。
值得注意的是 , 若將 Swift-Sarsa 與更強大的預處理方法結合使用 , 它在更復雜的問題上(如 Atari 游戲)可能也能達到與深度強化學習算法相當的性能水平 。
更多信息 , 請參閱原論文 。
推薦閱讀















- 三星T9 USB3.2移動固態硬盤榮獲2025年第十屆ChinaJoy黑金獎
- DeepSeek創始人梁文鋒:拿下國際頂會最佳論文獎!
- 韶音OpenDots ONE斬獲2025CJ黑金獎,引領開放聆聽新風尚
- 佳能EOS R50V榮獲2025年第十屆ChinaJoy黑金獎
- 聯想拯救者Y9000P至尊版 AI元啟榮獲2025年第十屆ChinaJoy黑金獎
- 雷柏VT3s雙模無線電競鼠標榮獲2025年第十屆ChinaJoy黑金獎
- 泰坦軍團G27T8M榮獲2025年第十屆ChinaJoy黑金獎
- 圖靈獎得主加持,蒙特卡洛樹搜索×擴散模型殺回規劃賽道
- 顯卡大獎相送!映眾攜手HKC閃耀2025 ChinaJoy
- 中興通訊聯合合作伙伴斬獲2025世界人工智能大會SAIL獎