
文章圖片

文章圖片
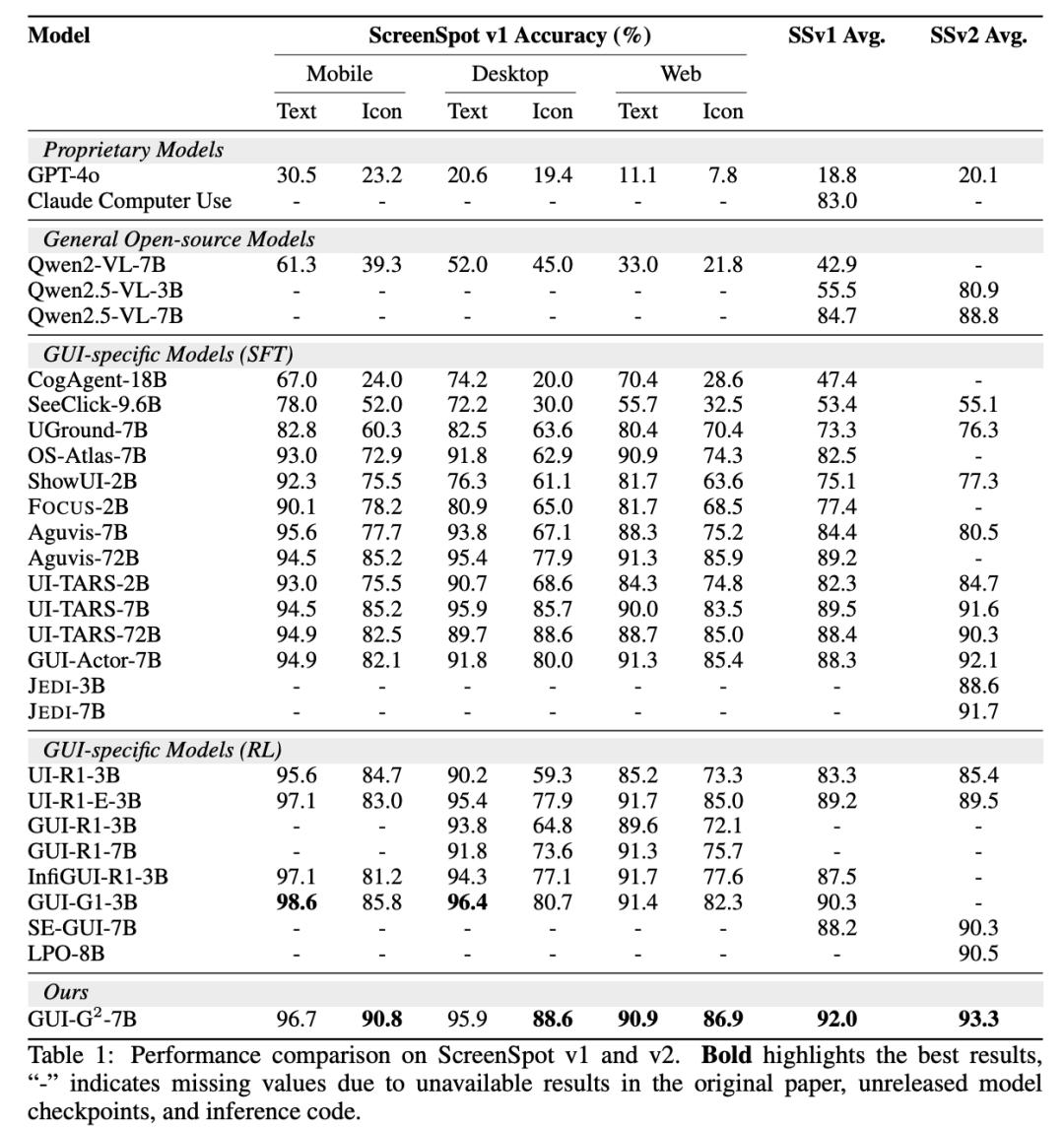
文章圖片

文章圖片
本文第一作者唐飛 , 浙江大學碩士生 , 研究方向是 GUI Agent、多模態推理等 。 本文通訊作者沈永亮 , 浙江大學百人計劃研究員 , 博士生導師 , 研究方向包括大模型推理、多模態大模型、智能體等 。
1. 研究背景和方法亮點
在人工智能飛速發展的今天 , GUI 智能體(GUI Agent)正在成為下一個技術風口 。 這些 \"數字助手\" 能夠像人類一樣 , 通過自然語言指令自動操控電腦、手機等設備界面 , 從發郵件到編輯文檔 , 幾乎無所不能 。 想象一下 , 你只需說一句 \"幫我在地圖上添加個標記\" , AI 就能自動找到按鈕并完成操作 —— 這就是 GUI 智能體的魅力所在 。
但要實現這一切 , 有一個關鍵技術環節不能忽視:GUI Grounding(圖形界面定位) 。 這是 GUI 智能體的 \"眼睛\" 和 \"手\" , 負責將自然語言指令精確映射到屏幕上的具體像素位置 。 就像人類看到 \"點擊保存按鈕\" 時能迅速定位并操作一樣 , GUI Grounding 讓 AI 能夠 \"看懂\" 界面并知道該點擊哪里 。
然而 , 這個看似簡單的任務實際上充滿挑戰 。 現有的 GUI Grounding 方法普遍存在一個致命缺陷:它們把復雜的空間交互簡化成了 \"非黑即白\" 的二元判斷 。
具體來說 , 當前主流方法采用的是二元獎勵機制 —— 要么完全正確(獎勵 = 1) , 要么完全錯誤(獎勵 = 0) 。 這就像用 \"及格 / 不及格\" 來評價射擊成績:只要沒打中靶心 , 哪怕子彈擦邊而過 , 也和完全脫靶一樣被判為 \"0 分\" 。
這種評判標準帶來了三大問題:
學習信號稀疏:模型在訓練初期很難獲得有效反饋 , 就像蒙著眼睛射箭 , 根本不知道朝哪個方向改進 。 ; 忽視空間連續性:界面交互本質上是連續的空間過程 , 距離目標 1 像素和距離 100 像素理應得到不同的評價 , 但二元機制完全忽略了這種差異 。 ; 與人類點擊行為不符:作者通過分析 AITW 數據集發現 , 人類點擊行為天然地遵循以目標為中心的高斯分布模式 , 而現有方法完全背離了這一自然規律 。更關鍵的是 , GUI 界面元素具有天然的二維空間屬性 —— 它們是有面積、有邊界的區域 , 而不是抽象的點 。 用戶可以在按鈕的任意位置成功點擊 , 只要在邊界內即可 。 但傳統的二元獎勵機制完全忽略了這種空間特性 , 將豐富的幾何信息簡化為單一的 \"中心點命中判斷\" 。
正是在這樣的背景下 , 一個關鍵問題擺在了研究者面前:
“GUI Grounding 是否有更適合該任務特性的獎勵機制?”
來自浙江大學的研究團隊提出新方法 ——GUI-G2(GUI Gaussian Grounding Rewards) , 一個將 GUI 交互從離散的 \"打靶游戲\" 轉變為連續的 \"空間建模\" 的全新方案 。
論文地址: https://arxiv.org/pdf/2507.15846 項目主頁:https://zju-real.github.io/GUI-G2 GitHub:https://github.com/ZJU-REAL/GUI-G2 Huggingface Paper: https://huggingface.co/papers/2507.158462.GUI-G2 框架:讓 AI 學會 \"人性化\" 點擊
面對傳統二元獎勵的局限性 , 研究團隊提出了 GUI-G2(GUI Gaussian Grounding Rewards)框架 , 核心思想是:既然人類的點擊行為遵循高斯分布 , 為什么不讓 AI 也這樣學習?
GUI-G2 的創新之處在于將 GUI 元素建模為二維高斯分布 , 而非簡單的點或矩形框 。 這一設計帶來了三個關鍵突破:
1. 雙重高斯獎勵機制:
a) 高斯點獎勵(Gaussian Point Rewards):評估定位精度 , 獎勵值隨著預測中心與目標中心的距離呈指數衰減 。 就像射擊比賽中 , 越靠近靶心得分越高 。
b) 高斯覆蓋獎勵(Gaussian Coverage Rewards):評估空間重疊度 , 通過測量預測分布與目標區域的重疊程度 , 確保模型理解元素的完整空間范圍 。
2. 自適應方差機制:不同界面元素的尺寸差異巨大 —— 從幾像素的小圖標到全屏的面板 。 GUI-G2 引入自適應方差機制 , 根據元素實際尺寸動態調整高斯分布的 \"容錯范圍\":(1)小圖標:要求精確定位(小方差)(2)大按鈕:允許更大的空間誤差(大方差) 。 這就像人類的點擊習慣 —— 對小目標更加小心 , 對大目標相對寬松 。
3. 連續空間優化:與傳統方法在目標框邊界處出現 \"獎勵懸崖\" 不同 , GUI-G2在整個界面平面提供平滑的梯度信號 。 模型在任何位置都能獲得有意義的反饋 , 大大提升了學習效率 。
3、實驗結果
研究團隊在三個主流 GUI 定位基準上進行了全面評估 。 性能表現亮眼 ScreenSpot: 92.0% 準確率;ScreenSpot-v2: 93.3% 準確率;ScreenSpot-Pro: 47.5% 準確率 , 比 UI-TARS-72B 提升 24.7% 。 特別值得注意的是 , GUI-G2-7B 僅用 7B 參數就超越了 72B 參數的大型模型 , 展現了驚人的效率優勢 。
4、訓練動態分析
對比實驗顯示 , 傳統稀疏獎勵在訓練過程中表現出嚴重的不穩定性 —— 獎勵值劇烈波動 , 距離目標中心的收斂過程雜亂無章 。 而 GUI-G2 展現出單調平滑的收斂曲線 , 從 290 像素逐步優化到 150 像素 , 學習過程清晰可控 。
5、消融研究證實設計合理性
移除覆蓋獎勵:性能下降至 92.1%(-1.2%) 移除點獎勵:性能下降至 90.2%(-3.1%) 限制獎勵范圍:僅在目標框內提供高斯獎勵 , 性能下降 4.9% 固定方差機制:使用統一方差參數 , 性能僅 87.8% , 比自適應機制低 5.5 個百分點
這些結果證實了雙重獎勵機制的必要性 , 以及全空間連續反饋的重要作用 。
6、虛假獎勵實驗:驗證方法的本質有效性
【浙大團隊提出GUI-G2,顯著提升GUI智能體定位性能】為了證明 GUI-G2 的提升并非來自于強化學習的 \"虛假刺激效應\" , 研究團隊特意設計了對照實驗 —— 使用完全隨機的獎勵信號進行訓練:
連續隨機獎勵 U (01):從 90.6% 逐步下降至 87.9%(-2.7%) 二元隨機獎勵 {01:從 88.6% 快速跌至 84.5%(-4.1%)實驗結果表明 , 虛假的隨機獎勵只會讓性能持續惡化 , 這有力證明了 GUI-G2 的性能提升源于其科學的空間建模機制 , 而非強化學習過程中的偶然因素 。
7、GUI-G2總結
GUI-G2通過三個核心創新重新定義了GUI交互的本質:引入雙重高斯獎勵機制 , 同時優化定位精度和空間覆蓋;設計自適應方差機制 , 根據元素尺寸動態調整容錯范圍;實現連續空間優化 , 為模型提供平滑的全域梯度信號 。 這一框架將GUI定位從稀疏的二元優化轉變為密集的連續獎勵反饋 , 在三個基準測試中均取得顯著提升 。
推薦閱讀















- 960顆類腦芯片,浙大“悟空”出世
- Zoom團隊:AI推理新突破提升ChatGPT效率80%
- 全國產智能體MasterAgent:一句話造專屬AI團隊,專業協同交付
- VLA-OS:NUS邵林團隊探究機器人VLA做任務推理的秘密
- 教AI學會犯錯——加州大學伯克利分校團隊揭示編程教育新思路
- 多模態大模型學會回頭「看」:中科院自動化所提出GThinker模型
- 清華大學團隊讓AI學會識別表情背后的真實感受
- 復旦聯合南洋理工提出基于視覺Grounding的多輪強化學習框架MGPO
- Meta出走華人創業團隊,種子輪800萬美元,要打造視覺AI記憶大腦
- 夸克、浙大開源OmniAvatar,一張圖+一段音,就能生成長視頻