
文章圖片
文章圖片
LaTeX 公式的光學字符識別(OCR)是科學文獻數字化與智能處理的基礎環節 , 盡管該領域取得了一定進展 , 現有方法在真實科學文獻處理時仍面臨諸多挑戰:
【科研寫作神器,超越Mathpix的科學公式提取工具已開源】
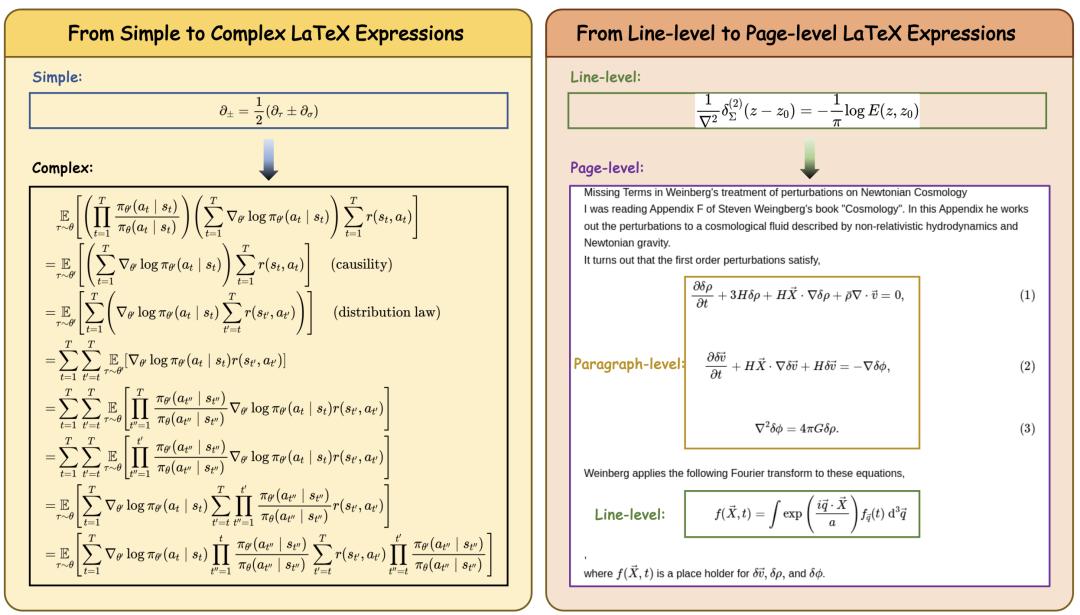
其一 , 主流方法及公開數據集多聚焦于結構簡單、符號單一的公式 , 難以覆蓋多學科、高難度的復雜公式;其二 , 實際文檔中廣泛存在的多行公式、長公式、分段公式及頁面級復雜排版等情況尚未得到充分關注與處理;其三 , 大多數方法依賴專用模型 , 通常需要針對特定任務進行專門設計 , 難以實現通用性和擴展性 。
針對上述挑戰 , DocTron 團隊提出了系統性解決方案 。
首先 , 針對現有數據集覆蓋面有限、結構單一的問題 , 構建了涵蓋多學科、多結構的大規模高難度數據集 CSFormula , 包含行級、段落級和頁面級的復雜排版 。
其次 , 團隊提出的 DocTron-Formula 模型突破了對特定結構建模的依賴 , 采用通用大模型驅動的復雜公式識別方法 , 僅需簡單微調即可適配多樣化應用場景 。
最后 , 相比于最優的定制化公式識別模型 , 該方法不僅在主流的開源評測中取得了優秀的性能表現 , 在實際應用中常見的頁面級、段落級復雜排版場景中也取得了顯著優勢 , 推動了公式識別的應用邊界 。
DocTron 是一個在通用視覺語言模型架構上實現結構化內容解析和理解的開源項目 , 而無需定制化的模塊開發 , 覆蓋通用文檔、學科公式、圖表代碼等場景 。
論文標題:DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios 論文鏈接:https://arxiv.org/abs/2508.00311 Github 鏈接:https://github.com/DocTron-hub/DocTron-Formula 項目開源地址:https://huggingface.co/DocTron
創新點與技術突破
(1)高難度多結構數據集構建 。 研究團隊自主設計高效的數據采集與處理流程 , 系統性地從高質量學術資源中收集、清洗并整理了大量多學科的復雜公式樣本 , 構建了 CSFormula 數據集 。
該數據集涵蓋數學、物理、化學等領域 , 包含行級、段落級和頁面級的復雜排版 , 更真實地反映了文獻中公式的多樣性與挑戰性 , 為模型訓練與評測提供了堅實基礎 。
(2)通用大模型驅動的復雜公式識別 。 研究團隊突破了對結構定制和專用架構的依賴 , 直接利用 Qwen2.5-VL 等通用大規模多模態預訓練模型 , 并通過在高難度數據集上的有監督微調實現領域適配 。
實驗結果表明 , 大模型憑借強大的知識遷移和結構泛化能力 , 僅需簡單微調即可在復雜場景下取得 SOTA 性能 , 無需繁瑣的工程設計或人工規則 , 顯著提升了復雜公式識別的通用性和實用性 。
實驗結果與性能表現
實驗結果顯示 , DocTron-Formula 在各類公開基準測試及自建 LaTeX 公式識別數據集上均表現出色 。 在編輯距離和 CDM 兩個指標下 , 不僅超越了現有專業工具 Mathpix , 在多個任務上也優于 GPT-4o 和 Gemini-2.5-flash 等主流閉源大模型 。
研究意義與應用前景
本研究不僅推動了復雜公式識別技術的發展 , 也為相關領域開辟了新的研究思路:
首次系統構建了覆蓋多學科、多結構的大規模高難度數據集 CSFormula , 為復雜公式識別的模型訓練和評測提供了堅實的數據支撐; 驗證了通用大模型(如 Qwen2.5-VL)在復雜公式識別任務中的強大適應性和泛化能力 , 顯著簡化了模型開發流程 , 減少了對專用設計和人工規則的依賴;
在應用層面 , DocTron-Formula 有望服務于科學文獻解析、學術知識檢索和教育資源智能化等多元場景 , 為科研、教育和信息服務等領域的自動化與智能化提供有力支撐 。
結論
DocTron-Formula推動了學科公式理解在行級、段落級、頁面級復雜排版場景的應用 , 強調無需定制化的算法模塊 , 通過高質量數據的構建和通用模型訓練 , 實現開源評測和現實應用評測的全面提升 。
推薦閱讀














- 炸場!海信電視E8Q Pro成2025ChinaJoy最火游戲神器
- 全球首款通用AI科研智能體:我用它寫了份CRISPR基因編輯報告
- 設計師必備生產力神器:AMD銳龍線程撕裂者9980X/9970X首發測試
- 卡內基梅隆大學開發出通用音頻理解神器OpenBEATs
- Linux 下 zsh 和 bash 大比拼:誰才是終端神器
- 榮耀Earbuds A Pro 評測:顏值與實力并存的通勤神器
- 選夏日宅家神器?看高性能+大電池的一加Ace 5至尊版
- 陶哲軒看傻:三破18年數學紀錄,谷歌推出「AI愛迪生」,科研不再靠靈感?
- 快充兼容性測試提速神器:天德鈺 QC/PD Switch Box深度體驗
- 實測Aqara G100:蘋果用戶最該入手的259元看家神器