文章圖片

文章圖片
文章圖片
機器之心報道
機器之心編輯部
眾所周知 , 大型語言模型的訓練通常分為兩個階段 。 第一階段是「預訓練」 , 開發者利用大規模文本數據集訓練模型 , 讓它學會預測句子中的下一個詞 。 第二階段是「后訓練」 , 旨在教會模型如何更好地理解和執行人類指令 。
在 LLM 后訓練階段 , 似乎是一個強化學習的特殊形式 。 用于大語言模型(LLMs)微調的強化學習(RL)算法正沿著一條明確的演進路徑持續發展 。
起初 , OpenAI 開創了一種名為 基于人類反饋的強化學習(RLHF) 的技術 , 用于改進 ChatGPT 。 RLHF 的核心是讓人類標注員對模型生成的多種響應進行打分 , 并選出最優答案作為訓練參考 。 這一過程雖然有效 , 但也耗時、昂貴且依賴人力 , 通常需要一支小型但專業的數據標注團隊 。
DeepSeek 的重要創新在于用 RL 技術自動化了這一環節 。 算法不再依賴人工逐一評估 , 而是讓模型在探索過程中 , 通過獲得「獎勵信號」自主學習正確行為 , 從而顯著降低了成本 , 提高了效率 , 最終能以較低的成本實現高性能 。
OpenAI 在 ChatGPT 的訓練中采用了近端策略優化(Proximal Policy Optimization PPO) 。
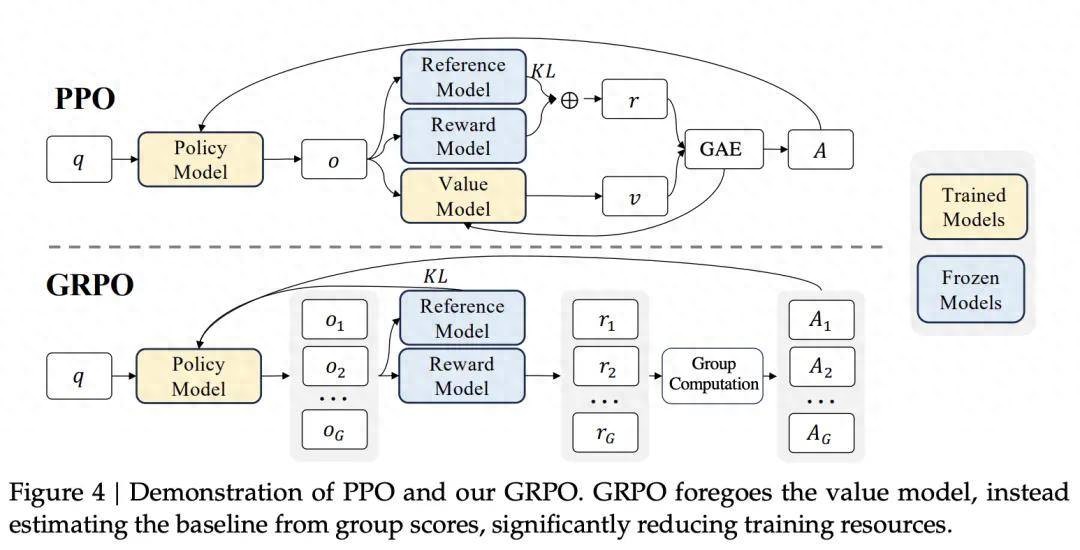
而 DeepSeek 團隊 則認為 , 在一組樣本中進行價值估計更加有效 , 因此提出了 組相對策略優化(Group Relative Policy Optimization GRPO) 算法 , 這也是 DeepSeek-R1 中的核心技術 , 使 DeepSeek-R1 模型大放異彩 。
GPRO 與 PPO 的對比 , 摘自 DeepSeekMath 論文 。
在幾個月前 Qwen3 首次亮相的時候 , 其旗艦模型的性能就已經與 DeepSeek-R1、o3-mini、Gemini 2.5 Pro 等頂級模型表現相當 。 除此以外 , Qwen3 系列模型覆蓋了 MoE 模型和密集模型 , 每一款模型又有許多細分版本 。
近些天 , Qwen3 系列模型仍然在不停的迭代更新 , 例如 Qwen3-235B-A22B-Instruct-2507-FP8 在知識數學、編程、人類偏好對齊、Agent 能力等眾多測評中表現出色 , 甚至了超過 Kimi-K2、DeepSeek-V3 等頂級開源模型以及 Claude-Opus4-Non-thinking 等領先閉源模型 。
最近 , Qwen 團隊發布了一篇有關其模型后訓練算法的論文 , 似乎揭示了 Qwen3 模型成功的核心技術細節 。
論文標題:Group Sequence Policy Optimization 論文鏈接:https://huggingface.co/papers/2507.18071 博客鏈接:https://qwenlm.github.io/blog/gspo/而在昨天 , 來自清華大學校友創立的創業公司 NetMind.AI 發表了一篇博客 , 題為《Qwen Team Proposes GSPO for Qwen3 Claims DeepSeek's GRPO is Ill-Posed》 , 對 Qwen 團隊為 Qwen3 模型提出的 GSPO 算法進行了詳盡的介紹與分析 。
博客鏈接:https://blog.netmind.ai/article/Qwen_Team_Proposes_GSPO_for_Qwen3%2C_Claims_DeepSeek's_GRPO_is_Ill-Posed最近 Qwen 的研究表明 , 使用 GRPO 訓練大語言模型時存在嚴重的穩定性問題 , 往往會導致模型不可逆地崩潰 。 他們認為 DeepSeek 的 GPRO 方法存在一些嚴重問題:
在每個 token 級別應用重要性采樣 , 會在長序列中積累高方差 , 導致訓練不穩定 。 這一問題在 專家混合模型(Mixture-of-Experts MoE) 中尤為嚴重 , 因為 token 級別的路由變化會加劇不穩定性 。 為緩解這一問題 , 基于 GRPO 的訓練流程通常需要依賴一些額外策略 , 例如 路由重放(Routing Replay) 。因此 , Qwen 團隊聲稱 GRPO 的 token 級重要性采樣無法達到穩定訓練 , 其優化目標是「病態的(ill-posed)」 。
為了解決這些問題并訓練其最新的 Qwen3 系列模型 , Qwen 團隊提出了一種新的強化學習算法 —— 組序列策略優化(Group Sequence Policy Optimization GSPO) 。
GRPO 的根本問題:
「逐 token 重要性采樣」的不穩定性
Qwen 團隊指出 , GRPO 的不穩定性源于其對 token 級重要性采樣權重的錯誤使用 。 在強化學習中 , 重要性采樣(Importance Sampling)用于校正行為策略(即用于收集訓練數據的策略)與目標策略(當前正在優化的策略)之間的差異 。
當兩者不一致時 , 重要性采樣通過為已有數據樣本賦予權重 , 使其更能代表當前希望優化的目標策略 , 從而提高訓練的穩定性與有效性 。
在大語言模型(LLMs)的訓練中 , 強化學習常常會復用舊策略生成的響應 , 以節省計算資源 , 這屬于典型的「離策略」(off-policy)訓練場景 。 重要性采樣正是用于緩解這種策略不匹配帶來的影響 , 并幫助穩定訓練過程 。
然而 , GRPO 將重要性采樣的權重應用在每一個 token 上 , 而非整個生成的序列 。 這種做法會帶來顯著的方差 , 并在生成較長序列時造成「誤差積累」與「訓練不穩定性」 。
從形式上講 , GRPO 是在每一個 token 的生成步驟上單獨計算重要性權重的:
Qwen 團隊指出 , 當在訓練目標中應用此類重要性權重時 , 由于每個 token 的比值是獨立計算的 , 會導致高方差的累積 , 從而破壞梯度穩定性 , 最終引發模型崩潰 。
同時 , 這種做法會將高方差噪聲引入訓練梯度中 , 尤其在長序列上呈現累積效應 , 并且在存在「裁剪機制」時 , 這種不穩定性問題會進一步加劇 。
Qwen 團隊的實驗證據
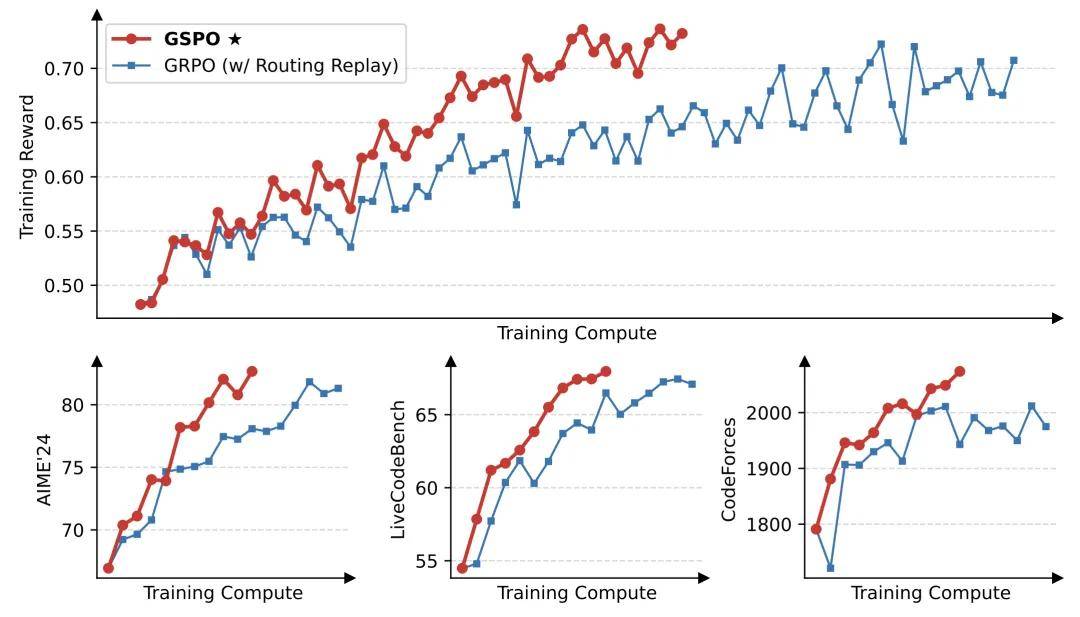
Qwen 團隊通過實驗證據驗證了其理論分析 , 如圖所示 。
在所有展示的實驗場景中 , 其新提出的算法 GSPO 均表現出比 GRPO 更高的訓練效率 。 在 CodeForces 任務中 , GRPO 的最終得分收斂于 2000 分以下 , 而 GSPO 隨著訓練計算量的增加持續提升成績 , 展現出更強的「可擴展性」 。
GSPO 與 GRPO 的訓練曲線對比
Qwen 的解決方案:
「序列級重要性采樣」
那么 , GSPO 是如何解決上述問題的呢?
正如其名稱所暗示的 , GSPO 的核心在于將重要性采樣從 token 級轉移至序列級 , 其重要性比值基于整個序列的似然度計算:
這種采樣權重的設計自然地緩解了逐 token 方差的累積問題 , 從而顯著提升了訓練過程的穩定性 。
需要注意的是 , 指數中的因子用于「長度歸一化」 。 如果不進行長度歸一化 , 僅僅幾個 token 的似然變化就可能導致序列級重要性比值的劇烈波動 , 而不同長度的生成響應在目標函數中也將需要不同的裁剪范圍 , 這會進一步增加訓練的不穩定性 。
實驗驗證的優勢:
簡化 MoE 模型訓練
針對專家混合模型(MoE)所進行的專項實驗進一步強調了 GSPO 的優勢 。
由于 MoE 模型具有稀疏激活特性 , 這會在使用 GRPO 時進一步加劇訓練過程中的不穩定性 。 在經過一次或多次梯度更新后 , 相同響應所激活的專家網絡可能發生顯著變化 。
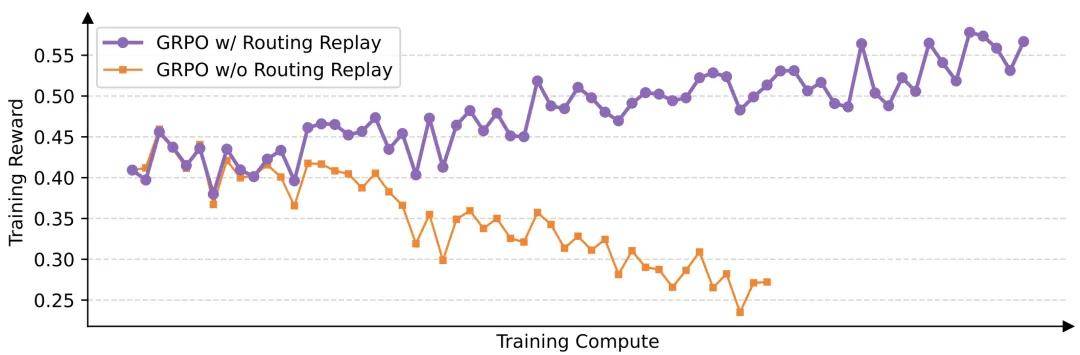
Qwen 團隊在使用 GRPO 訓練 48 層的 Qwen3-30B-A3B-Base 模型時發現:在每一次強化學習的梯度更新后 , 對于相同的 rollout 樣本 , 新策略所激活的專家中約有 10% 與舊策略所激活的專家不同 。 這實際上意味著 , 每次梯度更新后 , 你都在用不同的數據樣本訓練不同的模型 , 毫無疑問這是一種極其低效的訓練方式 。
在引入 GSPO 之前 , 為緩解這一問題 , 他們甚至采取了一種名為「Routing Replay」的技巧 , 即強制目標策略激活與舊策略相同的專家網絡 。
相比之下 , GSPO 無需使用 Routing Replay 也能實現穩定收斂 , 從而消除了不必要的訓練復雜性 , 并保留了 MoE 架構的全部潛力 。
Routing Replay 策略在 GRPO 訓練 MoE 模型的正常收斂中起到了關鍵作用
結論:
GSPO 或將成為新的標準
總結一下 , GSPO 的方法有兩點創新:
將重要性采樣從 token 級別提升到序列級別 , 并通過序列長度進行歸一化處理; 顯著降低了方差 , 同時消除了對「路由技巧」(如 Routing Replay)等輔助策略的依賴;業界已普遍達成共識 —— 在大語言模型的后訓練階段引入強化學習 , 對于提升其推理能力至關重要 。
而論文中的大量實驗結果也進一步證實 , GRPO 所采用的「逐 token 重要性采樣」方法存在不穩定性和低效性的問題 。
因此 , GSPO 提出的「序列級重要性采樣」很可能會成為未來后訓練強化學習的新標準 。
參考鏈接:
https://www.reddit.com/r/MachineLearning/comments/1mj3t3r/d_gspo_qwen3s_sequencelevel_rlhf_method_vs_grpo/
https://blog.netmind.ai/article/Qwen_Team_Proposes_GSPO_for_Qwen3%2C_Claims_DeepSeek's_GRPO_is_Ill-Posed
https://www.ft.com/content/ea803121-196f-4c61-ab70-93b38043836e?utm_source=chatgpt.com
【DeepSeek的GRPO會導致模型崩潰?看下Qwen3新范式GSPO】https://zhuanlan.zhihu.com/p/22845155602
推薦閱讀













- 三重激勵+全周期扶持,即夢這個計劃,讓AI創作者的成長有跡可循
- iQOO Z10 Turbo+評測:實現全天游戲自由的電競新卷王
- 2025已過大半,今天的AI手機要怎么撬動“釘子戶”?
- 傅利葉發布全新人形機器人“Care-bot”GR-3,定義“有愛的”交互新范式
- 預算600左右,最值得購買的3款手機,款款亮點突出
- 主打的就是聽勸!OPPO Find X9曝光,挖空蘋果的節奏
- 投影放映系統與LED 電影屏如何選擇?HDR:下一代影院競爭的焦點
- 一塊錢的AI,開始審判人類
- 七夕送男朋友什么禮物?一加Ace 5至尊版包喜歡的
- 人大高瓴-華為諾亞:大語言模型智能體記憶機制的系列研究