
文章圖片

文章圖片
文章圖片

文章圖片

本系列工作第一作者張澤宇 , 中國人民大學博士生 , 研究方向為大語言模型智能體的記憶機制和個性化;譚浩然 , 中國人民大學碩士生 , 研究方向為大語言模型智能體 。 陳旭 , 中國人民大學預聘副教授 , 研究方向包括大語言模型 , 信息檢索等 。
近期 , 基于大語言模型的智能體(LLM-based agent)在學術界和工業界中引起了廣泛關注 。 對于智能體而言 , 記憶(Memory)是其中的重要能力 , 承擔了記錄過往信息和外部知識的功能 , 對于提高智能體的個性化等能力至關重要 。 中國人民大學高瓴人工智能學院與華為諾亞方舟實驗室聚焦大語言模型智能體的記憶能力 , 在該領域的研究早期 , 形成了一套完整的包括綜述論文、數據集和工具包的研究體系 , 致力于推動該領域的發展 。
智能體記憶機制的早期綜述 (TOIS'25)
論文標題: A Survey on the Memory Mechanism of Large Language Model based Agents 論文鏈接:https://dl.acm.org/doi/10.1145/3748302
在 2024 年 4 月 , 團隊完成了早期的關于智能體記憶機制的綜述 。 該綜述從不同角度對智能體的記憶進行了全面討論 。 該綜述討論了「什么是智能體的記憶」和「為什么智能體需要記憶」 , 總結回顧了「如何實現智能體的記憶」和「如何評測智能體的記憶能力」 , 歸納整理了「記憶增強的智能體應用」 , 并提出當前工作存在的局限性和未來方向 。 通過該綜述 , 團隊希望能夠為研究者帶來啟發和討論 , 推動大語言模型智能體領域的發展 。
什么是智能體的記憶?
【人大高瓴-華為諾亞:大語言模型智能體記憶機制的系列研究】對于智能體的記憶 , 從記憶內容的來源出發 , 團隊提出了狹義和廣義兩種記憶概念:
狹義記憶: 記憶是智能體在進行本次任務時與環境交互的歷史信息 。
廣義記憶: 記憶除了包括智能體在本次任務進行時與環境的交互信息 , 還包括此前完成該類任務的經驗 , 以及外部知識 。
為什么智能體需要記憶?
為了更好地闡述記憶對智能體的重要性 , 團隊從認知心理學、智能體的自我進化和智能體的應用三個角度進行討論 。
認知心理學角度: 為了更好地讓智能體完成任務 , 智能體的設計往往需要借鑒人類的思維特點 。 而記憶對于人類而言 , 在知識學習、概念提取、價值觀孵化、社會規范形成和文化萌芽等方面具有重要作用 。
智能體的自我進化: 在智能體與環境的交互過程中 , 記憶承擔了經驗積累、環境探索和知識提取的作用 , 使智能體能夠在于環境的動態交互過程中不斷自我進化 。
智能體的應用: 在智能體的實際應用中 , 記憶對于語境連貫、角色定位和領域知識積累等方面具有關鍵作用 。團隊從記憶的來源、記憶的實現形式和記憶的操作三個角度 , 分別對現有的智能體記憶實現方法進行分類和討論 。
如何實現智能體的記憶?
從記憶的來源角度出發 , 團隊將現有工作分為三類來源 , 這種分類與上文中「廣義記憶」的三部分記憶內容來源相對應 。
Inside-trial Information: 智能體在進行本次任務時與環境交互的歷史信息 。 Cross-trial Information: 智能體在此前完成該類任務的歷史經驗信息 。 External Knowledge: 智能體在當前交互環境之外所獲得的信息 。
從記憶的實現形式角度出發 , 團隊將現有工作分為文本形式(Textual Form)和參數形式(Parametric Form)兩種實現形式 , 不同的形式有各自的實現方法 。
文本形式記憶: 本質上是用顯式(Explicit)的方法表示記憶 。 在文本形式的記憶中 , 可以通過完全信息記憶、最近信息記憶、檢索信息記憶和外部工具信息記憶四類方法來實現智能體的記憶機制 。
參數形式記憶: 本質上是用隱式(Implicit)的方法 。 在參數形式的記憶中 , 可以通過模型微調和記憶編輯兩類方法來實現智能體的記憶機制 。
從記憶的操作角度出發 , 團隊將現有工作按照記憶寫入、管理和讀取三個重要操作進行總結 。
記憶寫入: 智能體將重要的信息寫入記憶存儲 , 作為未來的推理和決策依據 。 在記憶寫入時 , 既可以寫入原始信息 , 也可以對其進行總結提取 , 或同時記錄輔助信息 。
記憶管理: 智能體將寫入的記憶進行管理與加工 , 例如記憶合并、記憶反思和記憶遺忘 。
記憶讀?。 ?智能體在決策時可以使用此前存儲的相關記憶信息 , 來為決策提供更多信息與知識 。
如何評測智能體的記憶?
團隊將智能體記憶機制的評測分為直接評測和間接評測兩類 。
直接評測: 直接對單獨的記憶模塊進行評測 , 包括主觀評測和客觀評測 。
間接評測: 在智能體的實際應用中進行端到端的評測 , 通過不同記憶機制對相同智能體任務產生的性能影響 , 間接反映出各個記憶機制的能力 。
記憶增強的智能體有哪些應用?
記憶推動了智能體在各領域中的應用 , 而在各個應用場景中 , 記憶所承擔的功能也各不相同 。
角色扮演與社會模擬: 在角色扮演和社會模擬中 , 記憶賦予了智能體不同的人格和自我感知 , 使他們能夠按照人設執行動作 , 從而區分于其他的智能體角色 。 基于不同的人格 , 它們可以進一步交互形成模擬社會 。
個人助理: 在個人助理中 , 記憶賦予了智能體記憶用戶習慣和個性化需求的能力 , 使智能體能夠提供個性化的幫助 。 此外 , 記憶可以基于上下文 , 幫助智能體更好地理解當前用戶的需求 。
開放世界游戲: 在開放游戲世界中 , 記憶賦予了智能體總結回顧過往經驗的能力 , 從而用于智能體的后續探索 。 另外 , 來自外部信息的記憶可以為智能體提供更豐富的知識 , 提升其探索能力 。
代碼生成: 在代碼生成和軟件開發中 , 記憶賦予了智能體更豐富的開發知識 。 此外 , 借助過往記憶 , 智能體可以生成風格更加一致的代碼 , 同時有利于基于上下文進行需求澄清 。
推薦系統: 在推薦系統中 , 記憶賦予了智能體捕捉和維護用戶個性化信息的能力 , 使它能夠更深入地理解用戶的個性化需求 , 從而提供更符合用戶需求的推薦結果 。
領域專家系統: 在領域專家系統中 , 記憶賦予了智能體豐富的領域知識 。 此外 , 記憶有利于提升知識的時效性 , 克服知識過時的問題 。
局限性與未來方向
最后 , 團隊進一步討論了當前智能體記憶機制工作的局限性和未來方向 , 包括參數化記憶機制、多智能體記憶機制、記憶機制與終身學習和類人智能體的記憶機制 。
智能體記憶機制的早期評測-MemSim
論文標題: MemSim: A Bayesian Simulator for Evaluating Memory of LLM-based Personal Assistants 論文鏈接:https://arxiv.org/abs/2409.20163 代碼倉庫:https://github.com/nuster1128/MemSim
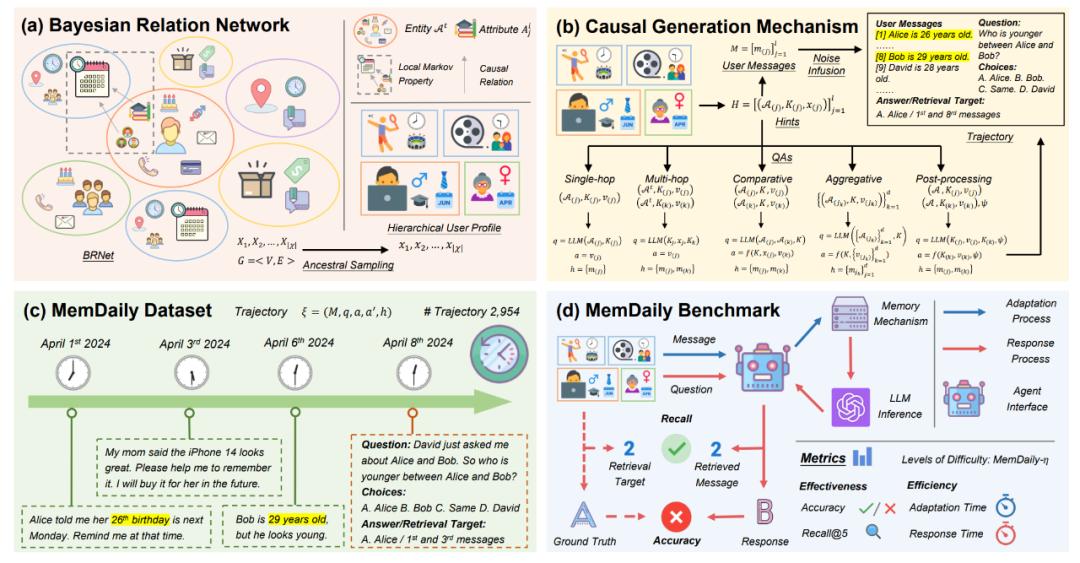
在 2024 年 9 月 , 團隊進一步地對智能體記憶機制的評測方法進行了探究 。 團隊聚焦智能助手場景 , 提出了對用戶事實性記憶的評測數據構造框架 MemSim , 并構建了評測數據 MemDaily 。 基于 MemDaily , 團隊對常用的智能體記憶方法進行了評測和分析 。
用戶事實性記憶評測數據構造
相比于世界知識 , 用戶事實性記憶主要來源于不同個體 , 由智能體與用戶個體交互而獲得 , 因此也是評測智能助手記憶的關鍵 。 團隊提出了 MemSim 框架 , 用以構建用戶事實性記憶的評測數據 。 團隊首先提出了貝葉斯關系網絡 , 構造了表征用戶畫像概率分布的元用戶畫像 , 包含屬性層次和實體層次 , 并由此采樣出不同的用戶畫像 。
然后 , 團隊基于不同實體與屬性之間的關系 , 構造了多種形式的問答 , 包括單跳、多跳、比較、聚合和后處理等問答類型 , 以貼近真實場景下的用戶問答 。 對于用戶消息 , 團隊基于采樣屬性中的答案和噪聲構造事實信息元組 , 并借助大模型的文本組織能力 , 生成得到流暢且包含特定信息的用戶消息 。 基于 MemSim 框架 , 團隊在日常生活場景下生成了數據集 MemDaily 。
MemDaily 數據評估
團隊對 MemDaily 數據進行了評估 , 其中包括用戶畫像構建的質量 , 用戶消息構造的質量和問答的質量 。 對于用戶畫像 , 關注其合理性和多樣性;對于用戶消息 , 側重于它的流暢性、合理性、自然性、信息性和多樣性;對于問答的質量 , 著重評估它對于文本答案、選擇答案和檢索目標的正確性 。
記憶機制評測
基于 MemDaily , 團隊對目前常用的幾種記憶機制進行了對比評測 , 并進一步融入了不同程度的噪聲 , 以擴展記憶文本的總量 , 從而提供不同難度的評測數據集 。 團隊對記憶的有效性和效率進行了評測 。 其中 , 記憶有效性的指標主要包括問答的準確率和檢索目標的召回率 , 記憶效率的指標主要包括調整時間和推理時間 。 實驗表明 , 不同模型的性能與問答類型和記憶文本的總量有關 , 因此 , 不同模型適用于不同類型的任務 。 值得提及的是 , MemDaily 數據也支撐了華為鴻蒙系統級 AI 助手小藝的記憶相關特性的能力評測 。
智能體記憶機制的評測榜單-MemBench (ACL'25 Findings)
論文標題: MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents 論文鏈接:https://arxiv.org/abs/2506.21605 代碼倉庫:https://github.com/import-myself/Membench
2025 年 2 月 , 在 MemSim 的基礎上 , 團隊進一步構建了智能體記憶機制的評測榜單 。 團隊同樣聚焦于智能助手場景 , 提出從觀測和參與兩個角度 , 對智能體的反思和事實兩種記憶類型進行評測 , 涵蓋了記憶的有效性、效率和容量評估 。
多場景記憶視角
在參與場景中 , 智能體與用戶進行互動 , 而在觀測場景中 , 智能體僅作為觀察者 , 記錄用戶輸入的消息 。 在參與場景中 , 智能體執行其他模塊如推理動作模塊 , 從而和用戶發生交互 , 并改變記憶模塊記憶的內容;在觀測場景中 , 智能體不會執行除了記憶之外的任何模塊 , 只接受用戶單方面的信息輸入 。
多層次記憶數據
團隊在 MemDaily 構建的事實記憶基礎上擴展了問答的類型 , 增加了例如知識更新等問答類型 。 同時 , 團隊新增了偏好和情感兩種記憶內容 , 分別評估智能體反思記憶能力 。 相較于用戶向智能體直接表達出的事實記憶 , 反思記憶需要根據用戶表達的低層次內容 , 從對話中提取并總結高層次的偏好 , 包括一些事實屬性 。
多維度記憶評測
基于構建的數據集 , 論文從記憶的準確率、召回率、容量和效率對現有常見的多種記憶機制進行了評測 。 其中 , 團隊認為智能體的記憶機制可能存在容量限制 , 當記憶內容的量達到一定程度時 , 準確性會急劇下降 , 這一臨界值代表了記憶的容量 。
智能體記憶機制的工具包-MemEngine (TheWebConf'25 Resource Oral/Top 10)
論文標題: MemEngine: A Unified and Modular Library for Developing Advanced Memory of LLM-based Agents 論文鏈接:https://dl.acm.org/doi/10.1145/3701716.3715299 代碼倉庫:https://github.com/nuster1128/MemEngine
2024 年 12 月 , 團隊實現了智能體記憶機制的早期工具包 MemEngine 。 近年來 , 雖然一些近期的工作提出了不同的智能體記憶機制 , 但它們缺少統一框架下的實現方案 。
為此 , 團隊提出了統一的智能體記憶機制框架 , 并設計了模塊化的工具庫 MemEngine , 用于便捷地實現和使用不同的智能體記憶機制 。 MemEngine 實現了近期研究中的記憶機制方法 , 設計了便捷開發與可擴展的模塊 , 并提供了豐富且用戶友好的使用方式 。
統一模塊化的記憶框架
團隊提出了一個統一模塊化的記憶框架 , 該框架包含三個層次:最底層為基礎的功能方法 , 如檢索、總結等;中間層為記憶操作 , 包含記憶的存儲、召回等;最高層為具體的記憶方法 , 如 MemoryBank、MemGPT 等 。 在框架中 , 高層的模塊可以組合復用低層模塊 , 從而提高實現效率 。 此外 , MemEngine 還提供了配置模塊和工具模塊 , 輔助研究者和開發者進行探究和部署 。
豐富的內置記憶方法
基于上述統一模塊化的記憶框架 , 團隊實現了 9 種近期研究工作中常用的記憶方法 , 如 MemoryBank , MemGPT 等 。 基于 MemEngine 的統一框架 , 這些方法之間可以無縫切換 , 從而更便捷地適配于具體應用 。
便捷擴展的記憶開發
基于模塊化架構 , 研究者可通過三級擴展機制快速實現記憶方法的創新:在最底層擴展基礎功能 , 如可新增多模態編碼器;在中間層擴展記憶操作 , 如可實現不同的反思操作;在最高層基于現有模塊構建新型記憶模型 。 MemEngine 提供了完整開發文檔與代碼示例 , 支持從基礎功能定制到模型級創新的全流程開發 。 開發者可繼承基礎類實現個性化功能 , 或通過配置模塊快速驗證不同參數組合 , 顯著降低新記憶方法的實現門檻 。
用戶友好的記憶部署
MemEngine 提供本地與遠程雙部署模式:本地支持 pip 安裝與源碼集成 , 遠程可通過 API 調用記憶服務 。 提供默認、可配置、自動三種使用模式:默認模式開箱即用;配置模式支持動態調整提示詞等參數;自動模式可根據任務類型自動搜索記憶模型與參數組合 。 框架兼容 AutoGPT 等主流智能體平臺 , 滿足從學術研究到工業落地的多樣化需求 。
推薦閱讀









- 太意外了!華為“死對頭”發布報告,自動化水平超出全球平均約16%
- 華為Mate80曝光:零下巴+6000mAh電池,真香預定
- 僅差0.2%,小米就要超過華為,成中國市場第一名了
- 華為nova 15持續發力影像,多款新機待發布
- 華為在妥協,對基本需求的洞察值得點贊,而且還是旗艦!
- 為更好與英偉達CUDA競爭,華為CANN全面開源
- 華為Nova15系列新機曝光:自研方案+新封裝技術,影像有大提升!
- UFCS融合快充車載充電器加速全面普及 支持華為、OPPO等手機快充
- 華為鴻蒙 6.0 界面首曝,新增 3 款機型!
- 華為Mate80震撼亮相:設計亮點十足,這才是顯眼包