
文章圖片
文章圖片

文章圖片
文章圖片
論文第一作者 Han Meng 是新加坡國立大學博士生 , 從事心理學構建的計算方法研究 。 通訊作者 Yi-Chieh Lee 是新加坡國立大學助理教授 , 在對話式人工智能、人機交互和心理健康技術領域開展研究工作 。 共同作者 Renwen Zhang 是南洋理工大學助理教授 , 專注于計算傳播學研究 , 為本研究提供了傳播學視角 。 Jungup Lee 是新加坡國立大學副教授 , 在心理健康領域有深入研究 , 為本研究提供了重要的領域知識支撐 。
心理健康問題影響著全球數億人的生活 , 然而患者往往面臨著雙重負擔:不僅要承受疾病本身的痛苦 , 還要忍受來自社會的偏見和歧視 。 世界衛生組織數據顯示 , 全球有相當比例的心理健康患者因為恐懼社會歧視而延遲或拒絕治療 。
這種「污名化」現象如同隱形的障礙 , 不僅阻礙了患者的康復之路 , 更成為了一個重要的社會問題 。 患者們在承受病痛的同時 , 還要面對來自不同社會環境中的偏見 。 更為復雜的是 , 這種污名化往往以微妙、隱蔽的形式存在于日常對話中 , 即使是先進的人工智能系統也難以有效識別 。
盡管自然語言處理領域在仇恨言論、攻擊性語言檢測方面已有不少研究 , 但專門針對心理健康污名的計算資源卻相對稀缺 。 現有數據集主要來源于社交媒體或合成數據 , 缺乏真實對話場景中的深層心理構建 , 且往往忽視了社會文化背景的重要性 。
新加坡國立大學 AI4SG 實驗室聯合多學科專家團隊 , 構建了首個基于專家標注的心理健康污名訪談語料庫 MHStigmaInterview , 希望為這一重要社會問題提供技術支持 。 該研究獲得 ACL 2025 Oral 論文及高級領域主席獎(全會僅 47 篇獲此榮譽)認可 。
論文標題:What is Stigma Attributed to? A Theory-Grounded Expert-Annotated Interview Corpus for Demystifying Mental-Health Stigma 論文鏈接:https://aclanthology.org/2025.acl-long.272.pdf 數據集鏈接:https://github.com/HanMeng2004/Mental-Health-Stigma-Interview-Corpus
研究團隊
該研究由新加坡國立大學 AI4SG 實驗室主導 , 匯聚了人機交互、計算社會科學、人工智能倫理等多個領域的研究者 。 AI4SG 實驗室專注于人機交互、計算社會科學、人機協作以及社會公益人工智能等交叉研究領域 。
研究團隊與心理健康領域專家密切合作 , 為 AI 和 NLP 研究引入了跨學科視角 , 為計算科學與社會科學的深度融合提供了一個探索案例 。
理論驅動的框架設計
與傳統依賴社交媒體數據的方法不同 , MHStigmaInterview 建立在心理學理論基礎上 。 研究團隊采用了歸因模型 , 將心理健康污名分解為七個核心維度:
認知層面:
責任歸因: 認為患者應為自己的病情負責
情感層面:
憤怒: 對患者感到不滿 恐懼: 認為患者危險、不可預測 憐憫: 缺乏真正的同情心
行為層面:
拒絕幫助: 不愿意提供支持 強制隔離: 主張強制住院治療 社交距離: 傾向于回避與患者接觸
這種理論驅動的標注體系 , 為后續的計算模型提供了相對明確的學習目標 。
基于聊天機器人的數據收集
為了獲得更自然的對話樣本 , 研究團隊設計了聊天機器人訪談系統 。 該系統通過三個階段引導參與者:
破冰階段: 聊天機器人(命名為 Nova)首先與參與者討論輕松話題 , 如興趣愛好、最近看過的電影等 , 建立基本的交流氛圍 。
情境植入: 系統呈現一個關于虛構角色「Avery」的抑郁癥患者故事 , 描述其在工作、學習、社交中面臨的挑戰 , 避免使用專業術語以減少社會期望偏見 。
深度訪談: 基于七個核心歸因維度設計訪談問題 , 如:
「你認為 Avery 目前的狀況主要是他們自己行為的結果嗎?」 「如果你要為家里選擇租戶 , 你會放心把房子租給像 Avery 這樣的人嗎?」 「如果你是 Avery 的鄰居 , 你會考慮讓他們離開社區并接受住院治療嗎?」
系統會根據參與者回答的詳細程度自動調整后續提問策略 , 以獲得充分的信息 。
數據集基本情況
經過嚴格的倫理審查和數據篩選 , 最終語料庫包含:
4141 個訪談片段 684 名參與者 , 涵蓋不同年齡、性別、種族、教育背景 平均 2.11 輪對話 , 總字符數超過 17 萬 專家標注: 兩名訓練有素的標注員獨立標注 , Cohen's kappa = 0.71
數據分析顯示:
53.9% 的回答沒有表現出污名化態度 責任歸因(9.51%)和社交距離(9.15%)是最常見的污名類型 恐懼(8.86%)和憤怒(7.20%)緊隨其后 相比傳統仇恨言論數據集 , 該語料庫中的污名化表達更加隱蔽、微妙
AI 模型的表現
【AI4SG團隊發布首個心理健康污名語料庫,破解隱性偏見識別難題】研究團隊在該語料庫上測試了當前主流的大語言模型 , 包括 GPT-4o、LLaMA-3 系列、Mistral 等 。
性能表現:
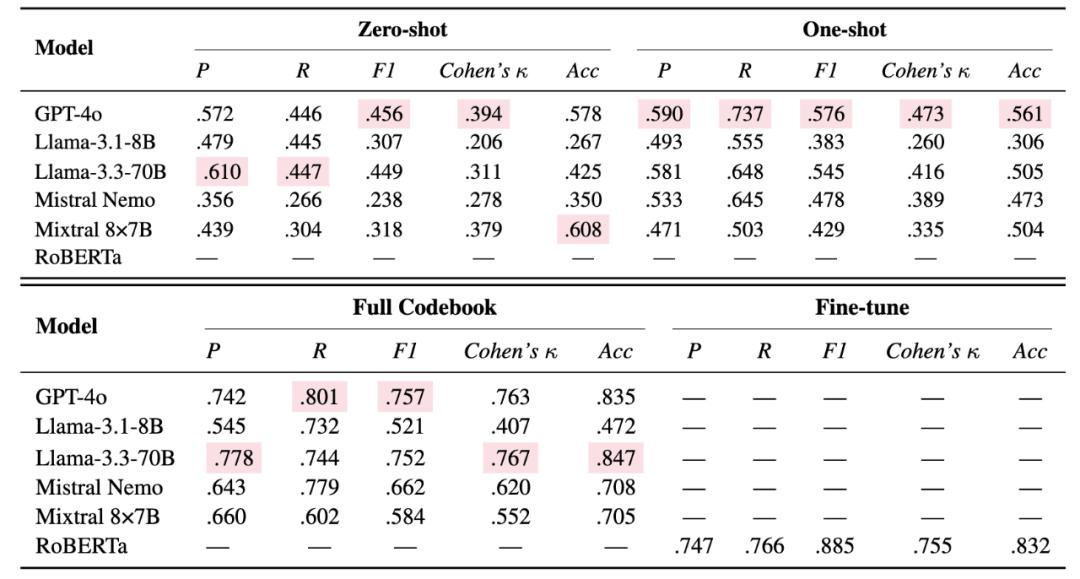
GPT-4o 在零樣本設置下 F1 分數為 0.456 提供詳細標注指南后 , 性能提升至 0.757 模型普遍存在高召回率、低精確率的問題
隱性污名表達的深入分析
通過對 137 個錯誤分類案例的分析 , 研究團隊發現了一些值得關注的模式 。 這些隱性污名化表達在日常對話中較為常見 , 但往往難以被識別 。
語言層面的表達特點:
距離化表達是一種常見的策略 , 說話者使用第三人稱視角來表達觀點 , 比如「鄰居們可能很難理解 Avery 的行為」 。 這種表達方式表面上顯得客觀 , 但往往暗含著某種判斷 。
術語濫用現象也比較普遍 , 一些人在缺乏專業背景的情況下 , 不恰當地使用心理學術語來描述患者 , 比如隨意使用「偏執」等詞匯 。 這種使用方式往往帶有負面含義 。
強制性措辭在建議中頻繁出現 , 諸如「絕對需要」、「必須接受」等表達 , 在一定程度上忽視了患者的自主選擇權 。
語義層面的深層模式:
差別化支持表現為對患者的過度小心 , 比如「我需要在與他們交流時更加謹慎」 。 雖然表面上顯得體貼 , 但實際上可能強化了患者的「特殊性」標簽 。
家長制態度體現在一些回應中 , 說話者往往以指導者的姿態出現 , 認為自己有資格「教導」患者如何生活 。 這種態度在一定程度上忽視了患者作為獨立個體的尊嚴 。
輕視化傾向則通過淡化心理健康問題的復雜性來體現 , 一些人習慣性地將心理健康問題簡化為態度問題 , 認為患者「想開一點」就能解決 。
這些發現揭示了現代社會中污名化表達的復雜性和隱蔽性 , 也說明了開發更精準識別系統的必要性 。
社會文化因素分析
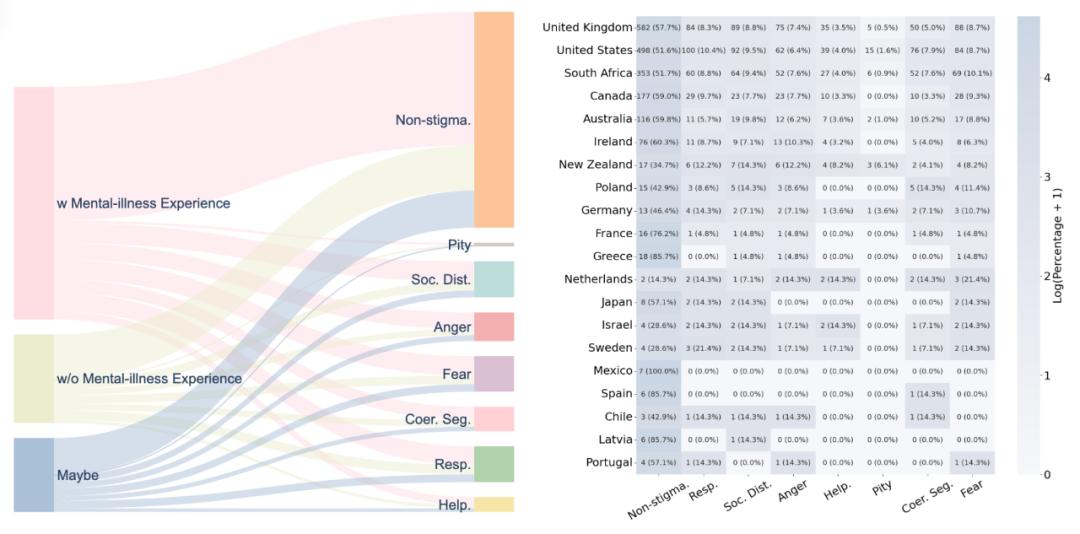
語料庫記錄了參與者的社會文化背景 , 初步分析顯示了一些有趣的模式:
性別差異: 女性參與者在某些維度上表現出相對較少的污名化傾向 年齡影響: 不同年齡群體對心理健康的態度存在差異 文化背景: 來自不同國家的參與者表現出不同的模式 個人經歷: 有心理健康問題接觸史的參與者更傾向于表現出非污名化態度
這些發現為理解污名化的社會根源提供了基本初步線索 。
應用前景與未來方向
該語料庫為多個研究方向提供了資源 。
技術應用:
開發更精準的污名化表達識別系統 為內容審核提供參考工具 支持心理健康相關 AI 應用的開發
研究拓展:
個性化的反污名干預策略研究 跨文化污名模式比較 不同干預方法的效果評估
社會應用:
心理健康教育項目設計 醫療從業者培訓支持 公共政策制定參考
MHStigmaInterview 語料庫的發布為心理健康污名的計算研究提供了一個新的起點 。 雖然這是初步的探索 , 但它展示了技術在解決社會問題方面的潛力 。 通過持續的跨學科合作和技術改進 , 作者希望能夠為構建更加包容的社會環境貢獻一份力量 。
這項工作指出 , 在追求技術進步的同時 , 關注技術的社會影響和人文關懷同樣重要 。 只有將技術發展與社會需求緊密結合 , 才能真正實現技術向善的目標 。
參考資料:
https://aclanthology.org/2025.acl-long.272.pdf
https://github.com/HanMeng2004/Mental-Health-Stigma-Interview-Corpus
推薦閱讀










- 僅1869元!天璣9400+配8000大電池新機,剛發布就問鼎第一!
- iQOO Z10 Turbo+發布!性能續航雙王炸,超分超幀暢玩!
- 蘋果 iOS 26 Beta 5 全新變化匯總,正式版預計將在這天發布!
- 清華大學團隊開發神奇對話評分器:讓AI對話質量評判更準確高效
- 1869元,剛發布的這8000mAh新機,真的太猛了
- Deep Cogito發布四款開源混合推理大語言模型
- 曝百度最快8月底發布新版推理模型 部分能力將超越OpenAI o3滿血版
- 全新360安全云重磅發布:AI智能體驅動「安全即服務」新未來
- 華為Mate 80將在10月發布 最強鴻蒙手機
- 華為Mate XTs硬剛iPhone17:同日發布,誰會更勝一籌?