
文章圖片

文章圖片
智東西
作者 | 陳駿達
編輯 | 漠影
在剛剛過去的7月份 , 國產模型迎來一波重磅開源 。 與以往不同的是 , 本次國內大模型玩家們開源模型的參數量成倍增長 , 達到數千億乃至萬億級別 。 這不僅顯著提升了國產模型的能力上限 , 也為各行業智能化轉型提供了新一代強大的智能基座 。
然而 , 隨著模型體量不斷攀升 , 對應的基礎設施正面臨前所未有的挑戰 。 傳統集群架構在通信效率、I/O性能和系統擴展性等方面逐漸暴露出瓶頸 , 已難以滿足當前開源模型的部署需求 。
在這樣的背景下 , 各類“超節點”方案應運而生 。 作為面向大模型的新一代基礎設施架構 , 超節點通過在單系統內部集成更多GPU資源 , 并顯著優化節點間的通信性能 , 有效突破了傳統架構在大規模分布式計算中的性能瓶頸 。
昨日 , 浪潮信息正式發布了其面向萬億參數大模型的超節點AI服務器——“元腦SD200” 。 得益于浪潮信息自研的多主機低延遲內存語義通信架構 , SD200在單機內集成64路加速計算芯片 , 單機支持DeepSeek、Qwen、Kimi、GLM四大國產頂級開源模型同時運行 , 以及多智能體實時協作與按需調用 。
浪潮信息一直是開放計算生態的積極推動者 , 本次其此次推出的超節點方案采用了OCM+OAM的開放架構設計 , 兼容多款本土GPU芯片與大部分主流AI框架 , 目前已率先實現商用 。
在國產開源模型奮力追趕智能上限之際 , 浪潮信息的開放超節點 , 有望成為承載萬億參數模型的重要底座之一 。
一、廠商競相追逐超節點 , 開放架構需求凸顯在探討“超節點”對行業所帶來的深遠影響之前 , 我們有必要先厘清這一技術誕生的背景 。
首先 , 模型規模的持續膨脹正在逼近現有硬件的承載極限 。 大模型加速邁向萬億參數規模 , 同時上下文長度不斷擴展 , 直接推高了推理過程中的鍵值緩存(KV Cache)需求 。 顯存與帶寬 , 正成為壓在AI基礎設施之上的兩座大山 。
與此同時 , 隨著大模型加速進入千行百業 , 推理型負載成為主流計算模式 , 而推理是一種高度通信敏感的計算過程 。 以Qwen3-235B模型為例 , 若要實現100 tokens/s的解碼速度 , 單個token需完成多達188次的All-to-All通信 , 且每次通信的延遲必須控制在53微秒以內 。
更不容忽視的是 , Agentic AI的興起正在進一步拉高對計算系統的需求 。 具備自主規劃、多模態感知與連續執行能力的智能體 , 在執行任務時生成的token數量往往是傳統模型的數十倍甚至上百倍 , 動輒需要處理數十萬乃至數百萬token 。
算力基礎設施面臨的上述三大關鍵挑戰 , 使其走到升級重構的臨界點 。 為了支撐萬億參數級模型的高效運行 , 構建高度集成、低延遲、高帶寬的Scale-Up(縱向擴展)系統 , 即通過構建一個更大的高速互連域、形成“超節點” , 成為現實的技術選擇 。
通過構建超低延遲的統一顯存空間 , Scale-Up系統能將萬億級模型參數及激增的KV Cache整體容納于單一高速互連域內 , 保障了多芯片間高效協同執行 , 顯著減少跨節點通信開銷 , 從而大幅提升吞吐速度并降低通信延遲 , 實現降本增效 。
AI算力需求側的變化 , 正驅動供給側的廠商們爭相布局前沿的Scale Up方案 。 2024年 , 英偉達在GTC大會上提出SuperPod的概念;今年 , 國內廠商的方案更是將超節點引入大眾視野 。
當前 , 業界在超節點技術方案的選擇上 , 存在多種路徑 。 在浪潮信息看來 , 超節點要根據客戶應用需求來選擇技術路線 , 要給客戶提供更多算力方案的選擇 , 核心策略是“開放架構” 。
基于開放架構設計的超節點 , 能夠支持多樣化芯片、開放AI框架及主流開發工具 , 在保障高性能、低延遲的同時 , 實現跨平臺的良好兼容與靈活擴展 , 推動AI基礎設施真正走向開放、可持續的發展路徑 。
二、單機運行四大開源模型 , 全面支持主流框架昨日 , 浪潮信息在2025開放計算技術大會上正式發布元腦SD200超節點AI服務器 。 作為開放計算領域的重要風向標 , 該大會一向聚焦推動算力基礎設施的開放與協同 , 而SD200正是這一理念的典型體現 。
SD200基于OCM(開放算力模組)與OAM(開放加速模塊)兩大架構打造 。 OCM標準由中國電子技術標準化研究院發起 , 浪潮信息、百度等18家算力產業上下游企業共同參與編制 。
該架構圍繞CPU和內存進行解耦設計 , 具備高度模塊化與標準化優勢 , 支持系統供電、管理、風扇等組件的獨立升級與更換 , 大幅提升了服務器的靈活性與可維護性 。 同時 , OCM支持“一機多芯” , 可快速適配Intel、AMD、ARM等多種計算平臺 。
OAM則由開放計算項目(OCP)社區推動 , 是專為高性能計算與AI加速場景設計的開放模塊標準 。
該架構統一了加速卡的尺寸、電氣接口和散熱設計 , 使來自不同廠商的GPU、NPU等AI加速器可在同一系統中協同運行 , 并通過高速互聯技術實現加速卡之間的低延遲直連 , 有效滿足大模型訓練與推理對帶寬的極致要求 。
浪潮信息將OCM與OAM架構有機融合 , 為業界提供了一種開放的超節點技術架構 。
不過 , 光有“開放”的特性 , 仍不足以讓一款開放超節點方案獲得廣泛采用 , 性能同樣至關重要 。
在開放計算技術大會現場 , 浪潮信息副總經理趙帥曬出了SD200超節點在真實部署環境下實現的性能 。 在經過軟硬件的系統協同優化后 , SD200超節點滿機運行DeepSeek R1全參模型推理性能提升比為370% , 滿機運行Kimi K2全參模型推理性能提升比為170% 。
SD200超節點配備高達4TB的顯存 , 能夠同時容納DeepSeek、Qwen、Kimi、GLM等多個旗艦級開源模型 。 趙帥稱 , 這樣的顯存配置具備前瞻性 , 不僅可滿足當前萬億級模型的部署需求 , 甚至為未來可能出現的2萬億、3萬億參數模型預留了充足空間 。
然而 , 在打造這一方案時 , 浪潮信息并未一味追求技術堆疊 , 而是更注重實際落地的可行性 。 正如浪潮信息趙帥在發布會后與智東西等媒體交流時所提到的——客戶的核心訴求是“能否快速部署、快速上業務、上應用” 。
基于這一判斷 , SD200在使用便利性上進行了優化設計 。 例如 , 采用風冷散熱 , 企業無需改造機房 , 即可靈活部署;在互連方案上 , 則選擇了更為成熟穩健的全銅電互連 , 提升了系統穩定性 , 同時降低了終端用戶的運維復雜度和成本 。
此外 , SD200超節點還全面兼容當前主流的開源大模型計算框架(如PyTorch , 已支持2200+算子) , 可實現新模型的無縫遷移與“Day 0”上線 , 為企業構建AI應用提供了即開即用的基礎平臺 。
三、軟硬協同優化實現性能突破 , 揭秘開放超節點背后創新這樣一套開放超節點方案背后 , 是浪潮信息在融合架構和軟硬件協同方面長達十余年的深厚積累 。
趙帥分享道 , 自2010年起 , 浪潮信息持續推進融合架構演進 , 從最初的供電、散熱等非IT資源的整合 , 到存儲、網絡等資源池化 , 再到最新融合架構3.0系統實現了計算、存儲、內存、異構加速等核心IT資源徹底解耦和池化 。
這沉淀下來的芯片共享內存數據、統一編址技術、池化、資源動態調度等技術 , 在今天的超節點系統中得以延續和應用 , 顯著提升了系統的適配速度與商用效率 。
此外 , 浪潮信息并非單純的硬件廠商 , 其在大模型領域同樣具備深度布局——早在2021年即發布首個中文巨量模型“源1.0” , 其參數規模達2457億 , 并持續在模型訓練、推理優化和軟硬件協同方面積累經驗 。 這些能力也為SD200這樣的超節點方案提供了堅實基礎 。
為突破萬億大模型的帶來的顯存壓力 , SD200超節點基于浪潮信息自主研發的開放總線交換(Open Fabric Switch)技術 , 首創多主機三維網格系統架構(3D Mesh) 。 在這一架構下 , 64顆本土GPU能夠以高速、低延遲的方式實現互連 。
更進一步 , SD200通過GPU虛擬映射等底層創新 , 解決了多主機環境下統一編址的難題 , 將顯存統一地址空間擴增8倍 , 顯存容量達4TB , 配合64TB系統內存 , 為超大模型提供了充足的KV緩存資源 。
這意味著 , 不論是在模型訓練還是推理過程中 , 開發者都能像調用單機GPU一樣 , 靈活調度整個系統中的算力與顯存資源 , 極大簡化了工程復雜度 。 實測結果表明 , 在推理過程常見的小數據包通信場景中 , 全規約(All Reduce)性能表現優異 , 顯著提升計算與通信效率 。
在系統層面 , 浪潮信息圍繞萬億參數大模型計算密集、通信敏感的特性 , 構建起一整套軟硬協同優化的系統方案 , 將64卡超節點的算力潛能釋放到極致 。
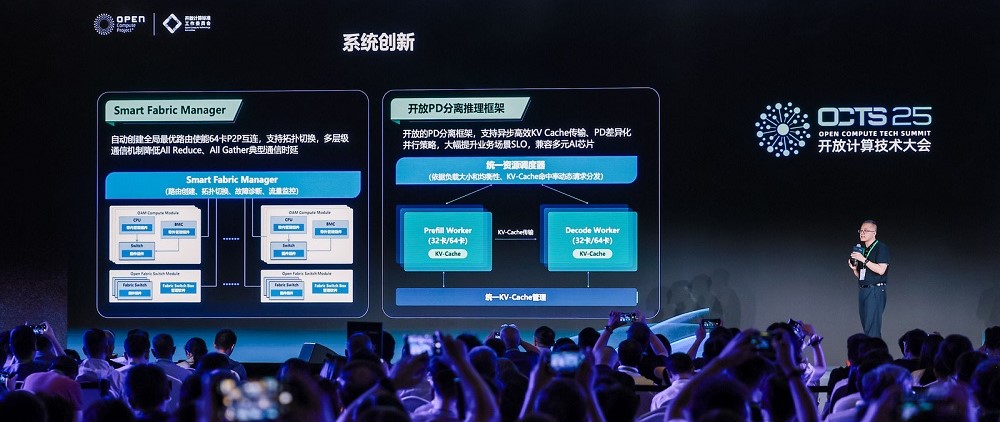
一方面 , 浪潮信息開發了智能總線管理系統 , 可實現超節點64卡全局最優路由的自動創建與管理 。 該系統不僅支持靈活拓撲切換 , 還能根據業務負載動態進行資源切分與調度 , 為不同類型的大模型任務提供定制化的算力編排能力 。
針對All Reduce、All Gather等典型通信算子的不同數據包規模 , 系統設計了細粒度、多層級的通信策略 , 進一步壓縮通信路徑的延遲 。
此外 , SD200還引入了開放的PD分離框架 , 將預填充-解碼(Prefill-Decoder)環節解耦 , 支持異步KV Cache高效傳輸 , 并允許針對不同模型并行需求制定差異化策略 , 兼顧性能與兼容性 。 這一設計不僅提升了系統性能 , 也保障了對多元算力架構的適配能力 , 加強了計算與通信之間的協同優化 。
通過軟硬協同系統創新 , SD200成功實現了縱向擴展 , 幫助本土AI芯片突破了性能邊界 , 在大模型場景中展示出優異的性能表現 。
結語:開放超節點 , 帶動產業鏈協同創新在趙帥的分享中 , 智東西感受到了浪潮信息對“以應用為導向”的堅持 。 作為系統廠商 , 他們與終端客戶的距離更近 , 也更能體會到實際應用場景的痛點 。 也因此 , 趙帥稱 , 超節點架構本質上是系統化思維的產物 , 它不是某一個點的突破 , 而是在現有技術、生態和成本約束下 , 從系統層面去打破芯片本身的性能邊界 , 最大化用戶價值 。
超節點的發展也為中國本土產業鏈提供了發展機遇——高速連接器、線纜、板材、電源等上下游產業鏈廠商 , 都有望這個過程中找到屬于自己的突破點 。 這不僅能加速成本下降和技術普惠 , 更推動了智能基礎設施的“平權化” 。
放眼未來 , 趙帥認為 , AI數據中心正從“機柜級密度革命”邁向“數據中心級系統工程挑戰” , 算力密度將持續攀升 , 能源供給、冷卻方式和系統管理也隨之進入全面革新期 。
【單機支持超萬億參數模型!浪潮信息發布超節點,給開源AI打造開放底座】從芯片到架構 , 從系統到生態 , 技術演進注定不會是一條單線道路 , 而是多路徑的協同創新 。 在這場關于未來的集體奔赴中 , 唯有持續開放、擁抱合作 , 才能構筑真正普惠、可持續的智能算力基石 。
推薦閱讀













- 黑科技產品層出不窮!天馬在DIC 2025亮出超多創新顯示成果
- 法國科研中心發布醫學文本AI識別系統:超越專有軟件的開源突破
- 小米16 Pro Max再次被確認:直屏+超大尺寸副屏,或是安卓之光!
- 一加13性能影像雙旗艦,2K超清屏幕亮度領先行業
- 蘋果自研影像傳感器曝光:iPhone或超電影機,口袋里就是大片神器
- 雷軍揚眉吐氣,小米在歐洲終于超過蘋果,成第二名了
- 小折疊屏殺手?小米全新直板旗艦或回歸副屏設計,屏幕尺寸超大
- 16英寸超薄+17小時續航!體驗戴爾16 Plus
- 搶先紅米15C!榮耀最強五百檔超廉價新機發布:三年不卡!
- 閃電快訊|京東持續押注具身智能,將在智能機器人領域投入超百億資源