
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
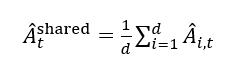
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片
本文的第一作者是董冠霆 , 目前就讀于中國人民大學高瓴人工智能學院 , 博士一年級 , 導師為竇志成教授和文繼榮教授 。 他的研究方向主要包括大語言模型推理 , 多智能體強化學習、深度搜索智能體等 。 在國際頂級會議如 ICLR、ACL、AAAI 等發表了多篇論文 , 并在快手大模型應用組、阿里通義千問組等大模型團隊進行實習 。 其代表性工作包括 AUTOIF、Tool-Star、RFT、Search-o1、WebThinker、Qwen2 和 Qwen2.5 等 。 本文的通信作者為中國人民大學的竇志成教授與快手科技的周國睿 。
在可驗證強化學習(RLVR)的推動下 , 大語言模型在單輪推理任務中已展現出不俗表現 。 然而在真實推理場景中 , LLM 往往需要結合外部工具進行多輪交互 , 現有 RL 算法在平衡模型的長程推理與多輪工具交互能力方面仍存在不足 。
為此 , 我們提出了全新的 Agentic Reinforced Policy Optimization(ARPO)方法 , 專為多輪交互型 LLM 智能體設計 。
ARPO 首次發現模型在調用外部工具后會推理不確定性(高熵)顯著增加的現象 , 并基于此引入了熵驅動的自適應 rollout 策略 , 增強對高熵工具調用步驟的探索 。 同時 , 通過引入優勢歸因估計 , 模型能夠更有效地理解工具交互中各步驟的價值差異 。 在 13 個計算推理、知識推理和深度搜索等高難基準上 , ARPO 在僅使用一半工具調用預算的情況下 , 仍顯著優于現有樣本級 RL 方法 , 為多輪推理智能體的高效訓練提供了可擴展的新方案 。
論文標題:Agentic Reinforced Policy Optimization 論文鏈接:https://arxiv.org/abs/2507.19849 代碼倉庫:https://github.com/dongguanting/ARPO 開源數據模型:https://huggingface.co/collections/dongguanting/arpo-688229ff8a6143fe5b4ad8ae目前不僅在 X 上收獲了超高的關注度 , 同時榮登 Huggingface Paper 日榜 , 周榜第一名!
研究動機:
抓住工具調用后的高熵時刻
近年來 , 可驗證獎勵的大規模強化學習在單輪推理任務中充分釋放了前沿大語言模型的潛力 , 表現亮眼 。 然而 , 在開放式推理場景下 , LLM 不僅需要具備長程規劃與自適應決策能力 , 還需與外部工具進行動態的多輪交互 。 這催生了 Agentic RL 這一新范式 , 將訓練從靜態求解轉向動態的智能體 - 環境推理 。 現有 Agentic RL 方法多采用樣本級算法(如 GRPO、DAPO) , 在固定特殊 token 下獨立采樣完整的工具調用軌跡 , 并基于最終輸出獎勵模型 。 但這種方式常因獎勵稀疏、工具過用等問題導致多輪交互價值被低估 , 忽視了工具調用過程中每一步的細粒度行為探索 。
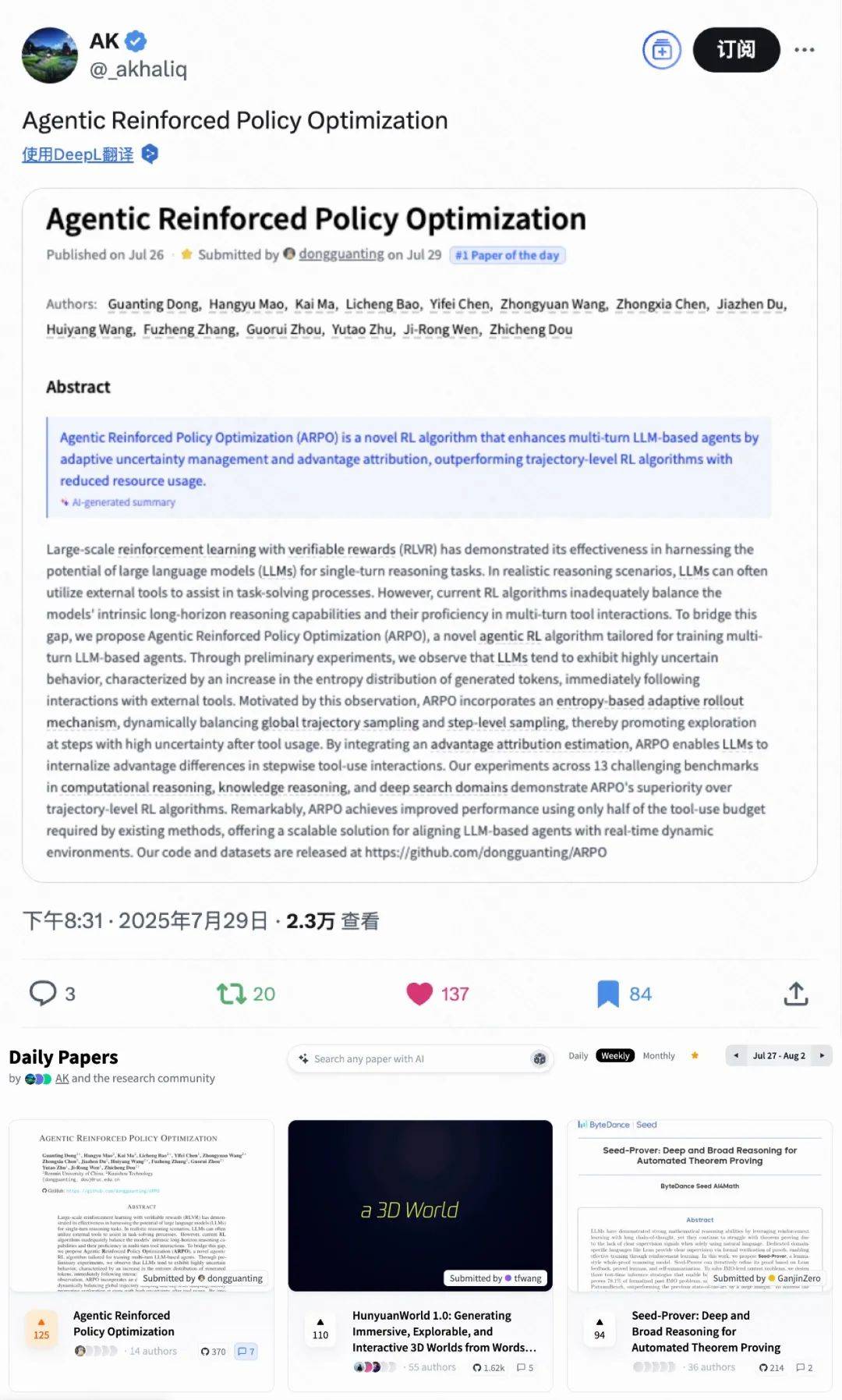
通過對 LLM 在深度搜索任務中的 token 熵分布進行分析 , 研究發現模型在每次工具調用后的初始生成階段熵值顯著升高 , 說明外部工具反饋會引入高不確定性 , 而這正是現有方法未充分利用的探索契機 。
圖 1:左圖展示大模型在調用工具后的高熵現象 , 右圖對比 ARPO 與基線性能
ARPO 框架:訓練模型自主實現推理時的多工具調用
針對上述發現 , 我們提出 Agentic Reinforced Policy Optimization(ARPO) , 核心思想是在高熵工具調用步驟中 , 自適應地分支采樣 , 探索更多多樣化的推理路徑 。 具體來說 , 我們的貢獻如下:
我們量化了 LLM 在 Agentic 推理過程中的 token 熵變化 , 揭示了樣本級 RL 算法在對齊 LLM 智能體方面的固有限制 。 我們提出了 ARPO 算法 , 引入基于熵的自適應 rollout 機制 , 在保持全局采樣的同時 , 在高熵工具調用步驟中鼓勵分支采樣 。 此外 , ARPO 結合優勢歸因估計 , 幫助 LLM 更好地內化步驟級工具使用行為中的優勢差異 。 除了啟發式動機 , 我們還從理論上論證了在 LLM 智能體訓練中引入 ARPO 算法的合理性 。 在 13 個高難基準上的實驗表明 , ARPO 在僅使用一半工具調用訓練預算的情況下 , 性能穩定優于主流 RL 算法 , 為探索 Agentic RL 提供了可行性參考與實踐啟示 。工具調用的熵變現象:高熵時刻與探索困境
圖 2:跨數據集分析基于 LLM 的工具使用智能體的 token 熵變化與 token 頻率分布
通過分析大型模型在結合工具執行復雜搜索與推理任務時的 token 熵值 , 我們發現以下幾點:
1. 在每次工具調用后的前 10–50 個 token 內 , 熵顯著上升 。
2. 在推理的初始階段 , 熵往往會增加 , 但仍低于大模型接收到工具調用反饋后的水平 。
3. 搜索引擎的反饋引入的熵波動比代碼編譯器的執行反饋更大 。
這些現象可以歸因于外部反饋與模型內部推理之間的 token 分布轉移 , 這甚至導致引入的推理不確定性超過原始輸入的問題 。 此外 , 搜索引擎通常提供豐富的文本內容 , 而代碼編譯器輸出則由確定性的數字組成 , 這導致前者的熵波動更大 。
工具設計:多樣化工具支撐 Agentic 推理
本研究聚焦于優化基于 LLM 的工具使用智能體的訓練算法 。 在梳理現有 Agentic RL 研究后 , 我們選取三類具有代表性的工具 , 用于實證評估 ARPO 的有效性:
搜索引擎:通過執行網絡搜索查詢檢索相關信息 , 支持本地及在線模式 。 網頁瀏覽智能體:訪問并解析搜索引擎返回的網頁鏈接 , 提取并總結關鍵信息以響應查詢 。 代碼解釋器:自動執行 LLM 生成的代碼 , 若執行成功則返回結果 , 否則返回編譯錯誤信息 。這些工具覆蓋信息檢索、內容解析與程序執行等多類功能 , 為多輪交互與復雜推理場景提供了強有力的支撐 。
ARPO 算法:利用熵信號指導 LLM 逐步優化工具調用
基于熵的自適應 rollout 機制
ARPO 的核心思想在于結合全局采樣與熵驅動的局部采樣 , 在模型工具調用后不確定性升高的階段加大探索力度 , 從而提升推理效果 。 其基于熵的自適應 rollout 機制包含四個關鍵步驟:
圖 3:ARPO 的基于熵驅動的自適應 rollout 機制 , 結合全局探索與局部高熵節點分支
【ARPO:智能體強化策略優化,讓Agent在關鍵時刻多探索一步】1. Rollout 初始化
2. 熵變監控
3. 基于熵的自適應分支
模型的分支決策如下:
該機制將探索資源自適應分配到熵上升區域 , 這些區域往往蘊含更高的信息增益 。
4. 終止條件
Rollout 過程持續進行 , 直到分叉路徑數達到預算上限 M-N(停止分支并完成采樣)或所有路徑提前終止 。 若預算仍有剩余 , 則補充全局采樣以覆蓋更全面的推理空間 。
優勢歸因估計
ARPO 的熵驅動自適應 rollout 會產生包含共享推理片段和分支路徑的軌跡 , 這啟發我們優化策略更新方式 , 更好地利用步驟級工具調用信息 。
兩種優勢估計方式
1. 硬優勢估計(Hard)
明確區分共享和分支 token , 對共享部分計算平均優勢 , 對分支部分單獨計算:
對分支 token 的優勢估計:
對共享 token 的優勢估計:
2. 軟優勢估計(Soft)
其中重要性采樣比率:
實驗結果證明軟優勢估計在 ARPO 訓練中能穩定獲得更高獎勵 , 故將其設為默認優勢估計方法 。
分層獎勵設計
ARPO 的獎勵函數綜合考慮答案正確性、工具調用格式及多工具協作 。如果模型在推理中使用了搜索(search)和代碼(python)等多種工具 , 并保證答案正確且格式合規 , 會獲得額外獎勵 , 公式如下:
其中:
通過軟優勢估計與分層獎勵機制 , ARPO 在訓練中能更平穩、更高效地優化多輪工具使用策略 。
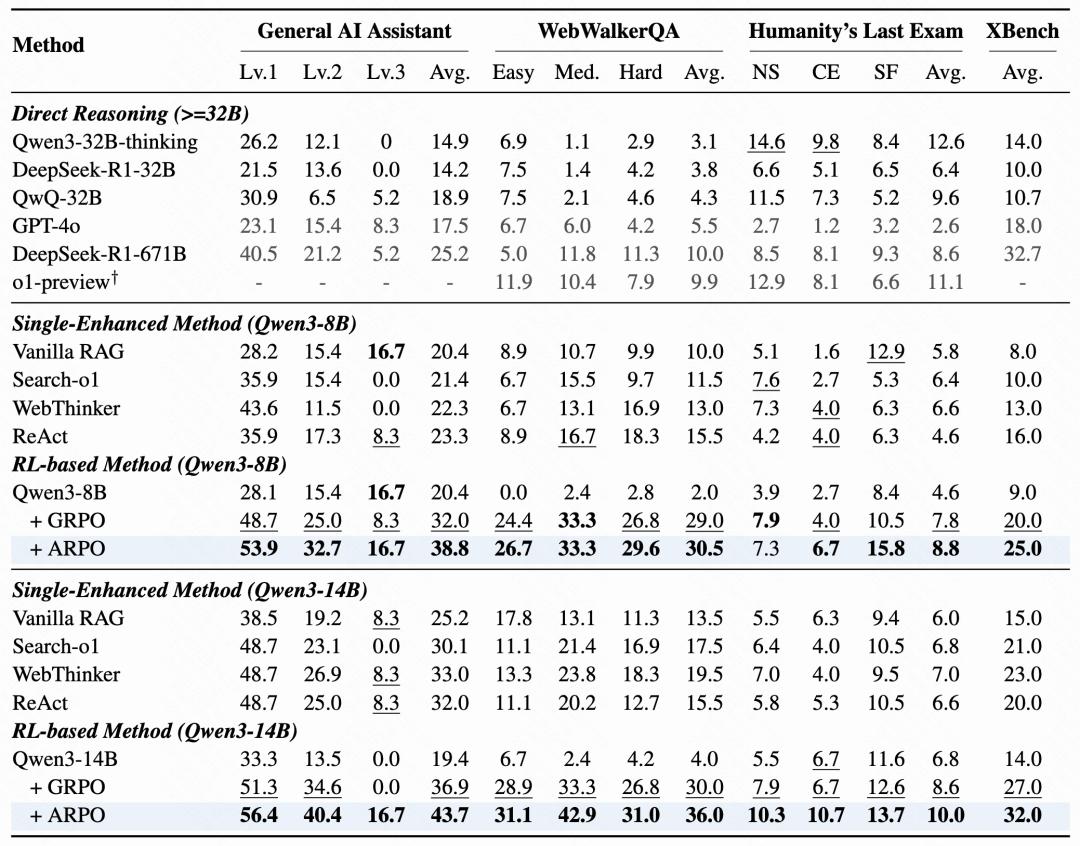
實驗結果:10 + 綜合推理任務評測
為了充分評估 ARPO 的泛化性和高效性 , 我們考慮以下三種測試集:
? 計算型推理任務:評估模型的計算推理能力 , 包括 AIME24 , AIME25 , MATH500 , GSM8K , MATH 。
? 知識密集型推理任務:評估模型結合外部知識推理的能力 , 包括 WebWalker , HotpotQA , 2WIKI , MisiQue , Bamboogle 。
? 深度搜索任務:評估模型的深度搜索能力 , 包括 HLE , GAIA , SimpleQA , XBench 。
從實驗結果可以發現:
ARPO 整體表現優于主流方法:ARPO 在大部分任務上準確率高于 GRPO、DAPO 等樣本級 RL 方法 , 在工具調用密集任務(如 GAIA、HLE)中提升幅度更明顯 。 多任務保持穩定性能:ARPO 在計算、知識與搜索任務中均保持較好的表現 , 沒有明顯性能短板 , 驗證其跨任務的適配能力 。實驗:采樣分析與工具調用效率評估
多輪采樣能力提升模型表現
由于 Deepsearch 任務具有動態、多輪交互的特點 , 單純使用 Pass@1 指標難以全面反映模型的工具調用潛力 。 我們進一步分析了 Pass@3 和 Pass@5 指標 , 發現無論是 8B 還是 14B 規模模型 , 在經過 ARPO 對齊訓練后 , 均表現出持續提升和良好的規模效應 。 其中 , 14B 模型在 Pass@5 指標上表現尤為出色:
GAIA 達到 61.2% HLE 達到 24.0% XBench-DR 達到 59%工具調用效率顯著提升
在 Agentic RL 訓練中 , 工具調用次數直接影響成本 。 我們以 Qwen2.5-7B 模型為例 , 將 ARPO 與 GRPO 方法進行對比:
ARPO 在整體準確率上優于 GRPO 同時僅使用了約一半的工具調用次數
這得益于 ARPO 獨特的基于熵的自適應采樣機制 , 僅在高熵工具調用步驟進行分支采樣 , 極大地擴展了工具行為的探索空間 , 同時降低了不必要的調用 。
總結與未來展望
ARPO 算法有效提升了多輪工具推理代理的性能 , 解決了現有樣本級 RL 方法在多輪交互中探索不足、泛化能力欠缺的問題 。 通過熵驅動自適應采樣和優勢歸因機制 , ARPO 能夠在工具調用頻繁、推理路徑復雜的任務中實現更高效、更穩定的輸出 。 未來 , 為持續提升 Agentic RL 模型的能力 , 仍有多個方向值得探索:
多模態 Agentic RL:ARPO 目前主要針對文本推理任務 , 在處理圖像、視頻等多模態信息方面仍有局限 。 未來可擴展至多模態任務中 , 探索模型在多模態場景下的工具調用與策略優化 。 工具生態擴展:ARPO 已經驗證了在多工具協作任務上的潛能 。 未來可引入更多類型的外部工具(如代碼調試器、數據分析工具、實時 API 調用等) , 并通過工具使用策略優化進一步提升復雜任務表現 。 大規模與實時部署:ARPO 展示了較高的訓練效率和推理泛化性 , 未來可探索在更大規模模型和實時動態環境中的部署與適配 , 降低成本同時提升實用價值 。
推薦閱讀













- 一句話查數據,效率提升百倍!對話大華股份周明偉解局AIoT智能體落地潮
- 對話丨禾賽科技劉興偉:激光雷達降本加速智能車與機器人場景滲透
- 千元機也有流暢性能體驗 榮耀X70游戲性能評測
- 陷入瓶頸還是黎明前的黑暗,聊聊智能手表芯片
- HBM4,路線各不同
- 紅米K90系列再次被確認:一體冷雕玻璃+LTPS屏,Deco花活兒引期待!
- 再見了,實體卡!華為首推,蘋果跟進,三大運營商重啟eSIM
- 「貼地飛行」:大疆 ROMO 掃地機器人首發體驗
- 誰說性能手機拍照就很差?iQOO Z10 Turbo+影像體驗分享
- 今年“618”具身機器人銷售額增長17倍!京東發布智能機器人產業加速計劃