
文章圖片
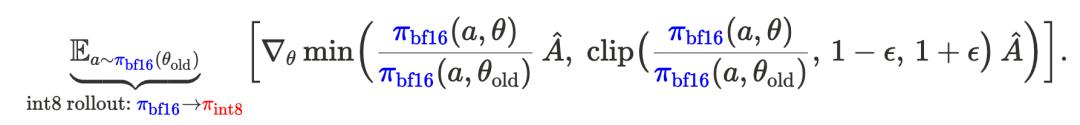
文章圖片

文章圖片

文章圖片
文章圖片
機器之心報道
編輯:冷貓
在今年三月份 , 清華 AIR 和字節聯合 SIA Lab 發布了 DAPO , 即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪輯和動態采樣策略優化) 。 這是一個可實現大規模 LLM 強化學習的開源 SOTA 系統 , 使用該算法 , 該團隊成功讓 Qwen2.5-32B 模型在 AIME 2024 基準上獲得了 50 分 , 我們也做了相關報道 。
論文地址:https://dapo-sia.github.io/static/pdf/dapo_paper.pdf 代碼地址:https://github.com/volcengine/verl/tree/gm-tyx/puffin/main/recipe/dapo中國科學技術大學校友 , 伊利諾伊大學香檳分校博士 , 微軟研究院的首席研究員劉力源、清華大學校友 , 加州大學圣地亞哥分校計算機科學與工程學院博士生姚峰團隊在強化學習的研究中更進一步 。
該團隊發現 , 在 DAPO-32B 中 , rollout 生成是強化學習訓練的主要瓶頸 , 占據了約 70% 的總訓練時間 。 因此 , 該團隊從 rollout 階段著手 , 將 8 bit 量化技術應用于 rollout 生成 , 并通過 TIS 技術在保持下游性能的同時實現了顯著加速 。
眾所周知 , FP8 能讓強化學習運行得更快 , 但往往以性能下降為代價 。
劉力源、姚峰團隊推出 FlashRL , 是首個開源且可用的強化學習實現方案 , 在推理執行(rollout)階段應用 INT8/FP8 , 并且在性能上與 BF16 持平 , 沒有性能損失 。 該團隊在博客中完整發布了該方法的技術細節 。
博客標題:FlashRL: 8Bit Rollouts Full Power RL 博客地址:https://fengyao.notion.site/flash-rl 代碼地址:https://github.com/yaof20/Flash-RLRollout 量化可能會降低性能
如圖 1 和圖 2 中 「?????」 曲線所示 , 在未使用 TIS 技術的情況下 , 采用 FP8 或 INT8 進行 rollout 量化 , 相比 BF16 rollout 會帶來顯著的性能下降 。
這一現象是預期中的 , 因為 rollout–訓練之間的差異被放大了:rollout 是從量化策略 π_int8 采樣的 , 但梯度卻是基于高精度策略 π_bf16 計算的 。
這種不匹配會使強化學習過程更加偏離策略 , 從而削弱強化學習訓練的有效性 。
圖 1 左圖:吞吐量加速比 。 FP8 結果在 H100 上測試;INT8 結果分別在 H100 和 A100 上測試 。 結果基于不同的響應長度和設備測得 。 右圖:Qwen2.5-32B 模型在使用 BF16 rollout 與 INT8 rollout 時的 AIME 準確率對比 。 所有實驗均采用 BF16 FSDP 訓練后端 。
FlashRL 的獨門秘訣
FlashRL 是首個開源且可用的強化學習方案 , 能夠在不犧牲下游性能的前提下使用量化 rollout 。
那么 , 它的「獨門秘訣」是什么呢?
解決 Rollout–訓練不匹配問題
該團隊引入了截斷重要性采樣(Truncated Importance Sampling , TIS)來減輕 rollout 與訓練之間的差距 。 正如圖 1 和圖 2 中的實線所示 , TIS 使量化 - rollout 訓練的性能達到了與采用 TIS 的 BF16 rollout 訓練相同的水平 —— 甚至超過了未使用 TIS 的樸素 BF16 rollout 訓練 。
作者團隊之前發表過有關 TIS 的技術博客 , 感興趣的讀者可以參考:
博客標題:Your Efficient RL Framework Secretly Brings You Off-Policy RL Training 博客鏈接:https://fengyao.notion.site/off-policy-rl在這里簡單展示一下 TIS 的工作原理 。
支持在線量化
現有的推理引擎(如 vLLM)針對大語言模型推理服務進行了優化 , 但在支持帶參數更新的模型量化方面能力有限 。 該團隊提供了 Flash-LLM-RL 包 , 對 vLLM 進行了補丁 , 使其能夠支持這一功能 。
如圖所示 , FlashRL 的 INT8 可帶來高達 1.7 倍的吞吐量提升 , 同時保持 RL 的優勢 。 此外 , 如果不使用 TIS 而使用 naive FP8/INT8, 性能將顯著下降 。
圖 2 左圖與中圖:在使用量化 rollout 生成的強化學習大語言模型訓練中 , GSM8K 的準確率表現 。 請注意 , TIS 對緩解分布差異至關重要 。 右圖:π_fsdp 與 π_vllm 之間的 KL 散度 。 需要注意的是 , INT8 rollout 的 KL 散度大于 FP8 rollout 的 KL 散度 。
FlashRL 能有多快?
比較在強化學習訓練中采用不同 rollout 精度的吞吐量并不簡單 , 因為模型會不斷更新 , 對于同一個查詢 , 不同的量化策略在經過一定的 RL 訓練迭代后可能會生成長度不同的回復 。
這里將探討 FlashRL 所實現的加速效果及其對訓練效果的影響 。
Rollout 加速表現
常規環境下的加速:
研究團隊記錄了在 7B、14B 和 32B Deepseek-R1-Distill-Qwen 模型上使用 INT8、FP8 和 BF16 精度的 rollout 吞吐量 。
圖 1 顯示了 8 位量化模型相對于 BF16 的加速比 。 對于較小的 7B 模型 , 加速比不足 1.2×;而在 32B 模型上 , 加速比可達 1.75× 。 這表明量化對大模型的收益遠高于小模型 。 基于分析結果 , 團隊建議僅在模型規模超過 140 億參數時使用量化 。
內存受限環境下的加速:
研究團隊還評估了在標準推理場景(不涉及 RL)下 , 采用 8 位量化所能帶來的吞吐量提升 。 具體而言 , 團隊測量了 INT8 的加速比 , 作為壓力測試 , 用于驗證其在 A100/A6000 和 H100 GPU 上的適用性 。
使用 vLLM 在相同數據集上分別服務 BF16 與 INT8 量化版本的 Deepseek-R1-Distill-Qwen-32B 模型 , 并在 A100/A6000 和 H100 GPU 上記錄其吞吐量 。
圖 3 在 4 種僅推理配置下 , INT8 量化的 Deepseek-R1-Distill-Qwen-32B 相對于 BF16 的吞吐量加速比 , 測量結果涵蓋不同回復長度 。
如圖 3 所示 , 當 GPU 內存成為瓶頸時 , 量化能夠帶來極高的加速比 —— 在 TP2-A6000 配置下生成速度提升超過 3 倍 , 在 TP1-A100 配置下提升甚至超過 5 倍 。 這突顯了量化在 GPU 內存受限場景(如服務更大規模模型)中的巨大潛力 。
端到端加速與效果驗證
研究團隊將 FlashRL 部署于 DAPO-32B 的訓練中 , 以驗證所提方法的有效性 。 由于在圖 2 中 FP8 相比 INT8 擁有更小的分布差距 , 特意選擇 INT8 作為更具挑戰性的測試場景 。
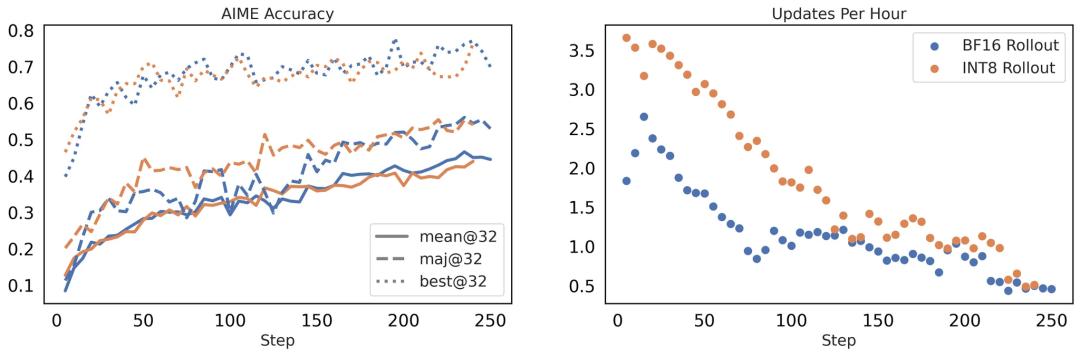
圖 4 展示了在 BF16 與 INT8 rollout 下的下游性能與訓練加速效果 。 兩種配置在 AIME 基準上的準確率相當 , 但 INT8 顯著提高了訓練速度 。
這些結果證明 , FlashRL 能在不犧牲訓練效果的前提下 , 實現顯著的訓練加速 。
圖 4. 左圖:使用 BF16 與 INT8 rollout 精度進行強化學習訓練的下游性能對比 。 右圖:BF16 與 INT8 rollout 在單位小時內可完成的更新步數 。 所有實驗均基于 DAPO 配方 , 在 Qwen2.5-32B 模型上進行 , 訓練 250 步 , 硬件配置為 4 個節點、每節點配備 8 張 H100 GPU 。
快速使用
使用 FlashRL 只需一條命令! 使用 pip install flash-llm-rl 進行安裝 , 并將其應用于你自己的 RL 訓練 , 無需修改你的代碼 。
FlashRL 方法支持 INT8 和 FP8 量化 , 兼容最新的 H100 GPU 以及較老的 A100 GPU 。
【讓強化學習快如閃電:FlashRL一條命令實現極速Rollout,全部開源】更多方法細節 , 請參閱原博客 。
推薦閱讀










- 華為讓出高利潤,512GB+衛星消息+6100mAh,國補后熱銷“賣斷貨”
- ARPO:智能體強化策略優化,讓Agent在關鍵時刻多探索一步
- 谷歌攤牌:Genie 3讓你1秒「進入」名畫,人人可造交互世界
- 韓國大學推出CoTox:讓AI像毒理學專家一樣思考藥物毒性
- 騰訊發布X-Omni:強化學習讓離散自回歸生成方法重煥生機
- AI不會讓你成為10倍工程師
- 1799元?紅米這新機一發,讓友商怎么打
- 5000毫安!三星連續用了六代,算法升級讓擠牙膏更瘋狂
- 想實現鴻蒙應用性能翻倍?華為兩大“神器”,讓頁面滑動“零等待”
- 為新機讓路!華為多款新機大降價,是選擇還是做等等黨?