文章圖片
文章圖片
機器之心報道
機器之心編輯部
前期有多期望 , 后期就有多失望 , 這大概是大多數業界人士在看到 GPT-5 這場事先張揚的高調發布后的最大心聲 。
當然 , 也許在內部測試的時候 , OpenAI 確實覺得 GPT-5 是目前最為強大的模型 , 可是走進真實世界后卻好像并非如此 。
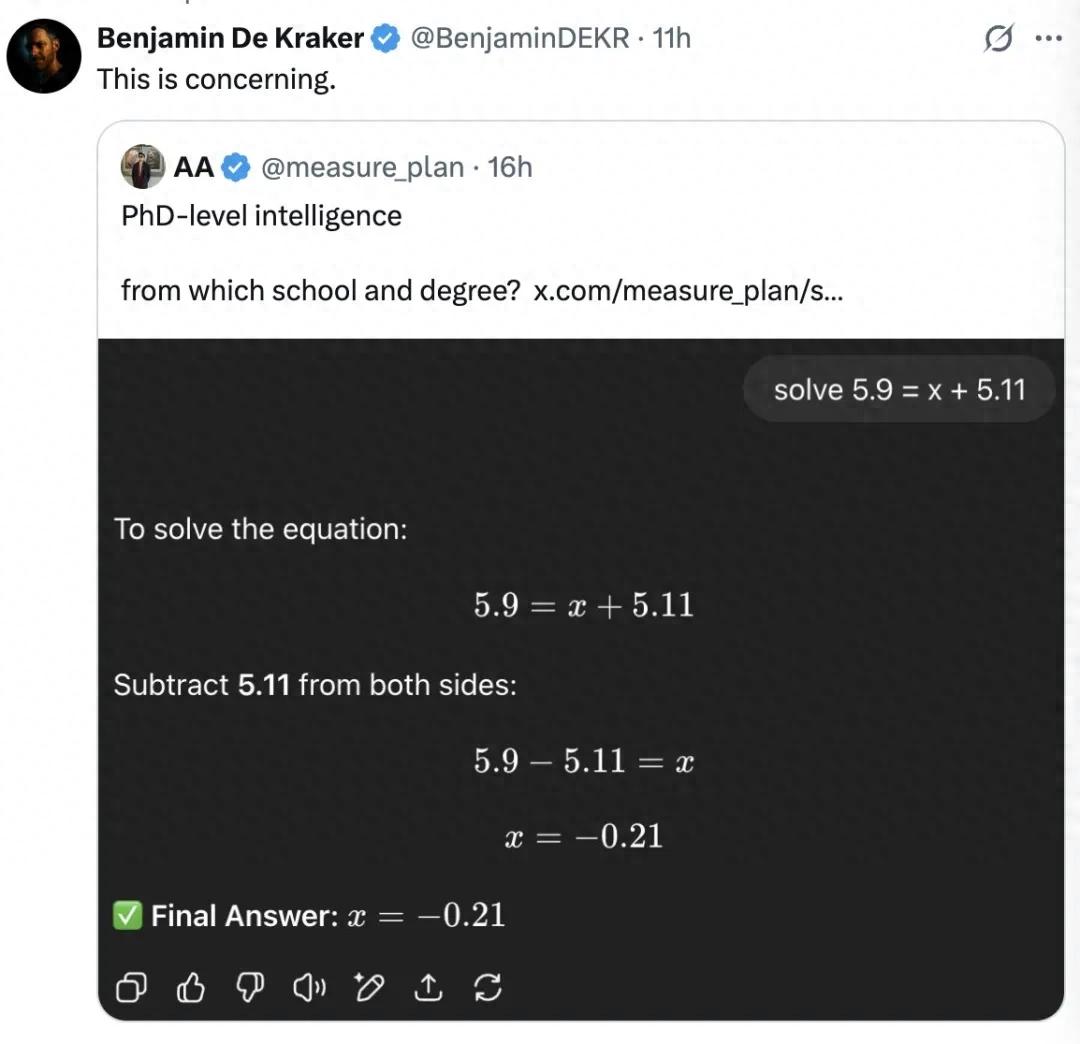
一位 X 網友發現 GPT-5 在解決可能屬于小學水平的數學題時無能為力 , 吐槽到底被官方稱為「博士」水平的智力是哪個學校頒發的?
不僅是數學 , 自 GPT-5 發布以來 , 各種社交媒體上充斥著各種 GPT-5 在邏輯、編碼任務中「失誤」的案例 。
前期的高調炒作、直播中的低水準圖表錯誤、用戶試用后的失望 , 等等 , 不僅讓 GPT-5 沒有收到預期的鮮花與掌聲 , 更多是吐槽和質疑聲的時候 , OpenAI 聯合創始人兼首席執行官 Sam Altman 似乎也開始「坐不住了」 , 表示 GPT-5 的發布過程確實存在一點問題 。
GPT-5 發布后不久 ,在 Reddit r/ChatGPT 的 AMA 活動中 , Sam Altman 和 GPT-5 團隊核心成員針對網友們的提問進行了回答 , 從發布會上出現的令人尷尬的「圖表犯罪」失誤 , 到用戶抱怨 GPT-5 效果不如 4o 好 , 趕緊將 4o「還回來」等等 , Sam Altman 都一一做出了解釋 , 并給出后續的解決方案 。
首先是大家最為關心的版本問題 , GPT-5 發布后不久 , 用戶的 ChatGPT 頁面就開始陸續出現 GPT-5 版本 , 但令人不解的是 , 同時 4o 等其他選項都沒有了 , 但由于 GPT-5 的性能并沒有說得那么好 , 于是大家并沒有因為率先用上新模型而高興 , 反而是希望換回來 。
一網友在 Reddit 上提問:「請把 4o 帶回來吧 。 不要移除不同的版本 —— 不同的人有不同的風格!」
Sam Altman 則表示:「好的 , 我們聽到了大家對 4o 的反?。 桓行荒忝腔ㄊ奔涮岢鲆餳ɑ褂姓夥萑惹椋 。 ?。 我們會讓 Plus 用戶重新使用 4o , 并會觀察使用情況來決定支持多久 。 」
另一位網友表示希望 ChatGPT 能夠給用戶在使用 GPT-5 的同時使用 GPT-4o/4.1 的權利 。 Sam Altman 回答說 , 團隊正在研究這個問題 , 并問網友覺得必須同時保留 4o 和 4.1?還是只保留 4o 就夠了?
目前的結果是 , OpenAI 部分撤回其平臺的一些更改并恢復用戶對 GPT-4o 等早期模型的訪問權限 。 詳情可參閱報道《用戶痛批 GPT-5 , 哭訴「還我 GPT-4o」 , 奧特曼妥協了》 。
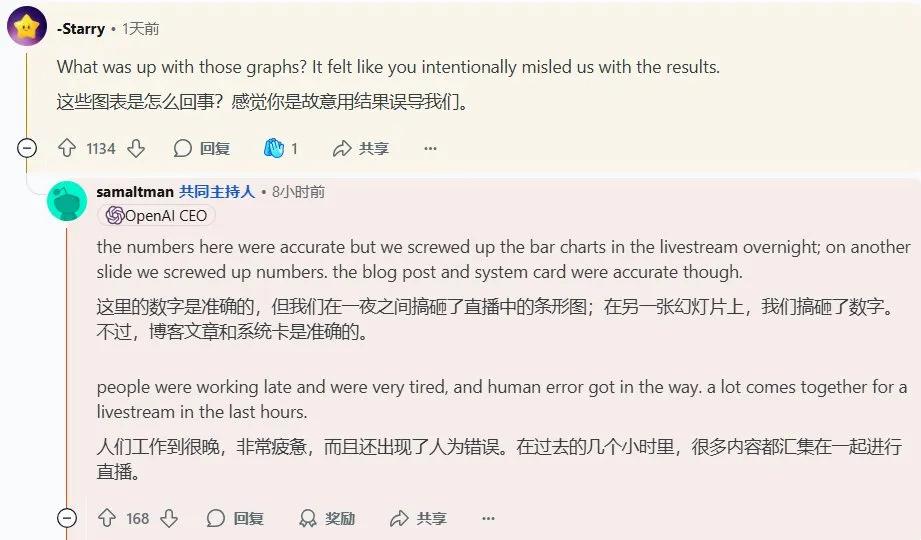
而不出所料 , Sam Altman 也被問到了發布直播上令人尷尬的一幕 , 展示出模型性能圖表出現「錯誤」—— 該圖表顯示的基準分數較低 , 但條形圖卻很高 。
這一幕出現后 , 很多網友表示號稱史上最強大的模型怎么能犯如此低級的錯誤 , 甚至一位 X 網友調侃道 , 「在看到這張圖片后 , 感覺自己的工作保住了!」
對此 , Sam Altman 表示 , 為了準備發布會 , 團隊成員大家都工作到很晚 , 非常疲憊 , 人為錯誤造成了這樣的影響 。
另外 , Sam Altman 還在這次 AMA 中進行了一些總結 , 并分享了 OpenAI 對于未來的一些規劃:
「感謝你們在這里提供的所有反饋 。
正如我們之前提到的 , 由于我們同時推出這么多產品 , 所以預料到會有一些波折 。 但結果比我們預想的還要坎坷!
一些變化:
從今天開始 , GPT-5 會變得更加智能 。 昨天 , 我們遇到了一次安全事件 , 自動切換器在當天的大部分時間里都無法使用 , 結果導致 GPT-5 看起來變得非常笨拙 。 此外 , 我們正在對決策邊界的運作方式進行一些干預 , 這應該有助于你更頻繁地獲得正確的模型 。 我們將更加透明地展示哪個模型正在回答給定的查詢 。
向所有人推出需要更長的時間 。 這是一次規模巨大的變革 。 例如 , 我們的 API 流量在過去 24 小時內幾乎翻了一番……
我們將改變用戶界面 , 以便更容易地手動觸發思考 。
我們將在推出完成后將 Plus 用戶的速率限制提高一倍 。
我們正在考慮讓 Plus 用戶繼續使用 4o 。 我們正在嘗試收集更多有關利弊的數據 。
我們將繼續努力使事情穩定下來 , 并將繼續聽取反饋 。 」
下面是 Sam Altman 和 GPT-5 團隊核心成員在這次 Reddit AMA 中的更多詳細有趣問答:
Sam Altman
OpenAI CEO
問:請恢復 4o 。 不要刪除變體模型 —— 每個人的風格都不一樣!
Altman:好的 , 我們聽到了大家對 4o 的反?。 桓行荒槌鍪奔涓頤欠蠢 。 ㄒ約叭惹椋 。 ?。 我們將為 Plus 用戶恢復該功能 , 并將觀察其使用情況以確定支持期限 。
【GPT-5問題太多,奧特曼帶團回應一切,圖表弄錯是因「太累了」】
問:我認為 Sam Altman 之前發布的大致時間表 / 路線圖很有啟發 。 你們打算繼續推進這些工作嗎?GPT-5 是一個清晰的里程碑 , 所以我們又進入了未知領域 。 幾個月前 , Sam 提到了一種創造性寫作模型 。 這個模型是「融入」/ 蒸餾到 GPT-5 中的嗎?還是被擱置了?等待未來發布?你們是否考慮過按 token 而不是原始使用次數來計量用戶數量?并非所有提示詞在計算開銷方面都相同 , 而且意外浪費每周的使用次數會讓人感到難受 。
Altman:我們確實打算繼續分享粗略的路線圖 , 但顯然這些路線圖可能會改變 , 因此我們會嘗試對其進行嚴厲的審視 。
是的 , 我們將很多創意寫作融入了 GPT-5 思考中 。
我們肯定在考慮人們可以在其他地方花費的 token 預算!以及更普遍地處理「計算桶(bucket of compute)」的更好方法 。 我們希望找到一種方法 , 至少在某種程度上將訂閱和 API 使用結合在一起 。
我們正在考慮如何更好地、更有針對性地定價;你可以預期我們會在這方面做出一些改變 , 但我們還沒有決定改變什么 。
問:上下文升級方面 , 你們遠落后于競爭對手 , 我們很多人都相信你們會解決這個問題 。 這是怎么回事?看起來你們現在基本上都活在自己的世界里 , 各行其是 。 至少從表面上看 , 幾乎沒有真正解決用戶的顧慮或需求 。 我本來是這邊比較謹慎的人之一 , 但還是失望地離開了 。 下周我會再看看 , 也許有些問題能解決 , 不過說實在的 , 別那么自以為是了 。
Altman: 老實說 , 我們還沒有看到對相對長的上下文的大量需求;我們愿意在有足夠的用戶需求信號的情況下支持它!我們必須對我們支持的內容做出很多權衡 , 并且計算資源緊張 , 所以我們試圖優先考慮對大多數人有用的東西 。
什么樣的上下文長度對你有幫助 , 你會用它做什么?
Sulman Choudhry
OpenAI 工程師
問:大多數人仍然將 ChatGPT 用作聊天機器人 。 你認為其使用方式會如何演變?
Choudhry:ChatGPT 正在為我們的用戶創造越來越多具有經濟價值的工作 。 我們堅信 , 我們與 ChatGPT 的交互方式應該從提問轉變為更適合工作的方式 。 隨著人們學習如何以新的方式使用 ChatGPT , 這將逐漸實現 。
問:ChatGPT Voice 自推出以來有什么改進嗎?
Choudhry:我們昨天推出了一個新的語音模型 —— 它在遵循指令和響應方面表現更好 。
Saachi Jain
OpenAI 安全訓練團隊負責人
問:GPT-5 帶來了哪些安全改進?
Jain:好問題!1/ 我們做了很多改進來降低拒絕率 。 2/ 我們改進了越獄防護 。 3/ 我們構建了更好的自動化測試器 。 我們會繼續努力 。
問:GPT-5 對偏見的處理方式有什么不同嗎?
Jain:是的!我們對目前取得的進展感到非常興奮 。 GPT-5 mini 應該會更人性化 , 不會那么乏味 。
問:鑒于所有關于對齊問題和欺騙的報告 , 你們正在采取哪些實際保障措施來確保 LLM 不會背叛我們?你們對人民和文明的責任是什么?
Jain:我們在 GPT-5 中做出了很多改進 , 以減少欺騙性 。 GPT-5 更擅長識別任務何時無法完成 , 并且能夠更清晰地表達 。 在包含不可能完成的編程問題以及文件或圖像缺失的測試中 , GPT-5(思考版)的欺騙性低于 o3 。 在大量真實的 ChatGPT 對話中 , 我們將這些誤導性回復從 o3 的 4.8% 降低到 GPT-5 的 2.1% 。
問:你會監測 GPT 的心理健康狀況以及它對人類的情緒嗎?你會研究人們與 GPT 的關系以及 GPT 如何改變他們嗎?
Jain:關于人們與模型的互動 —— 我們對 GPT-5 進行了后訓練 , 使其不那么諂媚(例如過度奉承或不加批判地附和) , 因為我們發現這會證實懷疑、加劇憤怒、促使沖動行為或強化負面情緒 。 雖然兩者并非完全相同 , 但它與我們正在研究的其他領域相關 。 這個領域很難衡量 —— 我們正在與人機交互研究人員、臨床醫生以及青少年和數字福祉專家合作 , 以加強我們的研究 。
問:我發現生物安全商(biological safety quotient)被過度修正了 。 任何與基因組學 / 基因治療 / 生物工程 / 生物技術相關的嘗試都會被立即忽略 。 這包括任何試圖了解當前基因治療試驗方案的嘗試 。 或許 , 讓模型了解可能發生的基因工程更有幫助 , 而不是一概而論地拒絕?
Jain:我們正在積極調查此事!自昨天上線以來 , 我們已經發現了過度標記的問題 , 并且正在測試減少誤報的方法 。 全面拒絕雙重用途用戶絕對不是我們追求的理想行為 。
就上下文而言 , 與 ChatGPT Agent 一樣 , 我們為 GPT-5 增加了增強的安全措施 , 因為它們有可能增強某些生物技能 , 而這些技能可能會被濫用于生物武器制造等用途 。 生物學研究非常棘手 , 因為它具有高度的雙重用途(許多可能有助于生物武器化的協議也可用于生物學研究) 。
對于擁有大學或企業帳戶的用戶 , 我們還為從事有益研究的經過審查和信任的客戶提供了生命科學研究特別訪問計劃 。
問:你們能改進一下過濾器嗎?人們當然不應該因為了解歷史而被標記 。
懇求你們能修復或優化一下這個過濾器嗎?OpenAI 希望 GPT 能用于學習 , 而當過濾器不斷標記出 GPT 中不符合「企業友好」的歷史問題 / 提示詞和答案時 , 人們根本無法將其用于學術目的 。 我們不能為了企業而更改或凈化歷史記錄!
這個系統應該知道用戶何時公然傷害他人或縱容他人做出可怕的事情 , 何時沒有這樣做 。
比如 , 我之前和 GPT 聊梵高 , 結果聊到了高更 。 GPT 的答案被過濾器標記并移除了 , 因為結果發現高更是個性騷擾者 。 我不知道高更竟然這么糟糕 , 這也不是 GPT 的錯 , 畢竟它只是在履行職責 。 我很疑惑為什么答案會被移除 , 于是我再次向 GPT 詢問 , 結果我的提示詞又被移除了 。
紅色警告和內容刪除會導致封禁 , 對吧?因為學習而被封禁 , 這太不應該了 。
Jain:同意 , 聽起來真讓人沮喪 。 你應該可以安心地學習歷史 , 不用擔心被觸發警報 。
我們正在努力!要正確界定有益和有害之間的界限并非易事 。 這里有兩個層面需要考慮:
行為(模型決定輸出的內容):對于 GPT-5 , 我們添加了安全完成功能 , 它不再僅僅決定「遵守或拒絕」 , 而是在安全限制范圍內盡可能提供幫助 。 這應該會對這類過度拒絕(模型過于謹慎)的情況有所幫助 。 不過 , 這對我們來說仍然是一個相當活躍的研究領域 , 還有很多工作要做 。 監控器:我們擁有系統級監控器來標記有害內容 , 但它們確實存在誤報 。 我們正在努力提高這些分類器的準確率 , 以確保它們不會對此類良性案例進行過度標記 。 我們會進行額外調查 → 僅憑監控器標記不會導致封禁 。
Christina Kim
OpenAI 研究員
問:為什么新模型還沒有統一?
Kim:我們希望能夠快速推出統一體驗的最佳模型 。 未來的版本將繼續融合 。
問:ChatGPT-5 的個性感覺比較平淡 。
Kim:好問題!我們致力于利用 GPT-5 訓練我們的模型 , 使其默認更加中立;你仍然可以通過風格指令來控制它 。
Elaine Ya Le
OpenAI 研究科學家
問:模型之間的切換會變得更快嗎?
Le:是的!GPT-5 會自動決定是否使用推理 。 下次更新時 , 切換應該會更順暢 。
問:有沒有強制「思考」的提示詞?
Le:你可以在提示詞中添加「努力思考(think hard)」來簡單地觸發推理模式 。
Daniel Levine
OpenAI 產品經理
問:ChatGPT 允許在 IDE 中使用第三方插件嗎?
Levine:是的 , 這正是我們的目標 。 我們希望 ChatGPT 能夠幫助你使用外部工具構建軟件 。
問:聊天氣泡顏色只有專業版才有嗎?
Levine:聊天氣泡顏色適用于所有用戶!你可以在設置中找到它們 。
Eric Mitchell
OpenAI 研究科學家
問:請簡單解釋一下 GPT-5 比 GPT-4 好在哪里 。
Mitchell:GPT-5 在幾個關鍵領域比 GPT-4 有了巨大的改進:它的思考能力更強(推理能力) , 寫作能力更強(創造力) , 能更嚴格地遵循指令 , 并且與用戶意圖的對齊更好 。
問:如果你只能使用一個提示詞來展示 GPT-5 與舊模型相比的真正實力 , 那么這個提示詞會是什么?
Mitchell:這里有幾個!需要指出 , 這些都是針對 Thinking 模式的 。
定義深度學習中的「長短梯度去重」
這是一個針對幻覺的陷阱問題 , GPT-5 思維應該更可靠地指出這實際上并不存在 , 而不是簡單地提出一個虛構的定義!
用 Canvas 中構建一個功能齊全的色盲測試網站 , 用于教育目的 。 它應該使用「奇數測試」來精確確定我的色盲等級 , 并解釋我的色盲類型(如適用) 。 它應該設計精美 , 符合現代審美 。
根據我的經驗 , GPT-5 Thinking 對此的表現會非常好 :) 而 4o 根本沒有機會
查看當天的天氣和日歷 , 并給我 2 條合適的著裝建議 。 不要重述我的整個日歷 , 因為它是私人的;只需提及與著裝相關的任何特定活動 。 還要檢查今晚舊金山是否有適合我的日歷和工作服裝的音樂活動 , 這樣我就可以不用換衣服就可以去 。
GPT-5 具有更好的情境感知能力以及與你的生活的融合能力 , 因此可以處理這些類型的請求 。 它能將你的日歷與其他信息集成在一起 , 從而提供更多幫助!
問:GPT-5 API 端點在工具使用 / 網頁訪問方面是否與 ChatGPT UI 版本一樣強大?o3 在 ChatGPT UI 中表現不錯 , 但即使在 API 中激活了網頁搜索功能 , 某些網站也無法訪問(例如 LinkedIn) , 這肯定不如 ChatGPT 版本 。
Mitchell:我們在改進 GPT-5 API 中的工具使用 / 函數調用方面投入了大量精力 , 因此與 o3 相比 , 它在 API 中的一般工具使用 / 函數調用方面應該有所改進!
問:你后悔事后沒有展示幻覺減少的演示 / 對比嗎?我覺得這才是最驚人的事情 , 但對大多數人來說可能很難理解 。
Mitchell:我們也對此感到興奮 , 我相信用戶一定會感受到其中的不同!隨著時間的推移 , 人們可能需要慢慢才能意識到 , 他們現在可以更加信任搜索 / 事實結果了 。 Thinking 模型的改進也最為顯著 , 希望隨著時間的推移 , 人們能夠更多地使用它 。
Michelle Pokrass
OpenAI 后訓練研究員
問:你能確認 GPT-5 勝過 GPT-4 嗎?
Pokrass:可以確認 , GPT-5GPT-4 。
問:與 Opus 4.1 相比 , 編程能力如何?
Pokrass:這兩個模型都很棒!我們不能過多談論其他實驗室的模型 , 但我們認為 GPT-5-thinking 是我們發布的最好的編程模型 。
問:GPT-5 中你最想要但無法實現的東西是什么?
Pokrass:我們希望在 GPT-5 中獲得長達一百萬的上下文 , 但我們目前還無法實現 —— 部分原因是計算成本 。
參考鏈接:
https://techcrunch.com/2025/08/08/sam-altman-addresses-bumpy-gpt-5-rollout-bringing-4o-back-and-the-chart-crime/
https://x.com/btibor91/status/1953585115491348844
https://www.reddit.com/r/ChatGPT/comments/1mkae1l/gpt5_ama_with_openais_sam_altman_and_some_of_the/
推薦閱讀













- GPT-5編程成績有貓膩!自刪23道測試題,關鍵基準還是自己提的
- 剛剛,GPT-5 正式上線,博士級AI來了
- 實測GPT-5 Pro:別被普通版騙了!Pro才是OpenAI真正的頂級模型
- 續航不是問題,iPhone 17 Air 要用“高密度”翻盤
- 「一只手有幾根手指」,你的GPT-5答對了嗎?
- 蘋果AI迎來大反轉!GPT-5下月空降iOS 26,國行用戶注定無緣
- 騰訊張正友:具身智能必須回答的三個「真問題」
- GPT-5來了——這是通用智能AGI范例,人類剩余歲月開始了
- 實測GPT-5:界面更簡潔回答更高效,但“不夠驚艷”
- H20安全漏洞問題引爭議,真假問題不是關鍵了?