
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
近年來 , AI大模型在數學計算、邏輯推理和代碼生成領域的推理能力取得了顯著突破 。 特別是DeepSeek-R1等先進模型的出現 , 可驗證強化學習(RLVR)技術展現出強大的性能提升潛力 。
然而 , 現有關于強化學習和模型的研究多聚焦于單一領域優化 , 缺乏對跨領域知識遷移和協同推理能力的系統性探索 , 讓模型能夠在多領域協同工作 , 發揮更好的推理能力 。
上海AI Lab的OpenDataLab團隊通過大規模實驗 , 深入剖析了RLVR在多領域推理中的復雜機制 , 為構建更強大、更具魯棒性的AI推理模型提供了多個維度的關鍵發現 。
團隊構建了一個涵蓋數學(Math)、編程(Code)和邏輯謎題(Puzzle)三大類數據的多領域評估框架 , 并為不同訓練數據設計了定制化的獎勵策略 。
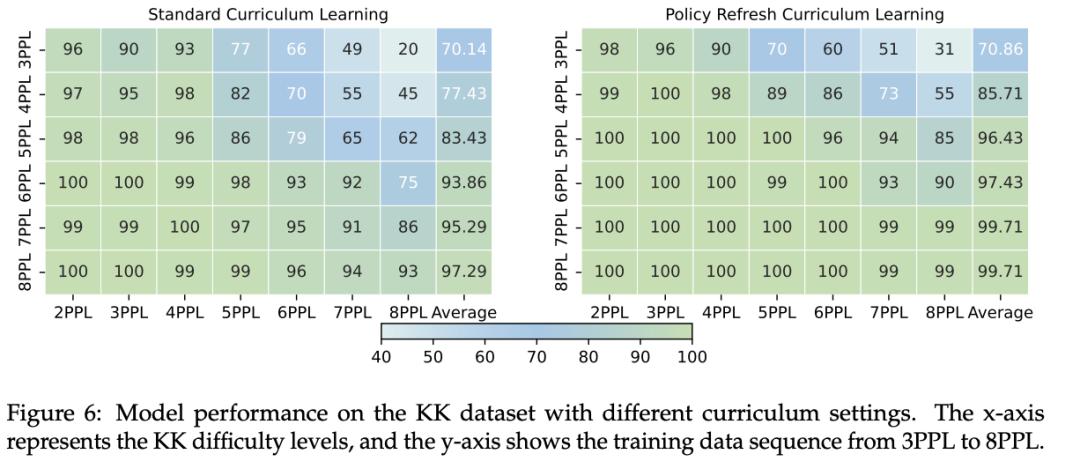
實驗基于Qwen2.5-7B系列模型 , 在將數學、代碼和謎題三大領域數據進行聯合訓練后 , 模型的整體平均性能達到了56.57 , 顯著優于任何雙領域組合 。
研究團隊通過大規模實驗 , 有以下關鍵發現:
Puzzle與Math數據的相互支持:邏輯推理與數學能力相輔相成 , 顯著提升模型的整體性能 。
Code推理的跨領域混合效應:指令遵循能力較強的Instruct模型可以較好的將代碼能力泛化到其他領域 , 而Base模型則不然 。
跨領域數據提升魯棒性:多樣化數據通常能提升模型能力或實現更均衡的表現 , 但需要更復雜的設計來解決Math、Code和Puzzle領域間的潛在沖突 。
SFT可以提升強化學習效果:在強化學習前加入SFT階段可顯著改善模型性能 。
Template一致性至關重要:訓練與評估Template的不匹配會導致性能大幅下降 , 表明RLVR在特定領域訓練時的泛化能力魯棒性面臨挑戰 。
Policy Refresh的益處:在課程學習中定期更新參考模型和優化器狀態可提升模型穩定性和性能 。
獎勵設計需適應任務難度:根據模型在訓練數據上的表現調整獎勵設置 , 可提高學習效率 。
RLVR對語言敏感:中文訓練的模型性能低于英文訓練的模型 , 存在一定的性能差距 。
研究過程與性能表現 領域劃分與數據構建:多域推理的“基石”上海AI Lab的OpenDataLab團隊構建了一個涵蓋數學(Math)、編程(Code)和邏輯謎題(Puzzle)三大類數據的多領域評估框架 , 并為不同訓練數據設計了定制化的獎勵策略 。
實驗基于Qwen2.5-7B系列模型 , 探索了以下幾方面:
模型在數據上的表現與泛化能力:重點關注單領域數據優化與跨領域泛化 , 以及跨領域數據間的相互影響 。
訓練方法與策略的有效性:評估Template在RLVR中的作用 , 以及課程學習策略的有效性 。
模型優化要素:研究不同獎勵機制的設計原則 , 以及訓練語言對模型性能的影響 。
通過系統性實驗 , 研究揭示了強化學習(RLVR)在多領域推理中的內在機制 , 為優化大模型推理能力提供了新視角 。
單領域訓練:各領域“內卷”大比拼在單領域訓練中 , 模型在特定任務上展現出顯著的性能提升 , 但跨領域效應復雜 , 既有協同增效也有相互削弱 。
數學領域:RLVR提升數學性能 , 但跨域效應復雜
經過針對性訓練 , Base模型在CountDown任務上準確率提升了約75個百分點 。 同時 , 數學訓練還能有效提升模型解決邏輯謎題的能力 , 平均得分得到提高 。 然而 , 深度優化數學能力的同時 , 也可能對代碼任務產生負面影響 , 提示了不同領域技能間存在一定的權衡關系 。
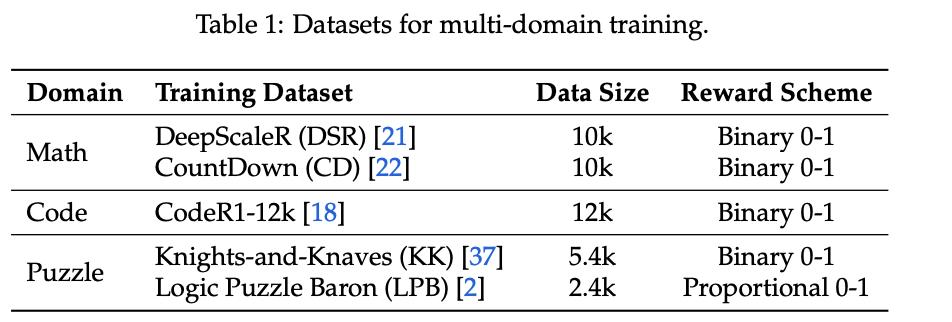
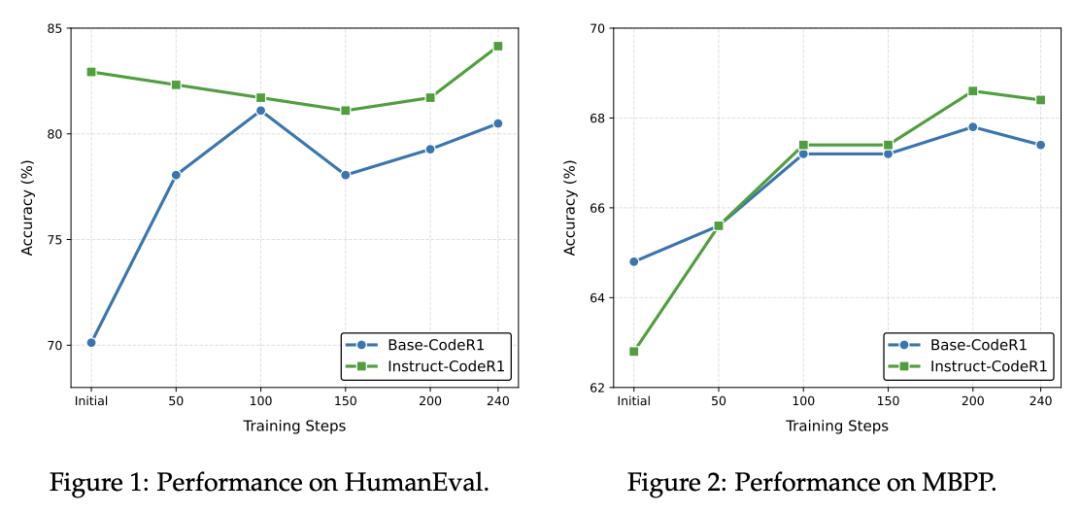
代碼領域:指令微調助力編程 , 展現更強的跨域泛化
代碼訓練提升了模型在編程任務上的表現 , 尤其是經過SFT的Instruct模型表現出更高的性能上限 。 同時 , Base模型在代碼訓練后往往在多數域外任務上出現性能下降 , 而Instruct模型則展現出更強的跨域泛化能力 , 能夠在多數域外任務上保持甚至提升表現 。
謎題領域:邏輯推理實力強勁 , 部分訓練利于數學遷移
在KK數據集上 , Instruct模型準確率高達99.14 , 在Zebra任務中 , 得分提升至36.20 。 此外 , KK謎題的訓練效果還能遷移到數學任務上 , 甚至在部分數學基準中 , 使得Base模型的表現接近或超過Instruct模型 , 進一步體現了跨領域遷移的潛力 。
跨域互動:協同與沖突的探究雙領域組合:探索協同與權衡
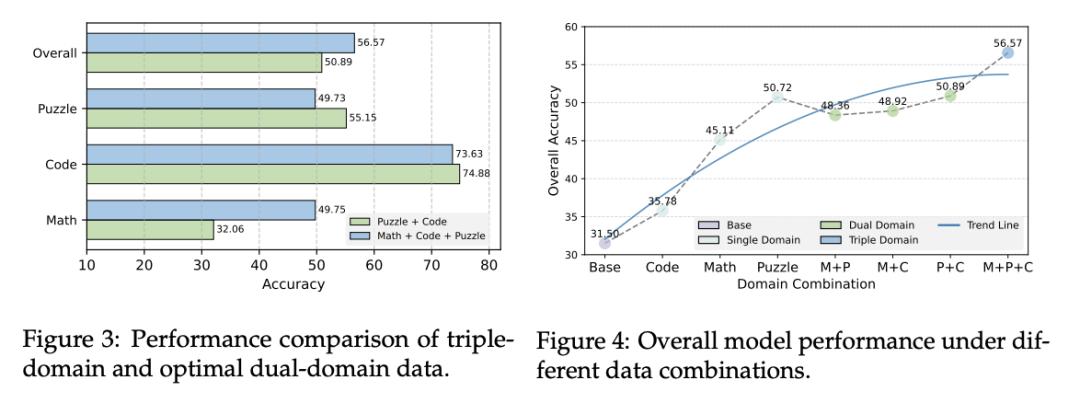
存在顯著協同效應的組合:Math+Puzzle組合使Math任務表現提升至49.72(優于單Math訓練的47.48) , 證明跨領域知識遷移的有效性;Code任務在添加Puzzle或Math數據后均獲得提升 , 顯示組合訓練的潛在優勢 。需要謹慎處理的組合情況:Puzzle任務在所有多領域訓練中表現均不及單領域訓練 , 凸顯其高度專業化特性;值得注意的是Math+Puzzle組合會顯著降低Code任務表現;而Puzzle+Code的組合實現了平均最大19.39的提升 。三領域全家桶:平衡與魯棒性
緊接著 , 將三個領域的數據全部組合在一起 , 結果如下所示 , 多領域聯合訓練展現出更優的整體表現與魯棒性:
三領域聯合訓練實現整體性能突破:將數學、代碼和謎題三大領域數據進行聯合訓練 , 模型的整體平均性能達到了56.57 , 顯著優于任何雙領域組合 。數據多樣性與邊際收益:增加訓練數據的多樣性(領域組合數量)確實能提升整體性能 , 但這種提升存在邊際效應遞減的趨勢 。防止性能塌陷 , 實現均衡發展:與某些雙領域組合(如Math+Puzzle可能導致Code任務性能驟降)不同 , 三領域聯合訓練有效地避免了特定任務的性能“崩潰” , 確保了模型在所有任務上均能保持競爭力 。
Template一致性:最佳表現 【混合數學編程邏輯數據,一次性提升AI多領域強化學習能力】在RL訓練中 , 一個常被忽略的問題是訓練和測試的Template不匹配 。 這可能導致模型性能大幅下降 。 研究團隊在不同Template(R1、Qwen、Base)下進行測試 , 揭示了Template一致性的重要性 。
不匹配Template會嚴重拖累性能:例如 , Base模型在使用不匹配模板時 , CountDown準確率從19.36暴跌至0 , MBPP從51.80降至3.00 。 Instruct模型在MATH500上從73.20跌至1.80 。一致性Template通常帶來最佳表現:R1模板下 , Base模型平均性能達47.84 , Instruct模型達54.56 , 遠超不匹配情況 。 這強調了Template一致性的必要性——RLVR在特定領域訓練時的泛化魯棒性仍面臨挑戰 。
課程學習:從易到難 , 逐步征服課程學習在SFT中已證明有效 , 但在RLVR中的應用仍未全面探索 。 研究團隊在Puzzle中的KK數據集上進行測試 , 基于子問題數量(3PPL到8PPL)設置難度梯度 , 并設計了”Policy Refresh”策略——在每個難度階段后更新參考模型并重置優化器狀態 。
通過實驗發現 ,
課程學習提升性能上限:標準課程學習最終準確率達97.29 , 遠超混合訓練的94.29 。 這種方法幫助模型逐步掌握復雜依賴關系 , 提升泛化能力 。Policy Refresh加速收斂:采用刷新策略后 , 模型在6PPL階段就達到97.43的準確率 , 最終結果近乎完美(99.71) , 甚至超過了指令模型的混合訓練結果(99.14) 。
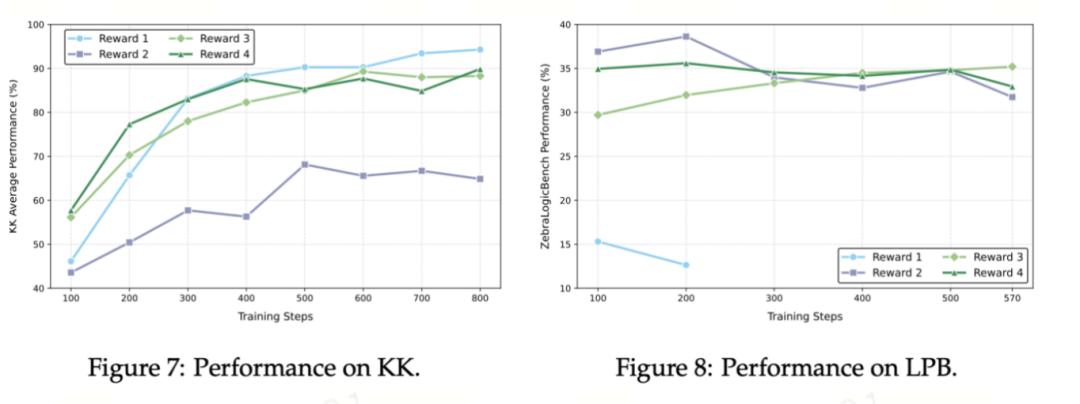
獎勵設計:個性化定制獎勵設計是強化學習的核心 。 研究團隊在KK和LPB數據集上測試了四種策略:(1)二元獎勵要求答案全對才得分;(2)部分獎勵按正確比例計分;(3)格式獎勵用標簽引導推理;(4)重縮放獎勵則將分數范圍調整為[-11
并對錯誤施加懲罰 。 不同設計為模型塑造了截然不同的學習信號 。
研究團隊發現 , 在簡單任務KK上 , 二元獎勵R1憑借直接明了的獎勵設置實現了最優表現;但在復雜任務LPB中 , R1因信號稀疏反而訓練崩潰 。 部分獎勵R2能在LPB初期迅速起效 , 卻難以長期維持優勢;格式獎勵R3和重縮放獎勵R4則憑借穩定推理和放大行為差異 , 后來居上奪得LPB冠軍 。 不過 , 復雜設計在KK上反成累贅 。 結果表明 , 數據集稀疏性和任務難度 , 是決定RLVR獎勵機制成敗的關鍵因素 。
展望未來 , 團隊呼吁拓展Science、General Reasoning等新領域數據分類 , 并探索Llama、DeepSeek等模型的適配性 。 RLVR已經在多個領域被證明其有效性 , 但無論訓練方式如何 , 數據永遠是模型能力來源的基石 , 也希望未來的研究能夠更深入地探究數據對RLVR的影響 。
論文地址:https://arxiv.org/abs/2507.17512
訓練代碼:https://github.com/Leey21/A-Data-Centric-Study
推薦閱讀













- GPT-5編程成績有貓膩!自刪23道測試題,關鍵基準還是自己提的
- 虧到發瘋!AI編程獨角獸年入2億8,結果用戶越多虧得越狠
- AI編程助手成本高昂利潤微薄,初創公司面臨生存挑戰
- 虧到發瘋,AI編程獨角獸年入2億8,結果用戶越多虧得越狠
- Deep Cogito發布四款開源混合推理大語言模型
- Claude斷供OpenAI,AI編程競爭再升級
- 字節Seed數學新模型,SOTA了
- 剛剛,谷歌「IMO金牌」模型上線Gemini,數學家第一時間證明猜想
- 首款融合了電子、光子和量子光的混合芯片問世
- AI編程助手連續翻車,“刪庫跑路”的不再是程序員