作者 | 王一鵬
2023 年底 , 一則 Google 裁撤數據科學家的新聞引起業內關注 。 有媒體猜測 , Google 計劃用 AI 自動化取代部分人力 , 導致數據科學家崗位減少 。 而在最近兩年 , 隨著 AI+BI 的產品形態逐漸普及 , 這種崗位裁撤風潮大有蔓延趨勢 , 從新零售到金融 , 最終傳遞到工業領域 。
尤其是在工業領域 , 行業壁壘較高 , 數據分析師本就是稀缺物種 。 如今 , 這一崗位的編制或面臨進一步縮減 。
AI 沖擊數據分析師崗位的第一步 , 是將取數、做報表、給出分析結論等一系列工作 , 通過自然語言自助化完成 , 將任務交付時間壓縮至分鐘級 。
到了 2025 年 , AI 的職能邊界進一步擴張 。 甚至不需要老板下命令 , 就能根據企業所在的領域、所積累的數據 , 將合適的數據以恰當的方式 , 主動推送給對應的負責人 。
可以說 , 數據的消費范式 , 已經變了 。
本質上 , 老板需要的不是數據 , 而是業務洞察 , 且洞察方向隨著業務的開展 , 會不斷出現變化 。 但崗位職能不同 , 接收到的上下文也不同 , 員工絞盡腦汁 , 耗時數天至數周給出的報表 , 通常也很難令老板滿意 。 從前 , 企業被迫接受這一事實 , 苦惱的是業務一號位以及 HR;現在 , AI 正在重新制定“游戲玩法” 。
數據找人、無問智推?數據分析師會在多大程度上被 AI 取代?InfoQ 特別采訪了濤思數據創始人 &CEO 陶建輝 , 聊了聊濤思數據最新的發布 , 以及 BI 類產品正在發生的變化 。
1 人找數據 , 從未簡單過
2025 年 7 月 29 日晚 , TDengine 發布了一款全新產品 —— TDengine IDMP(Industrial Data Management Platform , 工業數據管理平臺) , 以“用 AI 改變數據消費范式”為主題 , 主打讓數據自己說話 , 不用提問或拉取數據 , 而是將實時業務洞察所需要的可視化面板、實時分析任務主動推送給你 。
在筆者眼中 , 陶建輝老師始終是一位情緒非常飽滿的持續創業者 。 自 2008 年開啟移動互聯網領域 IP Push 與 IP 實時消息服務的創業之路起 , 到后來深耕時序數據庫 TDengine , 他一路走來始終保持著充沛激情 。 而當發布 TDengine IDMP 產品時 , 他的興奮之情尤為強烈 —— 尤其是對其核心功能 “無問智推” , 更是寄予厚望 , 堅定認為這是在 AI 時代下 , 足以帶來 “范式革命” 的關鍵產品 。
要回溯這種興奮的源頭 , 我們必須要明白 BI 類產品在數據的供給和消費問題上 , 長期以來所面臨的問題 。
我們可以將 BI 產品的發展 , 簡單概括為三個階段:
報表式 BI 最早于上個世紀就出現了 , 是最原始的形態:IT 人員先建模、后出表 , 通過郵件進行分發 , 業務人員僅負責提出需求和查看結果 。 這種 BI 本質上只是在解決“沒有數據可看”的問題 , 是信息化的早期產物 。
除了功能受限 , 報表式 BI 的另一大問題在于 , 技術人員完全不理解業務 , 建模速度也跟不上業務發展 。 于是自助式敏捷 BI 出現了 , 主打一個“還政于民” , 建模的主體變成了業務人員 , 建模的方式是拖拉拽 , 同時通過實時連接數據倉庫或大數據引擎 , 解決“數據時效性差”的問題 。
不過 , “還政于民” , 初衷是好的 , 結果卻不盡如人意 。 太多的人有權限進行數據建模 , 導致“數據沼澤”出現了 , 企業經營數據甚至做不到口徑上的統一——同樣叫做“毛利率” , 但在銷售部門和運營部門是完全不同的算法 。
于是大約 2019 年之后 , 指標化 BI 產品開始出現 。 指標化 BI 是在數據倉庫 / 數據湖與 BI 工具之間構建一個“統一指標語義層” , 意思就是要對基礎的指標和計算口徑進行共識 , 比如:銷售額 = 含稅成交總額 - 退貨額 , 這一公式只允許存儲一次 。 數據維度、修改歷史都做好限制和記錄 。
指標化 BI, 等于在一定的限制下 , “還政于民” 。 那么 , 指標化 BI 解決得了產業的問題嗎?Gartner 等研究機構并未針對指標化 BI 產品做單獨的落地成功率統計 , 但 2021-2023 年對“整體 BI/ 數據分析項目”的統計區間顯示 , 超過 60% 的 BI 項目未能達到預期效果 。
拋開紛繁復雜的大數據技術名詞 , BI 類產品進化與拉扯 , 始終是在解決“人”的問題 。
人無法做數據化決策 , 所以出現了報表式 BI ;技術人不懂業務 , 所以出現了自助式敏捷 BI ;業務人自說自話 , 所以出現了指標化 BI。 而在任何一家公司內 , 具備深度業務認知 , 且能緊跟業務發展 , 用數據建模的思維組織材料 , 敏捷生產洞察報告的人才 , 都是極少的 。 所以即便我們發明了“數據分析師”這個崗位 , 也依然不能將 BI 落地的成功率提高 。
當這一問題出現在新零售領域時 , 其嚴峻程度或多或少是被沖淡了 。 畢竟 , 像庫存周轉率、訂單滿足率這類數據指標 , 即便不明確計算公式 , 多少也能理解其反映的業務情況 。 但在工業領域 , 許多數據指標是與工藝聯系在一起的 , 理解成本驟然上升 。
比如在煙草行業 , 需要關注的指標有:回潮溫度、打葉效率、葉絲填充值、蒸汽單耗等 , 不但要理解其含義、計算方式 , 還要意識到 , 這些指標在數值上 , 是有參考標準和取值范圍的 。
每一年隨著工藝和法律法規的變化 , 相關指標的參考標準都有可能發生變化 。 比如 AI 視覺檢測技術成熟后 , 煙草行業的殘次頻率已經從 0.8% 降到了 0.12% 。 不要以為這一數據變化只有匯報價值 , 據煙草行業測算 , 一家中型煙廠每年可因此節省原料成本超過 222 萬美元 。
一個普通業務人員 , 很難做到對這些工藝指標、取值范圍、每年變化了如指掌 , 甚至即時調整數據建模 , 產出對應的報告 。
這是數智化轉型的核心困局:人的能力即是瓶頸 , 軟件只能輔助 , 不能根除 。
直到 2022 年 ,AI 打破了這一邏輯 , AI 的知識量與工作效率 , 對于人而言是“降維打擊” 。 到了 2025 年 , AI Agent 端到端任務平均通過率已經突破 70% , 對 Level-1 級難度的任務通過率已經突破 85% 。
從前在企業內缺位的數據專家 , 今天可以由 AI Agent 出任 , 這是 TDengine IDMP 所做的事情 , 也是陶建輝老師為何如此興奮 。
2 數據找人 , 濤思數據的解決思路
那么 , 所謂的由 AI Agent 出任數據專家 , 實現“數據找人” , 是對 ChatBot 進行簡單套殼嗎?是單純地集成一個 DeepSeek 嗎?
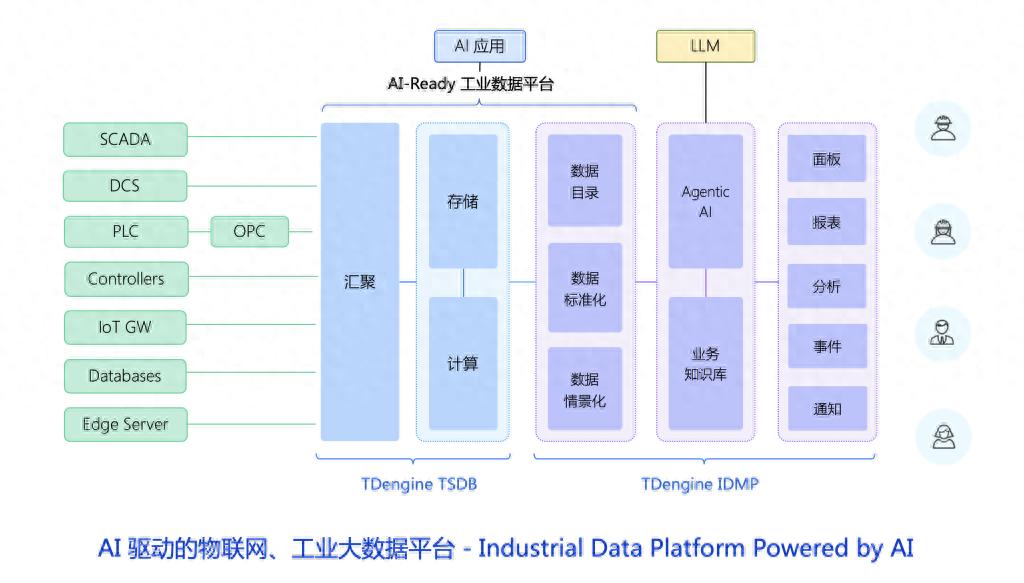
當然不是 , 在發布日 , 濤思數據公布的 IDMP 架構如下:
大數據平臺 , 尤其是工業領域的大數據平臺 , 不光是解決數據分析問題 , 也是在解決數據的采集和治理問題 。 濤思數據的前置技術積累是充分的 , 在時序數據庫上 , 有性能強大且具備開源口碑的 TSDB 做支撐 。
TDengine TSDB 單個集群可以支撐起 10 億級測點 , 配合高效的存儲引擎 , 整體成本是通用平臺的十分之一 。 它具備良好的系統開放性 , 支持 JDBC、ODBC、REST API 等接口 , 能夠與 MES、ERP、AI 等企業系統無縫集成;支持數據訂閱 , 數據不僅能流進來 , 還能實時流出去 , 不被廠商綁定;部署方式也更靈活 , 兼容 Windows、Linux、虛擬機、容器等多種環境 , 適配各種工業現場需求 。
TDengine TSDB 是一個基礎 , 保證 TDengine IDMP 可以高效獲得業務數據 。 接下來 ,TDengine IDMP 基于采集到的實時數據 , 創建數據目錄 , 做好數據標準化、數據情景化 。
數據目錄其實是數據孿生會涉及的概念 , 解決“數據在哪、屬于誰、長什么樣”的問題 , AI/BI 工具可直接按目錄路徑調用數據 , 無需再寫復雜 SQL 。
數據標準化的目標是為了讓跨系統數據可比、可用、可信 , 價值接近我們前面提到的“統一指標語義層” 。
數據情景化 , 是為了讓任何一條時序數據都能回答“它代表什么、在什么場景下、跟誰有關” , 解決前面提到的“取值范圍”問題 。
接下來 , TDengine IDMP 會通過內置的 Agentic AI , 配合業務知識庫 , 感知具體應用場景 , 自動生成指標、報表和分析任務 , 并主動推送業務洞察 。 其他核心能力還包括:
- 智能可視化:“無問智推”能夠驅動 AI 根據當前業務場景自動生成可視化看板 , 告別手動配置
- 實時分析:支持多模態觸發的流式計算 , 毫秒級反饋分析結果
- 事件管理:將分析結果轉化為可執行事件 , 提供全鏈路根因分析能力
實際上 , TDengine IDMP 的野心很大 , 它并非想單純給工業大數據平臺加一個 ChatBI , 而是希望提升從數據采集到業務決策的整個鏈路的效率 。 濤思團隊技術人員 , 在官方博客上 , 也對這種針對性設計做了解讀:
“在不同的工業場景里 , 有八個痛點彼此關聯、相互放大:
- 數據在采集環節就因為廠商和協議不同而被割裂;
- 進入系統后 , 又因缺少語義和上下文而“失去身份”;
- 質量問題無法在入口階段解決 , 導致后續分析精度下降;
- 出于安全考慮 , 數據流動受限 , 價值被鎖?。 ?
- 海量數據積壓在庫里 , 缺乏實時處理能力;
- 新算法、新模型難以及時落地;
- 業務人員缺乏直接獲取洞察的途徑 , 實時決策受阻;
- 行業知識門檻高 , 新人難以快速勝任 。 ”
陶建輝老師本人對 TDengine IDMP 的期待甚至還要更宏大:數據的消費范式正因此出現變革 。
另有接近濤思數據的人士透露 , 目前團隊圍繞 TDengine IDMP 和智能制造領域企業的合作 , 如煙草、光伏、電力 , 已經在洽談和推進中 , 來自客戶側的反饋和需求可能會進一步加快 TDengine IDMP 的迭代速度 。
3 數據消費范式轉變:工業領域或將開始下一次進化
從 TDengine IDMP 發布 , 到“數據找人”逐步成為業界的新風潮 , 智能制造正在逐步邁入新階段 。 過去 , 人們對制造業存在某種“偏見” , 認為其:薄利、固化、封閉、缺少標準 , 因而轉型困難 。
但隨著如 TDengine IDMP 般的產品進入 , 制造業攜移動互聯網時代積累的通信、大數據技術 , 跑步進入智能化時代 。 整個產業因此變得更加靈動 , 變得更具生命力 。 產業進化的信號 , 即是發生在 2025 年的數據消費范式轉移:從“人定義問題→找數據→等洞察”到“AI 定義場景→推數據→給行動” , 傳統數據分析師的職能被三個不可逆的結構性變化徹底消解:
- 技術替代:像 IDMP 般的工業大數據平臺 , 將“業務認知 + 數據建模 + 實時推送”封裝成基礎設施 , 使 90% 的常規分析需求無需人工干預 。
- 成本重構:當 AI 能以工程師 1% 的成本完成設備預測性維護分析(國家電網案例) , “招一個分析師”從投資變成冗余 。
- 權力轉移:數據消費權從集中化的分析團隊下沉至一線操作員——AI 用自然語言告訴工人“第 3 號鍋爐需降負荷” , 而非等待分析師的周報 。
至少 , 未來業務人員使用大數據平臺 , 既不需要集中培訓 , 也不需要排隊等待 IT 人員定制 SQL 。
AI Agent , 會自己找上門來 , 融入工業體系的每一個流程 。
【數據分析師,即將從工業領域“消失”?】今日好文推薦
推薦閱讀














- 用AI驅動工業仿真,「清航飛邁」讓 “所思即所得” 變為現實|早期項目
- 蘋果 HomePod mini 2 即將發布,新設計首次曝光
- 小米平板8即將發布!直接搭載驍龍8至尊芯片,性能超強
- 混合數學編程邏輯數據,一次性提升AI多領域強化學習能力
- 首年即盈虧平衡,音頻AI芯片出貨3000萬片,波洛斯獲數千萬融資|硬氪首發
- 首爾AI數據公司Datumo獲1550萬美元融資
- 56K的貓叫,停在了2025:互聯網最著名的聲音即將沉寂
- 蘋果Vision Pro平替?vivo首款頭顯產品即將登場,高管稱很上頭
- 偷數據的AI公司被抓到了
- 磁帶大小塞入75TB數據,日本巨頭掏出AI存儲黑科技