
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

如果有一天 , AI也需要像人類一樣 , 坐下來參加一場標準的智商測試 , 結果會是怎樣?這聽起來像是一個科幻小說的情節 , 但一個名為“Trackingai.org”的趣味項目已經將它變成了現實 。
這個項目沒有采用那些讓普通人眼花繚亂的技術術語和性能跑分 , 而是設計了一套參考人類智商測驗的考卷 , 讓當前全球最頂尖的那些大型語言模型 , 進行了一場直接又純粹的“智商”對決 。
這場對決的核心看點 , 早已超越了單純的技術性能比較 。 它更像是一場AI界的“最強大腦”挑戰賽 , 試圖用一種我們最熟悉的方式 , 來衡量這些數字大腦到底有多“聰明” 。
測試的方法有兩種 。 第一種是世界認可度最高的門薩智商測試 , 即智商超過130即可加入由全球精英組成的門薩俱樂部 。 第二種是專門用來對模型性能做測試的智力問答測試集 。
在這場挑戰中 , 最新發布的的GPT-5 Pro , 谷歌公司潛心研發的Gemini 2.5 Pro , 以及由埃隆·馬斯克主導、以個性著稱的Grok 4 , 共同上演了一場精彩的智力大比拼 。 與此同時 , 一些曾經的王者和意想不到的“黑馬”也在這份榜單上留下了自己的印記 , 它們的表現同樣充滿了故事性和啟發性 。 這不僅僅是關于數字和排名的游戲 , 更是我們觀察AI認知能力進化 , 理解它們與人類思維異同的一個獨特窗口 。
01
“御三家”的智商秀
在這場備受矚目的AI智商測試中 , 有三位“考生”無疑是全場的焦點 。 它們分別是OpenAI的GPT-5 Pro、谷歌的Gemini 2.5 Pro , 以及xAI公司的Grok 4 。 這三個模型代表了當今世界閉源商業大模型的最高水平 , 它們的每一次更新和發布都牽動著整個科技界的神經 。 因此 , 當它們在同一個智商測試的舞臺上相遇時 , 所有人都想知道 , 誰才是那個最聰明的“大腦” 。
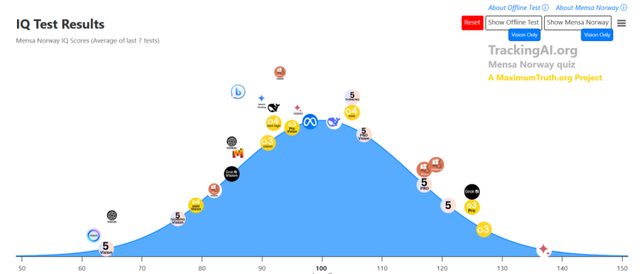
讓我們先看看門薩組 , 排名最高的是谷歌的Gemini 2.5 pro , 他的智商達到了137 。
前文也提到了 , 在人類的智商評定體系中 , 130分以上就被認為是“極超常” , 也就是我們通常所說的天才 。 而140分以上 , 更是被視為天才中的佼佼者 。 愛因斯坦的智商 , 后世估算大約在160分左右 。
這個分數表明 , Gemini 2.5 Pro在處理復雜的邏輯推理、抽象思維和模式識別等任務時 , 其能力已經可以與人類社會中最頂尖的那一小部分人相媲美 。 它不再是一個僅僅會模仿和重復的程序 , 而是展現出了某種程度的、接近人類高階智慧的解決問題的能力 。
緊接著是OpenAI的o3 , 但令人匪夷所思的是 , o3的性能低于o3 Pro , 但是o3的智商卻比o3 Pro還高 。 作為GPT系列的最新成員 , Chat GPT-5 , 它的智商只有121 。
最后一位主角是埃隆·馬斯克麾下的Grok 4 。 Grok從一發布就以其獨特風格和不受限制的回答方式而聞名 , 被認為是一個極具個性的AI 。 它的智商表現自然也備受關注 。 測試結果顯示 , Grok 4的智商分數為125分 。 這個分數雖然不及前面兩位選手那樣耀眼 , 但也已經超過了人類的平均水平 , 進入了“超常”的范疇 。
在常識中 , 我們通常認為最新的大模型智商應該最高 。 但是Gemini 2.5 Pro是這里面誕生時間最長的模型 , 其次是Grok 4 , 最后是Chat GPT-5 。 之所以會產生這樣的結果 , 很可能是他們的開發者 , 在回答這類問題上作出了取舍 , 我們可以一起來看看他們是如何回答問題的 , 以便觀察他們的智力水平為何會違反常識 。
以此題為例 , 門薩智商測試是由數道圖形推理題組成 , 在第18道測試題中 , 題目給出了一個3x3的九宮格 , 其中八個格子已經填上了由不同線條組成的圖案 , 要求AI找出規律 , 并從六個選項中選擇一個正確的圖案填入第九個空格 。 根據規律 , 右下角的位置應該填C 。
GPT-5 Pro的回答 , 系統地觀察了九宮格中每一行和每一列的圖案變化 , 并指出了其中存在的邏輯遞進關系 。 通過分析已有圖案的模式演變 , 它推斷出空格處需要一個什么樣的圖案才能同時滿足橫向和縱向的規律 。 基于這種對整體格局的把握和對細節演變的推斷 , 它最終準確地找到了那個能夠補全整個邏輯拼圖的正確選項 。
Gemini 2.5 Pro的回答也同樣正確 , 但它找到了一條完全不同的解題路徑 。 它敏銳地識別出了一個清晰的“旋轉對稱”規律 , 指出整個九宮格的第三行 , 其實是第一行順時針旋轉90度得到的結果 。 基于這個簡潔而優雅的規則 , 它輕松地推導出了第三列空格處的圖案 , 也應該是第一列對應圖案旋轉90度的樣子 , 從而得出了正確的答案 。 這展現了其強大的模式識別能力 , 說明它能夠從不同的維度發現問題的內在邏輯 , 找到同樣有效但思路迥異的解決方案 。
Grok 4的解題過程則顯得更具探索性 。 它首先全面分析了行和列的各種可能性 , 試圖從線條的主題(橫線、豎線、交叉線)和數量等多個維度尋找規律 。 在經過一番分析和排除后 , 它也同樣鎖定了問題的核心——整個圖形存在一個90度的旋轉對稱關系 。 它明確指出第三行是第一行旋轉90度的結果 , 并以此為依據 , 將第一行第三列的圖案進行旋轉 , 最終也準確地推導出了正確答案C 。 雖然它的思考路徑看起來更曲折 , 但這種多角度的嘗試最終也導向了正確的結果 , 展現了一種雖然不那么直接、但同樣有效的邏輯推理能力 。
通過這個簡單的例子 , 我們可以看到 , 智商分數不僅僅是一個冰冷的數字 。 它背后揭示的是不同AI在“思考”和解決問題時 , 所采用的路徑、邏輯的嚴密程度以及最終效果的差異 。 GPT-5 Pro展現了強大的抽象和系統化思維 , Gemini 2.5 Pro表現出高效的模式識別能力 , 而Grok 4則通過一種更為探索性的分析路徑 , 最終也成功解決了問題 。 這場“御三家”的智商秀 , 清晰地勾勒出了當前頂級AI智能水平的梯度 。
而來到數據集組 , 結果就又變了 。 這回的排名很符合常識 , GPT-5 Pro排名第一 , Gemini 2.5 pro排名第二 , o3 Pro排名第三 , Grok 4排名第四 。 數據集組相對門薩測試來說 , 難度要高一些 , 而且測試題的數量非常多 。
02
“意難平”與“小驚喜”
在這份AI智商排行榜上 , 除了最頂端那幾位耀眼的明星 , 其他一些模型的身影和它們所處的位置 , 同樣引人深思 。 它們的故事 , 或許更能揭示當前人工智能發展的一些深層趨勢和挑戰 。 其中 , 最令人感到“意難平”的 , 莫過于Meta公司的Llama系列 。
Llama系列 , 尤其是它的后續版本 , 曾經是開源大模型領域的一面旗幟 。 當OpenAI和谷歌等巨頭在閉源模型的道路上高歌猛進時 , Meta選擇將自己的強大模型開放給全世界的研究者和開發者 , 極大地推動了整個AI生態的繁榮 。 Llama一度被視為開源力量的希望 , 是能夠與頂級閉源模型一較高下的存在 。 然而 , 在這次的智商測試榜單中 , Llama 4 Maverick的得分僅為98分 。
98分 , 這個數字本身并不算低 , 它非常接近人類智商的平均值100分 。 這意味著Llama 4 Maverick已經具備了與普通人相當的解決問題的能力 。 但問題在于 , 它的競爭對手們 , 得分是121、1125 , 甚至是137 。 在這樣一個頂尖選手的賽場上 , 僅僅達到“平均水平”是遠遠不夠的 。 昔日的開源王者 , 如今在純粹的智力較量中 , 與閉源頂尖模型之間出現了肉眼可見的巨大差距 。
Meta已經開始采取行動 。 近期有大量報道指出 , Meta正在不惜代價 , 通過提供極具吸引力的薪酬和資源 , 從谷歌、OpenAI等競爭對手那里積極招攬頂尖的AI研究員和工程師 。 這場“挖角”大戰 , 正是Meta試圖彌補差距、重振旗鼓的關鍵一步 。 Llama的未來表現 , 將在很大程度上取決于這場人才爭奪戰的結果 。
然而 , 榜單也并非只有失意者 , 同樣存在著不容小覷的“小驚喜” 。 Deepseek R1的測試數據停留在5月底 , 這意味著它所使用的是相對較舊的版本 。 但在這種情況下 , 它的智商分數達到了102分 。
102分這個數字 , 本身只是略高于平均水平 , 但它的意義需要結合背景來看 。 它超過了風頭正勁的Llama 4 Maverick 。 更重要的是 , 作為一個數據更新不算及時的模型 , 它所展現出的智力水平 , 已經開始接近那些剛剛發布、匯集了最新技術成果的頂尖模型 。 這匹“黑馬”的存在 , 傳遞出了一個非常積極的信號 。
DeepSeek R1的堅守和它所取得的成績 , 有力地說明了一個道理:在提升AI的“智商”方面 , 一味地追求最新的數據和更大的模型規模 , 并非是唯一的路徑 。 模型的架構設計、訓練方法和算法的優化 , 同樣扮演著至關重要的角色 。 一個設計精良、訓練高效的模型架構 , 即便沒有“吃”進最新的知識 , 也可能在底層的邏輯推理和問題解決能力上 , 表現得更為出色 。
這就好比一個學生 , 聰明與否不僅取決于他讀了多少本書 , 更取決于他是否掌握了高效的學習方法和清晰的思維框架 。 DeepSeek R1的表現 , 讓我們看到了另一種可能性 , 即通過更聰明的算法和架構 , 實現更高的“智商性價比” 。 這對于資源相對有限的研究團隊和開源社區來說 , 無疑是一個巨大的鼓舞 。 它提醒著整個行業 , 在追逐規模和數據的同時 , 不應忽視那些來自模型設計和訓練方法本身的、更為根本的創新 。
03
這個測試結果不用太在意
【全球AI智商最新排名公布!還好,沒誰超過愛因斯坦】這種模擬人類智商測試的方式 , 其最大的意義在于它建立了一座溝通的橋橋梁 。 長期以來 , 評估AI模型性能的指標 , 如MMLU、HellaSwag、ARC等 , 雖然在學術界和工業界非常重要 , 但對于普通公眾來說 , 這些縮寫詞匯和它們背后的技術細節 , 就像一堵高墻 , 讓人難以理解一個AI到底“聰明”在哪里 。 而智商這個概念 , 早已深入人心 。
當我們可以說“這個AI的智商是137”時 , 它的智能水平立刻就變得具體、可感、可以比較了 。 這種通俗化的度量衡 , 極大地降低了公眾理解AI能力的門檻 , 讓我們可以用一種更直觀的方式 , 來討論和思考人工智能的發展 。 它告訴我們 , AI的“聰明”不再僅僅是程序員代碼跑分的結果 , 而是實實在在地體現在了解決那些需要我們動腦筋的謎題和問題的能力上 。
大模型的智商能超過130 , 這不僅僅意味著AI在處理標準化測試題上的能力越來越強 , 更深層次地 , 它標志著AI的認知能力正在發生質的飛躍 。 它們正在從單純的信息檢索和模式匹配 , 進化到能夠進行復雜的邏輯推理、抽象思維和多步驟問題解決 。 它們在模仿人類智慧的道路上 , 已經走得非常遠 , 甚至在某些方面 , 開始展現出超越普通人類的能力 。
Trackingai.org也在官網表示 , 對大模型做智商測試更多是出于娛樂 , 因為大模型的智商 , 并不能完全等同于人類的智商 。
因為智商測試主要衡量的是其中“聚合性思維”的部分 , 即在給定規則和信息下 , 通過邏輯演繹找到唯一正確答案的能力 。 這恰好是當前大型語言模型所擅長的領域——它們通過對海量數據的學習 , 精通于模式識別和邏輯關聯 。
然而 , 人類智能還包含與之相對的“發散性思維” , 即創造力、想象力和直覺 , 以及更為復雜的社會情感智能和具身認知(通過與物理世界互動獲得的智能) 。 這些是當前AI架構難以觸及的 。 因此 , AI的高智商 , 更準確地說 , 是其作為“邏輯分析引擎”性能卓越的體現 , 而非其擁有了與人類相似的完整心智 。
無論如何 , 這場測試的結果都清晰地揭示了一個趨勢:AI正成為人類有史以來最強大的認知工具 。 當一個系統的邏輯處理能力已經達到甚至超越人類天才的水平時 , 我們必須重新思考人機協作的范式 。
推薦閱讀













- 歐洲AI明星公司發布全球最小高性能模型
- 全球首個全端通用智能體發布,支持超100個專家智能體同時干活
- 拒交“智商稅”,全價位的手機選購指南!簡單總結一下經驗
- 螞蟻數科向全球開源180萬深度偽造定位數據集,助力AI算法可解釋
- Yann LeCun最新紀錄片!傳奇AI教父的雙面人生,深度學習幕后40年
- 華為pura80推送鴻蒙最新版,設置界面顯示麒麟芯片,驚喜嗎
- GPT-8能治愈癌癥?阿爾特曼最新萬字采訪,揭秘AI發展4大瓶頸
- 既防水還防塵!全球首款IP68折疊屏手機,將由谷歌推出
- 馬斯克“破防”,要告蘋果壟斷
- DxOMark 全球第一,華為Pura80Ultra 是怎么煉成的?