
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
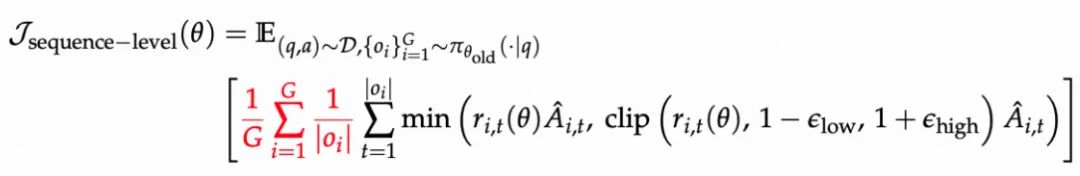
文章圖片

文章圖片

文章圖片
本研究由淘天集團算法技術—未來生活實驗室與愛橙科技智能引擎事業部聯合完成 , 核心作者劉子賀 , 劉嘉順 ,賀彥程和王維塤等 。 未來生活實驗室匯聚淘天集團的算力、數據與頂尖技術人才 , 專注于大模型、多模態等前沿 AI 方向 , 致力于打造基礎算法、模型能力及各類 AI Native 應用 , 引領 AI 在生活消費領域的技術創新 。 愛橙科技則在大模型訓練與優化方面具有豐富的實踐經驗 。 雙方此前聯合開源了高效大模型強化學習訓練框架 ROLL , 此次論文工作同樣是基于 ROLL 框架的實踐探索 。
近年來 , 強化學習(Reinforcement Learning RL)在提升大語言模型(LLM)復雜推理能力方面展現出顯著效果 , 廣泛應用于數學解題、代碼生成等任務 。 通過 RL 微調的模型常在推理性能上超越僅依賴監督微調或預訓練的模型 。 也因此催生了大量的相關研究 。 但隨之而來的 , 是一系列令人困惑的現象:不同研究提出了不同的 RL 優化技巧 , 卻缺乏統一的實驗對比和機制解釋 , 有的甚至得出相互矛盾的結論 。 對于研究者和工程師而言 , 這種 “方法多、結論亂” 的局面 , 反而增加了落地應用的難度 。
為此 , 阿里巴巴淘天集團和愛橙科技聯合多所高校 , 基于自研并開源的 RL 框架 ROLL ,開展了系統化研究 。 通過大規模實驗 , 全面評估了當前主流 RL for LLM 方法中的關鍵技術組件 , 揭示其在不同設置下的有效性以及每類策略的底層機制 , 并最終提出一種僅包含兩項核心技術的簡化算法 ——Lite PPO , 在多個基準上表現優于集成多種技巧的復雜方案 。
論文《Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning》 論文鏈接:https://arxiv.org/pdf/2508.08221
問題背景:技術多樣性帶來的選擇困境
當前 RL4LLM 領域發展迅速 , 但存在以下問題:
標準不一:歸一化方式、剪裁策略、損失聚合、樣本過濾規則等策略存在多種實現方案 , 彼此之間缺乏統一比較基礎 。 結論不一:不同研究因模型初始性能、數據分布、超參設置等差異 , 得出相互矛盾的結果 , 導致實際應用中難以判斷某項技術是否真正有效 。 機制解釋不足:多數方法缺乏對 “為何有效” 的理論或實證分析 , 導致技術使用趨于經驗化 , 形成 “調參依賴” 。
針對上述問題 , 該研究旨在回答兩個核心問題:
不同 RL 優化技術在何種條件下有效?背后的機制是什么? 是否存在更簡單、穩定且通用的技術組合?
公平競技?。 河猛騁豢蚣懿鸞?RL 技巧
為了確保公平對比和結論可靠 , 該研究設計了嚴格的實驗體系:
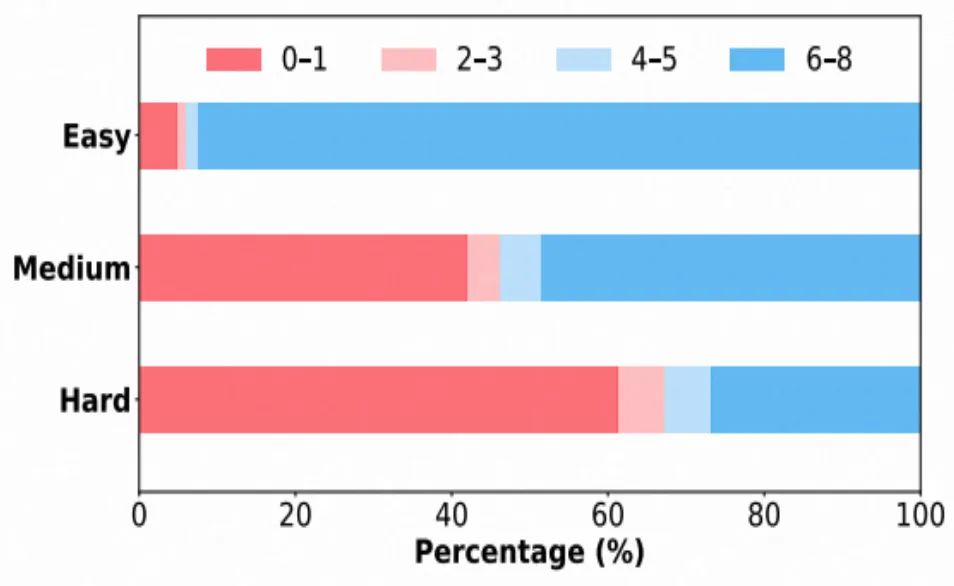
統一實現平臺:所有實驗基于開源的 ROLL 框架完成 , 避免因工程實現差異引入偏差 。 清晰基線設定:以基于 REINFORCE 算法計算優勢值的 PPO 損失(無價值函數)作為基線 , 逐項添加對應算法技術 , 精確量化每個模塊的真實效果 。 多種場景覆蓋:涵蓋不同模型規模(4B/8B)、模型類型(Base 模型 與 Instruct 模型)、任務難度(Easy/Medium/Hard)下的實驗分析 。 訓練集從開源數據集(SimpleRL-Zoo-Data DeepMath 等)中采樣過濾 , 按照難度等級劃分為為:Easy Medium Hard
各難度數據集中 rollout 8 次的正確次數分布 。
解耦式評估:將歸一化、剪裁策略、損失形式、過濾機制等關鍵模塊獨立測試 , 避免多因素耦合干擾判斷 。 多維度評估任務:在六個數學推理數據集上進行測試 , 覆蓋從基礎算術到國際數學奧林匹克難度的問題 。
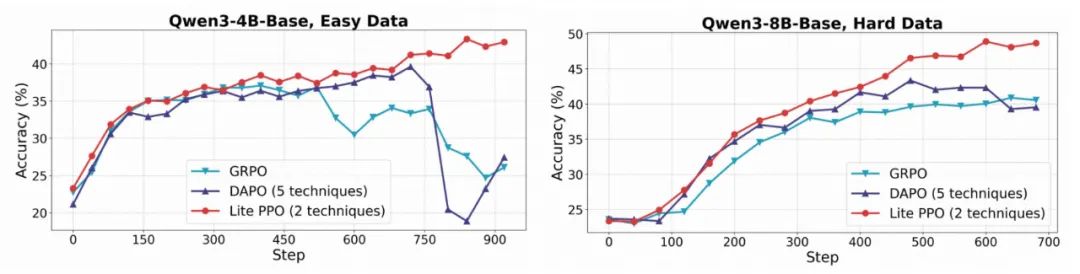
不同模型在不同數據難度下的準確率和回答長度變化趨勢 。 為了確保對比清晰直觀 , 所有曲線均使用相同的參數進行平滑處理 。
核心發現:技巧并非普適 , 需因 “場景” 而異
優勢歸一化:Group-Mean + Batch-Std 最穩健
理論介紹
優勢歸一化通過平移 / 縮放優勢值 , 降低梯度方差 , 穩定更新 。 常見的兩種歸一化方式包括:
組內歸一化(Group-level):同一問題的 K 條響應之間做對比 , 強化組內相對優劣 。
批次歸一化(Batch-level):對整個批次內的 N*K 個響應進行獎勵歸一化 , 利用更大樣本估計方差 , 抑制極端樣本主導梯度 。
關鍵發現
1. 對獎勵分布的敏感性:
組內歸一化(Group-level)在不同獎勵設置下都更穩定 , 尤其在稀疏 / 偏斜分布下 。 批次歸一化(Batch-level)對獎勵分布的偏斜高度敏感 , 在數據分布不平衡的情況下更容易崩潰 , 因為少數極端樣本會主導優勢估計 。
各個模型在不同優勢歸一化方式下的準確率變化趨勢 。
2. 標準差項的風險:
當樣本獎勵分布高度集中的場景下(例如簡單數據集下幾乎全對的樣本分布) , 標準差極小會放大梯度 , 導致訓練不穩定乃至崩潰 。 去掉標準差(僅做均值平移)在此類場景更穩?。 輝詬叻講畛【跋?, 兩種方式差異不大 。
左圖:在不同難度數據上的標準差變化趨勢 。 右圖:在批次歸一化下移除標準差前后的準確率變化趨勢 。
3. 混合方案的優勢:
實驗發現 , “組內均值 + 批次標準差”的混合歸一化更穩健 , 旨在兼顧局部相對比較的語義合理性與全局方差估計的統計穩健性 。
各個模型上不同標準差計算方式的準確率變化趨勢 。
裁剪機制:Clip-Higher 并非普適
理論介紹
PPO 通過限制新舊策略概率比的變化 , 避免過大步長導致策略崩塌 。 但其同等限制上 / 下方向變化 , 常會過度壓制低概率 token 的提升 , 導致熵快速下降、探索不足 。
Clip-Higher:DAPO 提出將上界放寬(上行允許更大更新 , 下行保持保守) , 給 “潛力 token” 更大爬升空間 , 緩解熵塌陷 , 促進結構性探索 。
生效機制解析:
1. 模型能力依賴性:
對于對齊后的 Instruct 模型 , 提升上剪裁閾值(ε_high)能有效減緩熵值下降 , 促進探索 。。 對于未對齊的 Base 模型 , 單純擴大上剪裁范圍作用十分有限 , 甚至可能擾亂優化過程、降低整體表現 。 形成這一差異的原因可能在于:基礎模型初始表現不穩定 , 如果一開始就貿然增大探索空間 , 容易出現非預期行為導致優化偏離正確方向;相反 , 經過對齊的模型分布更均勻 , 適度增加上限能釋放潛藏 “優質” 輸出(詳見論文 Figure 10) 。
各個模型在不同裁剪上限下的訓練趨勢對比 。
各個模型在使用不同裁剪上限下的熵變化趨勢 。
2. 從語言結構視角解析:
當采用低上界時 , 被剪裁頻發的是 “語篇連接詞”(如 \"therefore\"\" \"if\") , 它們往往開啟新推理分支 , 被抑制會壓縮思維路徑 。 將上界放寬后 , 剪裁焦點轉向 “功能詞”(如 \"is\" \"the\" 等) , 連接詞更自由 , 推理結構更豐富 , 同時保留句法骨架穩定 。
左圖:不同裁剪上限下的 token ratio 可視化展示 。 右圖:出現頻率最高的前 20 個被剪裁的 token
3. 上界選擇的 “Scaling Law”:
針對不同大小的模型 , 參數調節需要差異化:在較小規模(如 4B 參數)情況下 , 隨著剪裁閾值增加 , 模型性能持續提升; 而更大規模(如 8B) , 性能提升存在拐點 , 閾值過高則效果反而減弱 。 因此 , 剪裁參數應根據模型體量靈活設置 , 尋求最優解 。
各個模型使用不同裁剪上限的準確率變化趨勢 。
損失聚合方式:token-level 更適合 Base 模型
理論介紹
當前主流方案分別有 sequence-level loss 和 token-level loss:
序列級損失:聚焦于句子或樣本整體 , 適合結構已對齊、輸出穩定的模型 。
詞元級損失:以 token 為基本單位 , 每個 token 都對總 loss 平均貢獻 , 抑制短句偏置 , 補足長推理激勵;
關鍵發現:
基礎模型:采用 token-level 的損失聚合方式更優 , 收斂速度和準確率大幅提升; 對齊模型:采用 sequence-level 的損失聚合方式普遍更優 。
各個模型上采用不同損失聚合方式的準確率變化趨勢 。
過長樣本過濾:效用依賴于模型輸出特征
理論介紹
訓練時設定最大生成長度 , 復雜推理常被截斷 , 尚未給出結論就被判負 , 形成 “錯誤懲罰” 噪聲 , 污染學習信號 。 過濾策略:對超長 / 截斷樣本的獎勵進行屏蔽 , 避免把 “尚未完成” 當成 “錯誤” 從而引入噪聲 。
實驗發現
1. 推理長度影響:
當最大生成長度設為 8k tokens 時 , 應用過長樣本過濾能有效提升模型的訓練質量 , 并且能夠縮短輸出的響應長度 。 當長度限制放寬至 20k tokens , 模型有更充分的空間完成復雜推理 , 生成的響應長度增加 。 此時 , 被過濾的樣本更多是重復或無法自然終止的退化輸出 , 而這類樣本本身占比有限且學習價值較低 , 從而導致過濾操作帶來的增益減弱 。 結果表明 , overlong filtering 的實際效用高度依賴于模型在當前數據下的輸出特征 , 需按場景動態調整 。
不同訓練長度下是否使用超長樣本過濾的實驗表現 。
2. 生效機制探究:
通過對過濾掉的樣本類型進行統計 , 發現引入 Overlong Filtering 能夠降低訓練中 “不能正確預測 EOS 導致重復生成” 的比例(repeat-ratio) , 這表明其增強了模型的終止建模能力 。
左圖:在不同訓練長度下 , 正確回答和錯誤回答的重復樣本分布 。 右圖:在采用和未采用超長樣本截斷場景下的重復樣本分布 。
極簡新范式:Lite PPO—— 兩步勝五技
綜合上述系統分析 , 該研究提出 Lite PPO—— 一個僅包含兩項技術的簡化 RL 流程:
混合優勢歸一化(組內均值 + 批次標準差); token-level 損失聚合 。
在以基礎模型為初始策略的設置下 , Lite PPO 在多個數學推理任務上達到甚至超過 DAPO 等融合五項技巧的復雜方法的表現 。 其優勢體現在:
訓練過程更穩定; 超參敏感性更低; 工程實現簡單; 性能更優 。
這充分說明:“技巧堆疊” 并非性能提升的主要途徑 , 合理的組合能帶來更強的魯棒性和高效性 。
結論
本文貢獻主要體現在三方面:
1. 建立首個系統性對比框架
對歸一化、剪裁、損失聚合、樣本過濾等關鍵技術進行了獨立、可控的實證分析 , 明確了各項技術的適用邊界 。
2. 驗證極簡設計的優越性
提出的 Lite PPO 方案表明 , 復雜的 “多技巧堆疊” 并非必要 。 在多數實際場景下 , 精簡而有針對性的技術組合反而更具魯棒性和可擴展性 。
3. 推動可復現與標準化研究
基于開源 ROLL 框架開展實驗 , 所有配置公開 , 為后續研究提供了可復現基準 , 有助于提升領域透明度與協作效率 。
從中我們獲得如下啟發:
給開發者的建議:別再追求 “trick 大全” , 應根據模型類型(Base/Align)、任務特性(長度、難度)、獎勵設計等實際需求 , 有針對性地配置合理技巧 。 對學術界的啟示:新方法若想 “立得住” , 必須重視廣泛適用性與易復現性 。 Lite PPO 的成功案例表明 , RL 優化未必復雜即優 , 而是貴在精粹 。
關于 ROLL 團隊
本研究由阿里巴巴 ROLL 團隊完成 。 ROLL 是一套面向高效、可擴展、易用的強化學習訓練框架 , 支持從十億到千億參數大模型的優化訓練 , 已在多個場景中展現出顯著性能提升 。
此次論文正是 ROLL 團隊在開源框架實踐中的又一次探索成果 , 未來 , ROLL 團隊將持續關注 RL 社區發展并分享更多實踐經驗 。 同時 , 我們也將繼續完善自研的 ROLL 框架 , 以靈活地適應各種技術 , 為在各種場景中有效應用強化學習提供實用支持 。
【從繁雜技巧到極簡方案:ROLL團隊帶來RL4LLM新實踐】項目地址:github.com/alibaba/ROLL
推薦閱讀













- 從中國到全球:利亞德30年如何重塑 LED 行業格局?
- 中美芯戰已持續7年,從制裁到反制,究竟發生了什么,又做了什么?
- 馬斯克奧特曼中文對噴, AI 視頻終于從「玩具」變成「工具」
- 華為 Mate TV 上手體驗:從「看電視」到「用電視」
- 從一張照片到26TB的宇宙:西部數據如何重新定義影像存儲
- 華為智慧屏 MateTV:從看電視到用電視再到玩電視的三級跳
- 不給授權就不讓用APP?手機廠商集體出動,要從根兒上系統性解決了
- 從GPT-2到gpt-oss,深度詳解OpenAI開放模型的進化之路
- 英國政府主動要求加裝后門!蘋果拒絕:從未構建,將來也絕不會!
- 從3699降到2325元,好評數超10萬條,鴻蒙OS+麒麟8000+衛星通信