AI讀網頁,這次真不一樣了,谷歌Gemini解鎖「詳解網頁」新技能

文章圖片

文章圖片
文章圖片

文章圖片

機器之心報道
機器之心編輯部
谷歌回歸搜索老本行 , 這一次 , 它要讓 AI 能像人一樣「看見」網頁 。
這是谷歌前不久在 Gemini API 全面上線的 URL Context 功能(5 月 28 日已在 Google AI Studio 中推出) , 它使 Gemini 模型能夠訪問并處理來自 URL 的內容 , 包括網頁、PDF 和圖像 。
Google 產品負責人 Logan Kilpatrick 表示這是他最喜歡的 Gemini API 工具 , 并推薦大家把這個工具設置為默認開啟的「無腦選項」 。
那么靈魂一問:這和我平時把鏈接扔給 AI 對話框里有什么本質區別?感覺我一直在這么做 。
區別在于處理深度和工作方式 。 你平時扔鏈接 , AI 通常會通過一個通用的瀏覽工具或搜索引擎插件來「看」這個網頁 , AI 很可能只讀取了網頁的摘要或部分文本 。
而 URL Context 則完全不同 。 它是一個專為開發者設計的編程接口(API) , 當開發者在他的程序里調用這個功能時 , 他是明確地指令 Gemini「把這個 URL 里的全部內容(上限高達 34MB)作為你回答下一個問題的唯一、權威的上下文」 , Gemini 會進行深度、完整的文檔解析 , 理解整個文檔的結構、內容和數據 。
以下是它的能力清單:
深度解析 PDF:能深刻理解 PDF 中的表格、文本結構甚至腳注 。 多模態理解:能處理 PNG、JPEG 等圖片 , 并理解其中的圖表和圖示 。 支持多種網頁文件:HTML、JSON、CSV 等常見格式均不在話下 。
官方 API 文檔提供詳細的配置教程 , 除此之外 , 還可以在 Google AI Studio 直接體驗 。
Towards Data Science 上的一篇文章詳細介紹了 URL Context Grounding , 作者 Thomas Reid 犀利地將 URL Context Grounding 評價為「RAG 的又一顆棺材釘」 。
文章地址:https://towardsdatascience.com/googles-url-context-grounding-another-nail-in-rags-coffin/
RAG 是過去幾年中用于提升大語言模型回答準確性、時效性和可靠性的主流技術 。 由于大模型的知識截止于其訓練數據 , RAG 通過一個外部知識庫來為其提供最新的、特定性的信息 。
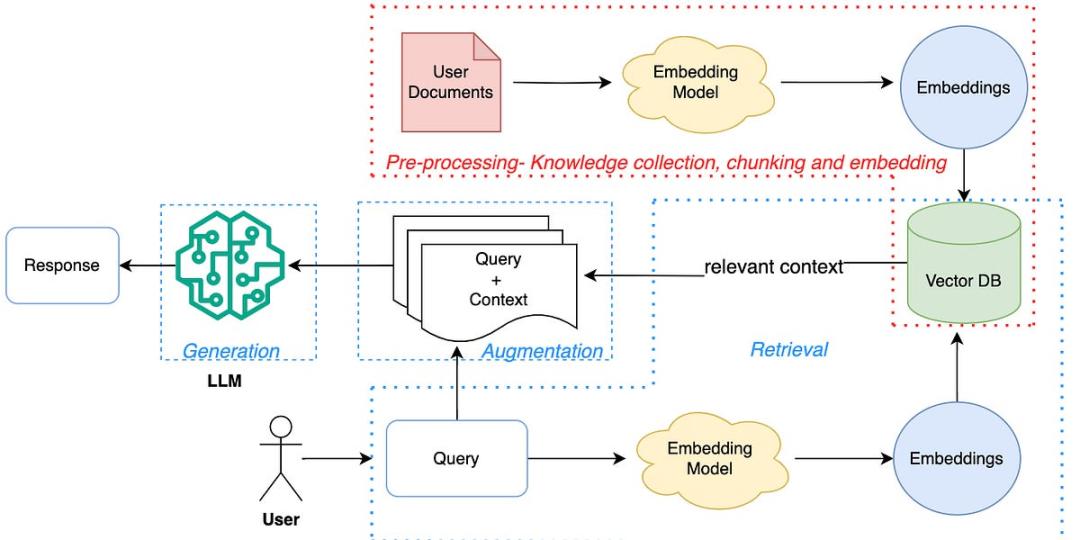
傳統的 RAG 流程相對復雜 , 通常包括以下步驟:
提取內容:從數據源(如網站、文檔)中抓取文本 。 分塊:將長文本切分成更小、更易于處理的片段 。 矢量化:使用嵌入模型(Embedding Model)將文本塊轉換為數字向量 , 捕捉其語義信息 。 存儲:將這些向量存儲在專門的向量數據庫中 。 檢索:當用戶提問時 , 系統首先在向量數據庫中搜索與問題最相關的文本塊 。 增強與生成:將檢索到的相關文本塊作為上下文信息 , 與原始問題一同輸入給大語言模型 , 從而生成更準確、更具針對性的回答 。
RAG 架構 。 圖源:Mindful Matrix
Thomas Reid 指出 , 使用 URL Context Grounding「無需提取 URL 文本和內容、分塊、矢量化、存儲等」 。 對于處理公開網絡內容這個非常普遍的場景 , 它提供了一個極其簡單的替代方案 。
開發者不再需要花費大量時間和精力去搭建和維護一個由多個組件(數據提取、向量數據庫等)組成的復雜管道 , 只需幾行代碼就能實現更精準的效果 。
在 Thomas Reid 提供的示例中 , Gemini 僅憑一個指向特斯拉 50 頁財報 PDF 的 URL , 就準確無誤地提取出了位于第 4 頁表格中的「總資產」和「總負債」數據 , 這是僅靠摘要絕無可能完成的任務 。
自特斯拉 SEC 10-Q 申報文件第 4 頁內容 。
以下是我們在 Google AI Studio 中的測試結果 。
作者接著測試了 URL Context 挑選其他信息的能力 。 在 PDF 的末尾 , 有一封寫給即將離開公司的員工的信 , 概述了他們的遣散條款 。
信中提到的退出日期用星號(***)標記 , 屏蔽退出日期的原因在腳注中給出 。
URL Context 準確識別出了腳注中的內容 。
根據所提供的文件 , 員工離職協議中的離職日期被標記為「***」 , 原因在于某些公司視為隱私或機密的特定非關鍵信息 , 已在公開文件中被有意略去 。
該文件包含一條對此做法的澄清說明:「本文檔中某些已識別的信息已被略去 , 因為這些信息并非關鍵信息 , 且屬于公司視為隱私或機密的信息類型 , 并已用「***」標記以示省略之處 。
根據官網介紹 , URL Context 采用一個兩步檢索流程 , 以平衡速度、成本和對最新數據的訪問 。
當用戶提供一個 URL 時 , 該工具首先嘗試從內部索引緩存中獲取內容 , 以提高速度和成本效益 。 如果 URL 不在緩存中(比如一個剛剛發布的頁面) , 它會進行實時抓取 。
那它的能力邊界在哪里呢?官方介紹中也有明確說明 。
無法翻越「付費墻」:需要登錄或付費才能訪問的內容 , 它無能為力 。 專用工具優先:YouTube 視頻、Google Docs 等有專門 API 處理的內容 , 它不會涉足 。 有明確的容量限制:單次請求最多處理 20 個 URL , 且單個 URL 內容上限為 34MB 。
價格方面 , 它的計費方式非常直觀:按處理的內容 Token 數量計費 。 你提供的 URL 內容越多 , 被轉換成輸入 Token 的數量就越多 , 成本也相應增加 。 這可能會間接引導開發者進行更高效的應用設計 , 即精確地提供所需的信息源 , 而非寬泛地投喂大量不相關的 URL , 從而優化成本 。
不過話說回來 , URL Context Grounding 的出現并非宣告 RAG 的終結 , 而是對其應用場景的重新劃分 。 對于處理企業內網的海量私有文檔、需要復雜檢索邏輯和極致安全性的場景 , 構建一套自主可控的 RAG 系統依然是不可或缺的 。
【AI讀網頁,這次真不一樣了,谷歌Gemini解鎖「詳解網頁」新技能】URL Context 揭示了一個行業趨勢:基礎模型正在將越來越多的「外部能力」內置化 。 過去需要由應用層開發者承擔的復雜數據處理工作 , 正在被逐步吸收到底層模型的服務中 。
推薦閱讀















- AI能讀取思維——腦機接口技術實現74%準確率解碼內心語言
- 旗艦學不會的細節,真我GT8 Pro這次都補齊了,還有2K屏和2億潛望
- 澎湃OS 3首發評測:UI大改終于「上島」,這次要逆轉口碑?
- 榮耀這次真急眼了,16GB+1TB跳水1495元,100倍變焦+北斗衛星消息
- 郭平解讀華為“狼的精神”:有三層含義
- 專利全球第一!這次中國6G技術,又有了突破
- 2K屏+潛望長焦+7000mAh,定價四千元內,紅米這次要KO大哥了
- 余承東預熱新款三折疊,這次有手寫筆和新顏色,發布會定檔9月4日
- 蘋果發布會邀請函解讀:網頁源代碼暗藏關鍵細節
- 首款曲面iPhone上熱搜!這次真換外觀了