
文章圖片

文章圖片
文章圖片
想象一個虛擬人 , 他不僅能精準地對上你的口型 , 還能在你講到關鍵點時做出恍然大悟的表情 , 在你講述悲傷故事時流露出同情的神態 , 甚至能根據你的話語邏輯做出有意義的手勢 。
這不再是科幻電影的場景 。 8 月底 , 字節跳動數字人團隊推出了 OmniHuman-1.5 , 提出了一種全新的虛擬人生成框架 , 讓虛擬人真正擁有了「思考」和 「表達」的能力 。
數月前 OmniHuman-1 上線時 , 曾引發國內外熱潮 。 相比前作 , 1.5 版本有了更多突破 , 不僅可以根據文字指令讓虛擬人在對口型之余做出指定動作、表情 , 還支持在多人場景中控制發言者以外的角色做出具體動作 。 據悉 , 新版本很快也將上線即夢 AI 。
論文鏈接: https://arxiv.org/abs/2508.19209 項目主頁: https://omnihuman-lab.github.io/v1_5/
一個「會思考」的虛擬人是什么樣?
傳統虛擬人總感覺差了點「靈魂」 , 動作機械、重復 , 而 OmniHuman-1.5 首次將諾貝爾獎得主丹尼爾?卡尼曼的「雙系統理論」引入 AI , 通過一個由多模態大語言模型(MLLM)驅動的「思考大腦」 , 讓虛擬人學會了深思熟慮 。
在深入技術細節之前 , 先用最直觀的方式 , 感受一下這個框架創造出的虛擬人 , 究竟有何不同:
超越簡單的模仿 , 模型展現了邏輯推理能力 。 它能準確理解指令 , 按順序拿出紅藍藥丸 , 執行復雜的動作意圖 。
虛擬人精準地根據語音內容規劃動作 , 實現了「先畫眼線 , 再介紹眼影盤」這樣的邏輯序列 , 展現了對內容的理解 。
挑戰長視頻與多人互動 。 模型不僅能生成穩定的長時間雙人對唱 , 還能駕馭豐富的運鏡效果 , 同時角色的動作、表情和互動極為多樣 , 告別了單調重復 。
虛擬人學會了「傾聽」 。 它可以在對話和傾聽狀態間自如切換 , 說話時的情緒與內容匹配 。
【會「思考」!字節跳動發布OmniHuman-1.5,讓虛擬人擁有邏輯靈魂】
除了高動態場景 , 還是需要細膩情感表達的獨白 , 模型都能拿捏 , 展現出了表演張力 。
雙系統框架為虛擬人裝上「大腦」
近年來 , 視頻虛擬人技術發展迅猛 , 從最初的口型合成 , 進化到了半身乃至全身的動畫生成 。 大家的目標也越來越宏大:創造一個與真人無異 , 既能理性行動又能真實表達情感的「數字生命」 。
然而 , 盡管現有方法(尤其是基于 Diffusion Transformer 的模型)能夠生成與音頻同步的流暢視頻 , 但它們更像一個出色的「反應機器」 。 仔細觀察你會發現 , 這些模型捕捉到的僅僅是音頻信號與身體動作之間的淺層、直接關聯 。 結果就是 , 虛擬人能精準地對上口型 , 做一些簡單的、跟隨節奏的擺動 , 但一旦涉及更復雜的、需要理解對話內容的交互 , 就立刻「露餡」了 。 它們的行為缺乏長期規劃和邏輯一致性 , 離真正的「以假亂真」還有很長的路要走 。
為什么會這樣?研究者們從認知科學中找到了答案 。 人類的行為被認為由兩個系統主導:
系統 1(System 1): 快速、無意識、自動化的反應系統 。 對于虛擬人而言 , 這就像是驅動嘴部肌肉發出聲音 , 或下意識的身體搖晃 。 這與當前模型的工作模式非常相似 。
系統 2(System 2): 緩慢、有意識、需要努力的分析系統 。 這對應著根據對話內容 , 組織一個有意義且契合語境的表情或手勢 。 這是當前模型普遍缺乏的能力 。
顯然 , 要讓虛擬人「活」起來 , 就必須為它裝上「系統 2」這個深思熟慮的大腦 。 因此 , 本文的核心思路應運而生:利用多模態大語言模型(MLLM)強大的推理能力來顯式地模擬「系統 2」的決策過程 , 并將其與模擬「系統 1」的反應式生成模塊相結合 。
為了實現這一構想 , 研究者們設計了一個精巧的「雙系統模擬框架」 。 它主要由兩部分構成:一個負責規劃的「系統 2」大腦 , 和一個負責渲染的「系統 1」身體 。
圖注: 框架流程圖 。 左側為總體流程 , 展示了「系統 2」如何利用 MLLM 智能體對所有輸入(音、圖、文)進行推理 , 生成一個宏觀的「行為規劃表」(Schedule) 。 這個規劃表隨后指導「系統 1」的 MMDiT 網絡 , 后者在其專用的文本、音頻和視頻分支中融合信息 , 最終合成視頻 。 右側是關鍵模塊的細節圖 。
1. 系統 2:MLLM 智能體進行深思熟慮的規劃
這部分是整個框架的「大腦」和「指揮中心」 。 研究者設計了一個由兩個 MLLM 組成的智能體(Agent)推理流程:
分析器(Analyzer): 第一個 MLLM 負責「情景分析」 。 它接收角色的參考圖、音頻、以及用戶可選的文本提示 , 然后像一個偵探一樣 , 分析出角色的性格、情緒、意圖以及周圍環境 , 并輸出結構化的分析結果 規劃器(Planner): 第二個 MLLM 接收「分析器」的結論 , 并基于此制定一個詳細的「行動計劃」 。 這個計劃被構造成一個鏡頭序列 , 為視頻的每一小段都定義了角色的表情和動作 。通過這種「分析 - 規劃」的協作 , 模型得以生成一個全局一致、邏輯連貫的行動計劃 , 為虛擬人的行為提供了「頂層設計」 。
2. 系統 1:多模態融合網絡進行反應式渲染
有了「大腦」的規劃 , 還需要一個強大的「身體」來執行 。 這部分由一個特殊設計的多模態擴散模型(MMDiT)承擔 , 它負責將「系統 2」的高層文本規劃與「系統 1」的底層音頻信號(用于口型同步等)完美融合 , 生成最終視頻 。
然而 , 將文本、音頻、參考圖這幾種完全不同的信息(模態)塞進一個模型里 , 極易引發「模態沖突」 , 導致模型顧此失彼 。 為此 , 研究者提出了兩大核心技術創新來解決這個難題 。
如何讓「大腦」與「身體」高效協作?
1. 重新思考身份維持:「偽最終幀」的設計
傳統方法為了讓虛擬人保持固定的身份(長相) , 通常會在模型中輸入一張參考圖 。 但研究者敏銳地發現 , 這會帶來一個嚴重的問題:模型會錯誤地學習到「生成的視頻里必須出現和參考圖一模一樣的畫面」 , 這極大地限制了角色的動態范圍 , 導致動作僵硬 。
圖注: 該圖解釋了為什么需要 “偽最終幀” 。 右側揭示了核心困境:當參考圖與目標片段內容高度相關時(綠色區域) , 會限制動作多樣性;而當二者不相關時(紅色區域) , 又會導致生成內容與參考圖出現預期外的偏差 。
為此 , 他們提出了一個名為偽最終?。 ≒seudo Last Frame)的解決方案 。
訓練時: 完全拋棄參考圖 。 模型只學習根據視頻的「第一幀」和「最后一幀」 來進行預測 。
推理時: 將用戶提供的參考圖巧妙地放在「最后一幀」的位置上 , 并告訴模型這是一個「偽」的最終幀 。這個「偽最終幀」就像一根「掛在驢子眼前的胡蘿卜」:它引導著模型朝參考圖的身份特征生成 , 但從不強迫模型必須一模一樣地復現它 。 實驗證明 , 這種方法完美地在「身份一致性」和「動作多樣性」之間取得了平衡 。
2. 解決模態沖突:「對稱融合」與「兩階段預熱」
為了讓文本(系統 2 規劃)和音頻(系統 1 信號)更好地協作 , 研究者為音頻信號也設計了一個獨立的、與視頻和文本分支結構對稱的「音頻分支」 。 這三個分支在模型的每一層都通過共享的自注意力機制進行深度融合 , 確保信息充分對齊 。
但新的問題來了:音頻信號在時間上非常密集 , 模型在聯合訓練時會偷懶 , 傾向于只依賴音頻來做所有預測 , 從而忽略了文本提供的高層語義指導 。 這就是「模態沖突」 。
研究者的解決方案是「兩階段預熱(Two-stage Warm-up)」訓練策略:
第一階段: 先在一個「小模型」上強制讓三個分支一起工作 。 這逼迫模型學會 「分工」:文本和視頻分支負責宏觀語義 , 音頻分支則專注于自己的核心任務(如口型、語音風格) 。
第二階段: 將預訓練好的主模型(文本和視頻分支)與第一階段「預熱」過的音頻分支組合起來 , 再進行微調 。
通過這種方式 , 每個分支都帶著自己最擅長的「先驗知識」進入最終的訓練 , 從而有效避免了模態沖突 , 讓「大腦」的指令和「身體」的反應都能得到忠實執行 。
效果對比
除了直觀的效果展示 , 硬核的量化數據和直接的 SOTA 對比更能說明問題 。
1.Agent 推理 + MMDiT 架構的有效性驗證
圖注: 消融實驗(Ablation Study)的結果清晰地證明了框架中兩大核心設計的有效性 。 從數據中可以看到 , 無論是負責 “思考” 的 Agent 推理模塊 , 還是負責 “執行” 的 MMDiT 架構 , 都對最終的生成質量 , 尤其是在邏輯性和語義連貫性上 , 做出了不可或缺的貢獻 。
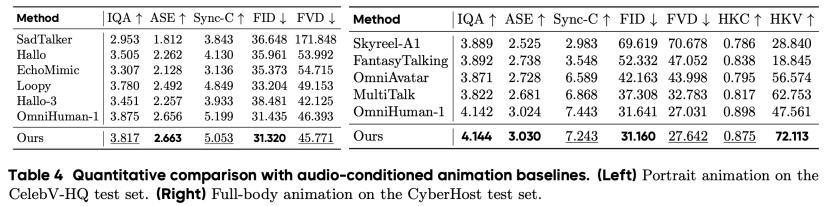
2. 全面超越 SOTA 模型
圖注: 在與當前最先進(SOTA)的多個公開模型進行的全方位對比中 , 本方法在所有關鍵指標上都取得了顯著優勢或極具競爭力的表現 。
圖注: 這張可視化對比圖直觀地展示了「思考能力」的價值 。 相比于沒有推理能力加持、只會做簡單說話和重復性動作的模型方案 , OmniHuman-1.5 顯示了更高的動態范圍和更有邏輯性的動作效果 , 實現了從「動嘴」到 「表達」的飛躍 。
總結與展望
Omnihuman-1.5 為虛擬人領域提供了一個全新的、極具啟發性的視角 。 它通過借鑒認知科學的「雙系統理論」 , 巧妙地利用 MLLM 作為「系統 2」的推理核心 , 并設計了一套創新的多模態融合架構來解決關鍵的技術瓶頸 , 最終實現了虛擬人行為從「反應式」到「思考式」的飛躍 。
目前即夢 AI 視頻生成中對口型能力的大師模式是基于 Omnihuaman-1.0 , 依靠一張圖 + 一段音頻就能生成流暢自然的虛擬人視頻 。 很快 OmniHuman-1.5 也將上線即夢 AI 。 相比 1.0 版本 , Omnihuaman-1.5 不僅可以生成更加真實、靈動的虛擬人 , 也為人機交互、影視制作、虛擬社交等領域帶來新的可能 。
推薦閱讀










- Nano Banana爆火之后,一個神秘的「胡蘿卜」代碼模型又上線了
- 這個荒誕網站藏著30個AI「鬼點子」,但我覺得它活不長
- 三星Galaxy秋季新品品鑒會在京舉行: 多款智能生態新品齊亮相
- 小米Civi 6再次被確認:產品定義大調整,發布時間會較晚!
- 超30款新品齊上陣,追覓場景新品發布會一文看懂
- 24999 元!華為推了一個「最大」的 Mate!
- 83歲用DeepSeek搶單96歲憑AI掙養老錢!這群80+老人比你還會玩AI
- 特斯拉下一代金色Optimus原型現身?一雙「假手」成為最大槽點
- 2025天生會畫數字創作大賽將于9月19日開啟:新增設逐幀動畫組別
- 「一句話生成爆款視頻」,這款 AI 流量神器有點東西|AI 上新