
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
克雷西 發自 凹非寺
量子位 | 公眾號 QbitAI
能看懂視頻并進行跨模態推理的大模型Keye-VL 1.5 , 快手開源了 。
相比此前的預覽版本 , Keye-VL 1.5的時序定位能力進一步升級 , 并且支持跨模態推理 。
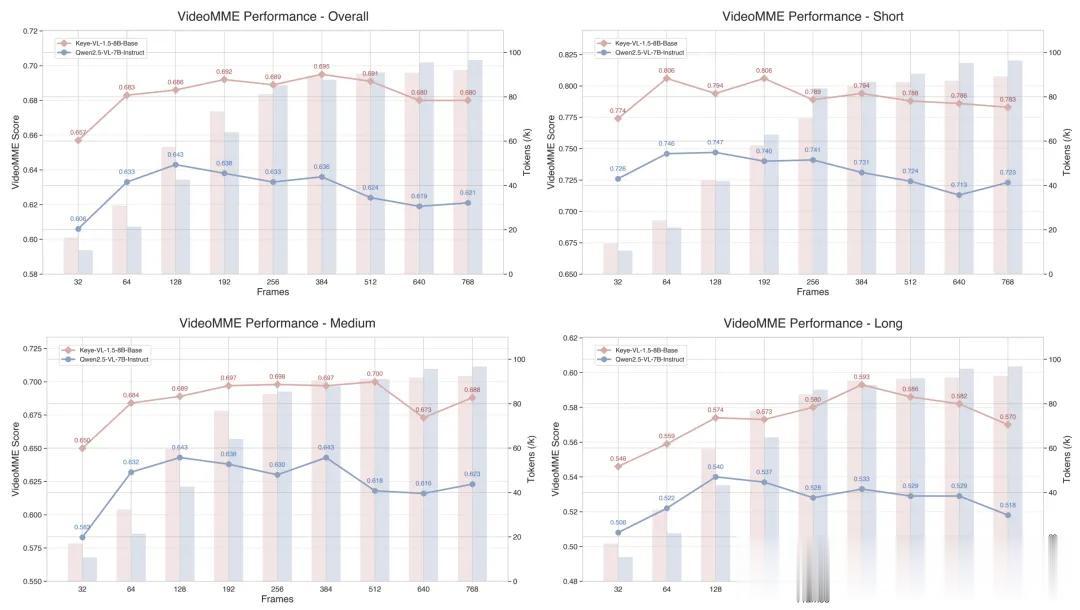
還創新性地提出Slow-Fast雙路編碼機制 , 給模型帶來了128k的超長上下文窗口 , 而且速度與細節兼顧 。
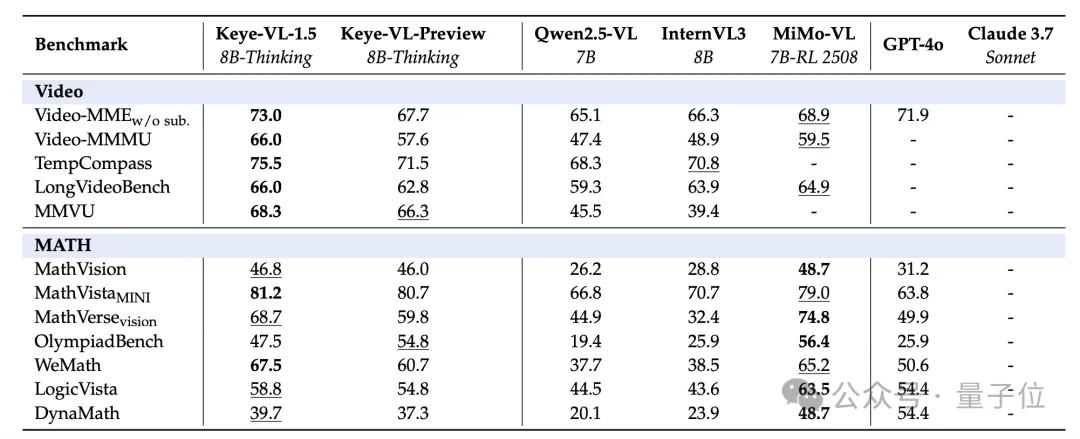
成績上 , 不僅在Video-MME短視頻基準斬獲73.0的高分 , 還在通用、視頻和推理場景的大量Benchmark當中領跑同級模型 。
視頻元素0.1秒級定位 , 還支持推理要說Keye-VL-1.5最大的亮點 , 研究團隊認為主要有三個 , 也就是開頭提到的128k上下文、突出的短視頻理解能力、 以及更強的Reasoning能力 。
在視頻理解場景當中 , 這三項能力能夠同時得以展現 。
首先是時序信息理解 , Keye-VL-1.5能夠準確判斷特定物品在視頻中出現的時間點 , 而且精確到0.1秒級 。
比如在這段26秒帶貨視頻片段中 , 介紹了一款充電寶 , 其中一個環節是將其裝進包包 , 以體現便于攜帶 。
Keye-VL-1.5看完這段視頻后 , 準確回答出了其中包包出現的時間——22.3-23.8秒 。
而其他模型或者時間只精確到秒而且還不準確 , 或者干脆不說時間 , 直接數起了鏡頭 。
再來是描述能力 , Keye-VL-1.5能夠詳細描述視頻畫面場景和細節 。
例如對于上面這段視頻 , Keye-VL-1.5給出了這樣的描述:
并且Keye-VL-1.5還具備視頻推理能力 , 能夠根據前序視頻內容推斷后續事件發生原因 。
在這段寵物視頻當中 , 大狗做出了一個咬小狗耳朵的動作 , 而Keye-VL-1.5要分析大狗為什么要咬 。
其實答案在視頻當中已經以文字的形式寫了出來 , 但是Keye-VL-1.5的解釋更加詳細 , 并進一步用視頻中的后續變化來加強自己的觀點 。
跑分方面 , Keye-VL-1.5在多項公開Benchmark以及內部評測中都拿到了同尺寸模型中的最高分 。
在MMBench、OpenCompass等綜合類基準中 , Keye-VL-1.5的成績均超越Qwen2.5-VL 7B , 并取得多個SOTA 。
在圖像推理強相關的AI2D、OCRBench等數據集中 , 也均超出同級其他模型 。
針對視頻理解 , Keye在Video-MME、TempCompass和LongVideoBench上 , 成績同樣領先于Qwen2.5-VL 7B等模型 。
包含視覺的數學與邏輯推理維度上 , Keye也保持了領先優勢 。
除了這些公開數據集 , Keye團隊還構建了200條面向短視頻應用的內部多維度評測 。
Keye-VL-1.5-8B在人類標注的五項指標(正確性、完整性、相關性、流暢度、創造性)上獲得3.53分的綜合成績 , 較預覽版本提升了0.51分 , 也超過了作為對比的競品模型 。
那么 , Keye-VL是如何實現的呢?
視頻理解 , 也用上了快慢思考★模型架構和快慢編碼策略
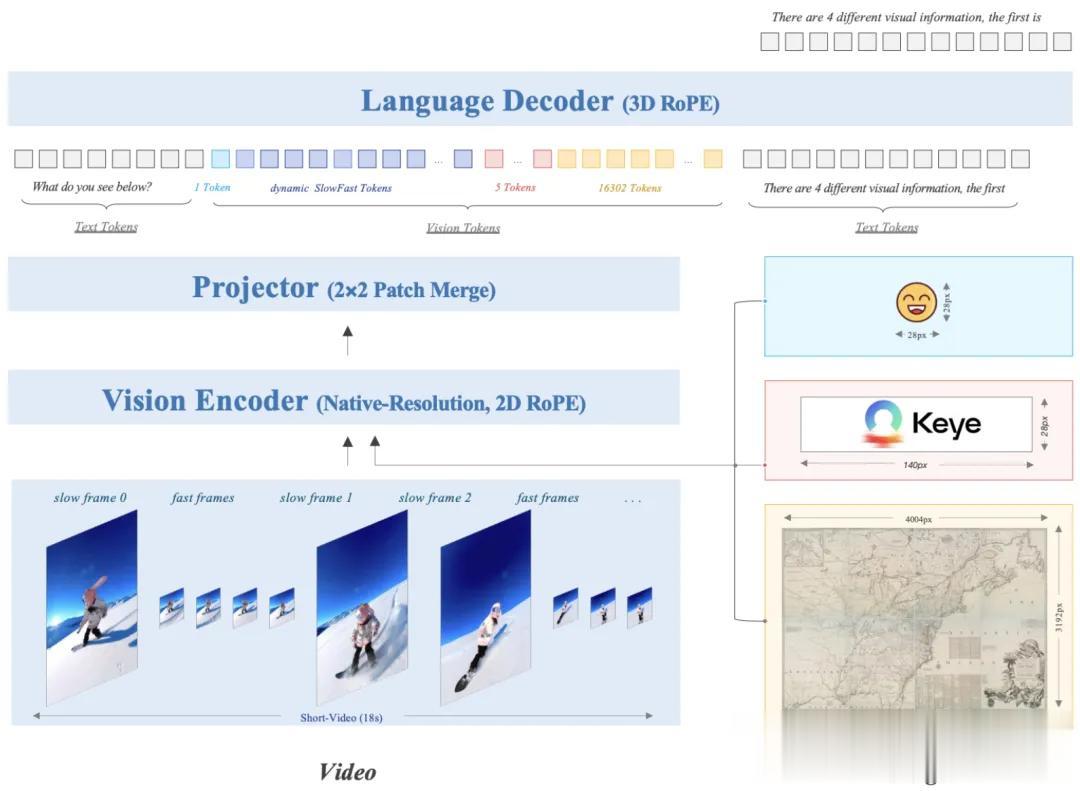
整體設計上 , Keye-VL-1.5采用了“視覺Transformer(ViT)+MLP投影器+語言解碼器”的三段式架構 。
ViT將輸入圖像或視頻幀切成14×14的patch序列 , 用自注意力捕捉全局空間關系 。
該ViT在初始化時直接繼承SigLIP-400M參數 , SigLIP是一種圖文對比預訓練方法 , 可讓視覺特征天然帶有語義對齊能力 。
為了在不裁剪的情況下處理任意分辨率 , 團隊對ViT添加了“原生分辨率”支持 , 操作上先把絕對位置向量插值到任意尺寸 , 再引入2DRoPE(二維旋轉位置編碼)增強高分辨率外推 。
ViT輸出的patch特征經由兩層MLP投影器送入語言解碼器 , 語言端采用Qwen3-8B , 并在其位置編碼中加入3DRoPE 。
3DRoPE是在傳統二維旋轉角的基礎上再增加一維“時間/深度”角度 , 目的是讓文本token與視覺token按統一時序排序 。
針對視頻的高幀率與高分辨率矛盾 , Keye-VL-1.5還創新性地提出Slow-Fast編碼策略 。
模型首先會對連續幀做patch級余弦相似度計算 , 若與最近一次“慢幀”(又稱變化幀 , 低幀數高分辨率)相似度95%則判定為“快幀” (又稱靜止幀 , 高幀數低分辨率) , 否則標記為新“慢幀” 。
處理時 , 慢幀保留高分辨率 , 快幀分配慢幀30%的token預算 , 再結合二分搜索 , 能夠讓總預算精確落在限制內 , 并在序列里插入時間戳特殊符號以標注幀界 。
通過這種視頻快慢編碼策略 , Keye實現了性能與計算成本的有效平衡 。
★四階段漸進式預訓練
預訓練采取四階段漸進流水線 , 按照“先單模后多模、先對齊后擴窗”的順序展開:
Stage0 , 視覺編碼器預訓練:僅用SigLIP對比損失繼續訓練ViT , 強化視覺語義 , 適應內部數據分布; Stage1 , 跨模態對齊:凍結ViT與Qwen , 只訓練MLP投影器進行大規模跨模態對齊; Stage2 , 多任務預訓練:解凍全網絡 , 在8K上下文下端到端優化 , 增強模型的基礎視覺理解能力; Stage3 , 退火訓練: 在精選高質量數據上進行微調 , 引入長上下文模態數據 , 把上下文拉長到128K 。
整個預訓練語料超過1萬億token , 數據源既包含LAION、DataComp、CC12M等公開多語言圖文庫 , 也有大規模自建圖像、視頻與文本 。
四階段結束后 , Keye團隊對不同數據配比訓練的“同質”權重與針對OCR、數學等薄弱項單獨強化得到的“異質”權重進行模型融合 , 以減小偏差并提升魯棒性 。
“同質模型”指的是在退火期采用相同網絡結構和相似任務目標 , 但調整數據配比、樣本難度或隨機種子訓練出的多份主干權重 , 這些模型彼此性能分布接近;
“異質模型”則是利用與主干不同的專用數據域進行進一步精調而生成的專家權重 , 例如團隊針對車牌、票據和街景文字額外收集/合成數據訓練出的OCR-Expert 。
由于雙方架構一致 , 融合過程可以通過直接權重插值實現 , 不引入推理時額外開銷 , 卻能將專家的局部能力注入通用模型 。
★Post-training
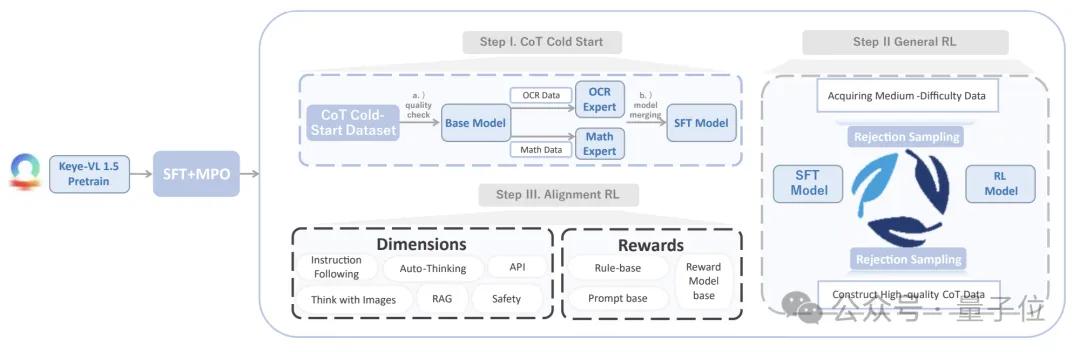
Keye-VL-1.5的訓練后處理包含四個主要階段:
第一步用監督微調結合多偏好優化(MPO)建立輸出質量基線; 第二步通過五步流水線的大規模鏈式思考數據冷啟動 , 為模型提供可靠的推理示范; 第三步在可驗證獎勵框架下采用GSPO算法并配合漸進提示采樣做多輪強化學習 , 系統化提升通用推理能力; 最后一步以規則-生成式-模型三源獎勵完成對齊強化學習 , 重點加強指令遵循、格式一致性與用戶偏好一致性 。
在監督微調階段 , 團隊先構建包含750萬多模態問答的候選池 , 用TaskGalaxy將樣本映射到七萬種任務標簽 , 再刻意提高高難度類型的占比 。
隨后進入MPO , 以25萬開源、15萬純文本和2.6萬人工樣本為基底 , 利用Keye-Reward模型分數和人工評估構造高低質配對 , 通過偏好損失函數讓模型在同一問題上傾向得分更高的答案 , 從而進一步提升回答質量 。
有了質量可控的答案后 , 模型借助鏈式思考冷啟動流水線迅速補齊推理深度 , 先自動生成帶步驟的解答 , 再由第二模型逐步打分進行分級 , 中檔樣本經人工精修后復審 , 高分樣本直接入庫 , 為后續強化學習提供可靠冷啟動權重 。
接下來進入通用強化學習 , 系統首先按照樣本難度分組 , 然后利用GSPO在組內基于序列重要性權重裁剪優勢函數 , 緩解長序列梯度不穩 。
當推理能力趨于收斂后 , 訓練轉入最后的對齊階段 。
規則獎勵通過正則和AST解析強制檢查JSON、Markdown等結構與內容安全 , 生成式獎勵由外部大模型評估邏輯一致性與語言風格 , 模型獎勵則來自Keye-Reward模型的細粒度偏好分 。
三類信號動態加權 , 使最終模型既能遵循指令又能保持格式正確并符合用戶偏好 , 同時有效降低無依據生成風險 。
團隊成果多次亮相頂會說到快手大模型 , 我們可能更熟悉視頻生成模型可靈 , 但實際上 , 快手在其他類型的大模型上同樣有很強的實力 。
打造Keye-VL的Keye團隊 , 是快手內部專注多模態大語言模型研發的核心AI部門 , 主攻視頻理解、視覺感知與推理等前沿方向 。
Keye團隊認為 , 整合視覺、語言和行為等多源數據的智能體 , 對于解鎖更深層次的認知和決策至關重要 。
目前 , Keye團隊已經擁有大量成果 , 在今年的多個頂會上密集發布 。
ICML 2025上 , Keye團隊提出了多模態RLHF框架MM-RLHF(2502.10391) , 通過120k人類偏好對比與批評式獎勵模型 , 顯著提升MLLM安全性及對齊性能 。
KDD 2025上 , 視覺語言模型治理框架VLM as Policy(2504.14904)獲得了最佳論文提名 。
該框架通過VLM驅動內容質量與風險判定 , 顯著提高短視頻審核效率與準確率 。
CVPR 2025上 , Keye團隊也發布了兩項成果 。
交錯圖文多模態數據集CoMM(2406.10462) , 提供了高一致性圖文敘事樣本 , 從而增強模型圖文穿插理解與生成能力 。
視覺token壓縮加速算法LibraMerging , 采用位置驅動合并 , 在無需再訓練的情況下大幅降低推理開銷 。
還有ICLR 2025中 , Keye有三項研究成果亮相 , 包括一種優化算法和兩個數據集 。
MoE模型優化算法STGC(2406.19905) , 可以檢測token梯度沖突并進行重路由 , 提升專家利用率與收斂速度 。
視頻對話理解基準SVBench(2502.10810) , 構建了時序多輪問答鏈 , 評測LVLM在流式長視頻場景的推理水平 。
還有視覺任務指令數據集TaskGalaxy(2502.09925) , 可以自動生成萬級層級任務與40萬余樣本 , 增強模型跨任務泛化能力 。
在快手內部 , Keye團隊的這一系列成果 , 正在為短視頻內容審核、智能剪輯、搜索與互動推薦等業務場景提供底層AI能力 。
Keye正在把多模態技術從實驗環境推向千萬級日常場景 , 驗證復雜視頻理解在真實業務中可行且高效 , 為同類技術的工程化落地提供了直接樣本 。
技術報告:https://arxiv.org/pdf/2509.01563代碼:https://github.com/Kwai-Keye/Keye/blob/main/Kwai_Keye_v1_5.pdf模型權重:https://huggingface.co/Kwai-Keye/Keye-VL-1.5-8B在線DEMO:https://huggingface.co/spaces/Kwai-Keye/Keye-VL-1_5-8B
— 完 —
量子位 QbitAI
【視頻理解新標桿,快手多模態推理模型開源】關注我們 , 第一時間獲知前沿科技動態
推薦閱讀














- 「一句話生成爆款視頻」,這款 AI 流量神器有點東西|AI 上新
- 重新定義個性化視頻體驗,快手與清華聯合提出靈犀系統
- 提升全面,右手對稱鼠標新標桿!體驗雷柏VT7系列雙模雙高速游戲鼠標
- 跟谷歌學壞了,三星也發視頻“陰陽”蘋果沒有折疊屏,AI也不行
- 群核科技發布空間大模型,旨在解決AI視頻空間一致性難題
- DJI Mic 3首發評測:機身mini體驗旗艦,無線麥克風新標桿?
- vivo Y500評測:超耐用大電池,入門機新標桿
- 剛剛,大模型裝上鷹眼!首創高刷視頻理解,谷歌Gemini 2.5完敗
- Reels支持翻譯對口型,Meta短視頻的“全村希望”正在靠AI突圍
- 視頻產業的創意活力,被百度蒸汽機這顆“動力心臟”激活了