文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

前一陣子馬斯克說碳基生命是硅基生命的過渡體 , 到底是對是錯呢?
我想從人工智能近年來的進化展開聊聊 。
人工智能近兩年來 , 從大的框架角度來說 , 完成了大語言模型的設計、基于大語言模型的AI agent的構造、多模態內容生成的實現 。
從學習策略來看 , 監督微調正走向自監督學習 , 以盡量減少人類標注的需求 , 再通過強化學習來改進其對未知問題的學習能力 。
在此大方向指引下 , 我們看到了大量的人工智能應用落地 。
但從本質上來看 , 都離不開學習二字 。
只不過與人類的學習不同 , 人工智能目前的學習方式是極度耗能、需要巨量數據和依賴大量參數的學習模型 。
由于模型過于龐大 , 其中充斥了大量的非線性函數變換 , 以至于想從中找到可解釋性變得異常困難 。
也由于其強非線性的特點 , 以至于數學大牛陶哲軒都在吐槽 , 說目前的數學界沒有在此波人工智能熱潮上發力 。
實際上也是如此 , 與人工智能最接近的數學 , 是經常不被純數學認可的統計學 。
比如復旦 , 統計學都沒放在數學學院 , 而歸屬于管理學院 。
但統計學研究的內容多數是線性框架下展開的 。
這里的線性指的是直線 , 而非線性則是拋物線、雙曲線 。 強非線性則更為復雜 。
而數學領域目前非線性程度較大的研究分支是微分流形、拓撲等 。
然而 , 這樣的幾何學一般會假設局部線性 , 長程和復雜的非線性結構并不容易得到好的表征 , 尤其在人工智能的數據常常被表現成離散點后 。
要想讓數學在強非線性的人工智能時代發揮更大的作用 , 可能需要一套新的理論體系 。
正是依賴于模型里蘊含的強非線性 , 人工智能這一波表示出的學習能力已經開始將人類不少方面自以為的學習優勢變得不值一提 。
比如圍棋 。
現在人工智能模型的圍棋訓練 , 基本不需要依賴人類 , 因為也沒有哪個人類棋手的棋力還值得AI的圍棋模型去學習 。
人類與AI對弈時 , 也能發現其棋風有的時候很明顯不是人類棋手能下出來的 。 這意味著 , AI在圍棋上的博弈水平已經凌駕于人類之上 。
再比如繪畫 。
今年OpenAI的GPT-4o的文生圖功能推出后 , 我們能看到不同風格的繪畫能快速通過該模型生成 。 而如果讓人類畫家來畫 , 很有可能得花一天或更長的時間才能完成 。
雖然前者仍然存在不少的瑕疵 , 比如合照在轉換時會丟人、漢字生成仍然存在明顯的錯誤等 , 但按性價比來取代中流水平的畫家 , 已經不是不可能 。
或者再比如視頻生成 。
國慶假期 , OpenAI剛剛推出的Sora 2再次刷新了人們對于AI生成視頻的認知 。 不論是從畫面真實度、物理一致性、鏡頭運動、人物表情與情緒細節、故事敘事能力、還是生成速度與穩定性等方面 , 都展現出了前所未有的突破 。
但Sora 2的問題在于 , 這些看似完美的結果其實都是「AI的腦補」 。
最終結果是AI說了算 , 而且不穩定 。
即使是編程這一人工智能進化必須依賴的工具 。
從其學習出來的結果 , 也能看出人工智能編出來的程序規范工整、像模像樣 , 畢竟知名大模型的研發都是無數清北復交這樣水平或相當水平的碼農在參與 。
其可讀性比一般人寫得要好得多 。 如果對相關代碼熟悉的 , 只需要對大模型給出的代碼進行針對性的改進 , 就能快速形成能跑通特定任務的代碼 。
有的時候 , 看著人工智能生成的代碼 , 我都會暗想 , 平時考試就考不過這些參與編程的碼農 , 現在人家還抱團集思廣義來做大模型 , 再加上大模型自己還能自我進化 。
要想超越人工智能編出的代碼 , 有可能在未來只是一種夢想 。
由這些例子可以推測 , 人工智能模型的某些學習能力已經超越人類了 。
但是否意味著人工智能會全方位超越人類呢?
這要回顧下1980年代的莫拉維克悖論以及1990年左右統計機器學習曾經流行的概念「轉導學習」 。
莫拉維克悖論發現人工智能在學習的過程中 , 有一個特別有趣的現象 , 即人覺得簡單的問題 , 機器會覺得復雜;人覺得復雜的 , 機器反而覺得簡單 。
在此悖論下 , 我們常以為的簡單易重復的工作容易被AI淘汰 , 實際指的是AI覺得簡單、可以方便其重復的工作 。
與「AI認為簡單易重復 , 而人類卻覺得復雜」相關的 , 其中一個重要元素就是學習 。
對高階知識的吸取、對抽象技能的把握 , 人類向來覺得非常復雜 , 于是我們不得不花漫長的時間來學習 。
它也是幫助人類區分于自然界其它生命的重要指標 。
自然界里 , 從來沒有其他動物可以像人這樣耗盡人生的一大半來上下求索 。
但是在當前的人工智能時代 , 一個一個AI新成果的出現 , 似乎又在暗示著 , 人類的學習恰恰是AI更為擅長的 。
只不過 , AI采用了更為簡單粗暴的方式 , 即有技巧的窮盡一切可能 , 從而獲得比人類學習規律、學習知識更為全面完整的集合 , 而每個人類能學到的規律知識只是它的一個非常小的真子集 。
如果這一假設成立 , 那很有可能與學習相關的多數行業會被AI替代 。
能在行業中繼續生存下來的 , 也許只能是那些百里挑一甚至萬里挑一的、行行里出的狀元 。
不過 , 獲得全集并非沒有代價 。
這些代價 , 會讓人工智能實際上無法取代所有與學習相關的行業 , 比如高能耗的代價、高質量標注的代價 , 諸如此類 。
也讓他在進行判斷時無法像人類一樣在某些場合可以做出快速判斷 。
而這其中的差異又可以再聊聊另一種學習機制 , 轉導學習(Transduction) 。
轉導學習在深度學習興起之前 , 由統計機器學習先驅萬普尼克(Vapnik)提出的觀點 。
Induction deriving the function from the given data.
Deduction deriving the values of the given function for points of interest.
Transduction deriving the values of the unknown function for points of interest from the given data.
歸納 , 從給定數據推導函數 。
演繹 , 從給定函數推導感興趣點的取值 。
轉導 , 從給定數據為感興趣點推導未知函數的取值 。
他認為當一個問題過于復雜 , 而實際要解決的只是問題的一個子集時 , 沒有必要針對原問題進行精確求解 , 只需要針對子集來尋找替代方案即可 。
這樣就能用相對簡單的函數 , 來刻畫本需要復雜函數才能表征的原問題 , 在子集下的預測 。
或者反過來說 , 如果手頭想解決的是一個問題的子集 , 我們就沒必要把子集的問題復雜化到去求一個遠比手頭問題困難得多的任務上 。
這一觀點 , 在統計機器學習時代是有效的 。 因為那時的數據集相對較小 , 算力也不強 , 所以統計機器在當時是占主流地位 , 而深度學習的前身神經網絡則話語權弱得多 。
類似于轉導學習 , 我們可以再比較下人工智能的深度模型及人類在學習機制上的差異 。 顯然 , 如前所述 , 人工智能目前的主流做法是堆算力、上數據量、加深網絡 , 從某種意義來看 , 它是希望對通用人工智能問題進行求解 , 所以需要學習出一個極其復雜的函數 。
而人類并非如此 , 對人類來說 , 腦容量是有限的 , 不可能把進入大腦的信息事無具細全部記住 , 所以一直都是在找各種簡化的解釋性或規律 , 不管是歸納還是演繹 , 還是常說的快慢思維轉化 , 本質上都是在做減法 , 以便在具體的問題上形成簡單有效的決策和預測 。
這也可以算是人類對世界規律學習中做的轉導學習 。
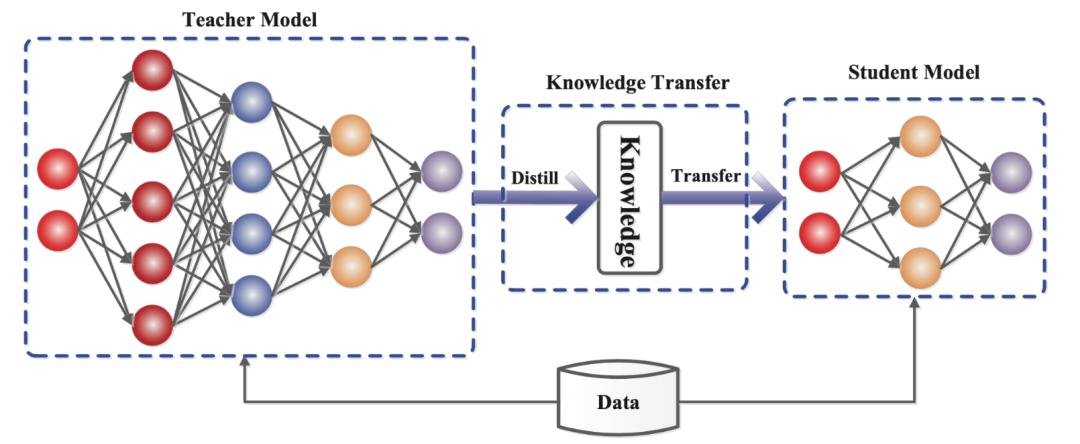
但這種學習又并不能等同于人工智能當下喜歡講的蒸餾 , 蒸餾一般是模型大小上的區別 , 從教師模型中學習知識 , 轉為小模型的有用信息 , 幫助小模型獲得更好的性能 。
而轉導則是結構上存在本質差異 , 類似從慢思維中總結出快思維的規則 , 類似于高中生刷了很多題后 , 能快速找到捷徑一樣 。
由于我們對大腦的認識還遠遠不夠 , 人類這種轉導學習的機理尚沒有得到完美答案 。
雖然有一些被人工智能學走了 , 比如一部分思維鏈 。 但要弄明白全部的機理 , 尚需時日 。
這也就意味著 , 人工智能至少在目前還無法完全取代人類 。
但一旦全部機理能被弄明白 , 并能夠程序化、流程化 , 理論上人工智能都能學會 。
到那時 , 人類在知識方面的學習 , 對人工智能來說 , 會像學人類的圍棋一樣 , 沒有任何意義了 。
當人工智能達到這個水平時 , 也許在不久的將來 , 人類會產生一類新的工作 , 就是解讀人工智能在不同領域里生成的成果 。
以數學為例 , 不久將來的人工智能也許能具備強大的推理能力 , 可以發現一些復雜且新奇的數學定理或證明 。
但因為其思維邏輯有可能不同于人類 , 所以 , 需要有對相關問題精通的數學專業人士對其證明進行解讀 , 再以多數數學家可以理解的方式進行重新詮釋 , 整理成論文發表 。 它意味著 , 即使是「解讀師」 , 也需要進行專業知識的學習 。
人類也可能不得不對人工智能和人類自己做的產品進行分類標注 , 否則人類做的產品在數量級和質量級上都可能不占優勢 。
為了能從產品中找到一絲人類個性化的味道 , 可能人工智能做的會標明AI-made , 人類做的Human-made , 人機協作的是Human-AI-Augmented-made , 就像現在的預制菜一樣進行相對明顯的標識 , 人類做的更有那種現炒的感覺 。
人們可以根據自己的需求來選擇使用哪種 , 喜歡原生態的就用Human-made的 , 喜歡價廉物美的就是AI-made , 兩者皆可的還能選人機協作的 。
當然 , 理論歸理論 , 實際上人工智能應該還達不到我們假想的那種高度 。
因為莫拉維論悖論中還有一塊是人類覺得簡單、機器認為復雜的 。
這一塊仍然有許多無法被人工智能學習到 。
哪些是人工智能未來仍然會覺得復雜的呢?
自然進化賦予人類的、與生俱來的能力 。
快慢思維的轉換、急智智能的表現、想象力、視角、留白、甚至個人行事的風格、特色 。 屬于小樣本、小概率事件的 , 都不太好學習 , 也無法通過高質量數據來形成統計規律來進行隨后的生成 。
這也是為啥有些人的作品看了兩頁就知道結果 , 歌聽了開頭就知道旋律如何收尾 , 而有些人的作品卻別居一格、易于出圈的原因 。
即使是程序 , 除了人類現今推出的 , 還有自然界演化而來的 , 比如可以按時表達的DNA密碼 。 它本質上也可以看成是一種程序 , 但人類至今沒有完全參透其采用諸如內含子外顯子進行編程的底層邏輯 。 人類搞不明白 , 就無法將其程序化、流程化地喂給AI去學習 。
還有一些是不可計算的 , 比如人類的一些隱性的思維 , 這都無法建模 。
除此以外 , 我相信還有一條規律會保護人類不會被人工智能全方位替代 。
人工智能歸根到底 , 其源代碼是人類設計的 。 而人又無法完全了解自己 。 這就是導致人工智能只有可能超越人類教過它的那一部分 。 人類自己都無法理解的部分 , 也沒法教給人工智能 , 讓其實現超越 。
電影《普羅米修斯》中的人造人大衛 , 在想什么?
如果用稍微晦澀點的語言來說 , 就是哥德爾不確定性原理 。
即一個系統的完美性證明 , 自身是無法獲得的 , 需要有一個系統之外的理論來完成證明 。
如果用通俗點的說法 , 需要有個比人類更聰慧的「外星生命」來降維打擊 。
也許理解人類和人工智能的學習 , 重塑人工智能的時代學習 , 才是未來與人工智能和諧共處最好的辦法 , 也能避免人類被硅基生命取代的可能性 。
最終 , AI會不會取代人類?更多內容和思考可以在作者新書中找到答案 。
作者介紹
張軍平 , 復旦大學教授 , 中國自動化學會普及工作委員會主任 。 研究方向包括人工智能、圖像處理、生物認證、智能交通等 。 著有人工智能科普書和《高質量讀研》系列書籍 。 其中《人工智能的邊界》進入25年中國好書8月推薦書目 。 《人工智能極簡史》2024年獲第19屆文津圖書獎提名圖書(科普類)、2024全國優秀科普圖書作品 。 《愛犯錯的智能體》2020年獲中國科普創作領域最高獎等多個獎項 。
【復旦張軍平:人類是硅基生命過渡體?】本文來自微信公眾號“新智元” , 作者:張軍平 , 36氪經授權發布 。
推薦閱讀














- 英偉達AI以太網平臺拿下大客戶!支撐Meta和甲骨文大規模AI基建
- Intel Lunar Lake處理器首次進入三防平板:要價高達2.6萬!
- 全球首顆,復旦大學創新存儲芯片登Nature,已流片
- 對標Sora 2還免費的國產AI,到底啥水平?
- iPhone Air平替!聯想官宣Air新機本月見,售價或在兩千檔
- 平心而論!關于驍龍8 Gen4和天璣9400,大實話可能讓你清醒
- 亞馬遜Quick Suite:企業智能體AI的入門訓練平臺
- 蘋果平替電容筆到底好用嗎?甄選10大平替apple pencil的筆推薦!
- 重磅!華為新專利曝光:平面+垂直晶體管融合,芯片性能再躍升
- 平心而論!1099元金剛品質手機,從拼參數到拼耐用的轉變