文章圖片

文章圖片

文章圖片
文章圖片
近日 , 來自阿聯酋穆罕默德·本·扎耶德人工智能大學 MBZUAI 和保加利亞 INSAIT 研究所的研究人員發現一個針對大模型單次推理的“法諾式準確率上限” , 借此不僅揭示了單次生成范式的根本性脆弱點 , 也揭示了“準確率懸崖”這一現象 。
“準確率懸崖”現象指的是 , 當模型任務的信息需求量超過模型的單次輸出能力時 , 模型性能會出現下降且下降趨勢并不平穩 , 而是會像掉下懸崖一樣急劇和非線性 。
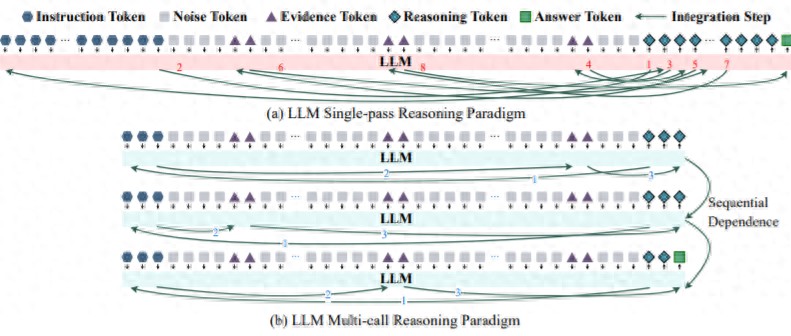
同時 , 他們將這一理論用于多跳問答任務 , 借此對其進行了形式化剖析 , 從而首次揭示了該任務在單次推理范式下失敗的兩個核心規律:“逐步容量溢出”和“跨步錯誤累積” 。
逐步容量溢出 , 指的是隨著推理跳數和上下文噪音的增加 , 任務的信息需求會呈現出超線性增長 , 從而能夠輕易地超出模型的處理容量上限 。
跨步錯誤累積 , 指的是在多步推理鏈中 , 由于容量限制帶來的微小錯誤會被不斷放大 , 最終導致整個推理過程走向失敗 。
(來源:https://arxiv.org/pdf/2509.21199)
基于上述發現 , 該團隊打造出一款名為 InfoQA 的概念驗證多輪調用推理框架 , 它可以通過容量感知的任務分解和主動信息剪枝 , 解決模型在單次推理上的瓶頸 。
為了驗證本次成果 , 他們又構建一個充滿噪音的全新基準測試集 。 實驗結果顯示 , 模型的實際表現與預測曲線是高度吻合的 , 證實了 InfoQA 框架的有效性 。
研究團隊表示 , 這一成果為理解當前大模型的瓶頸分析提供了新的容量診斷視角 。 當處理極端復雜的任務時 , 傳統的模型優化方法比如增加訓練數據、調整模型架構等可能會遇到瓶頸 , 因為這些優化方法只能讓模型更加接近、而無法突破自己的容量上限 。
而本次成果提供了一個全新的診斷視角:即問題根源可能并不是模型不夠“聰明” , 而是任務復雜度超過了模型的“單次處理容量” 。 而這能為多智能體系統的必要性提供堅實的理論依據 , 使其不再只是一個經驗性的選擇 , 而是一個應對容量溢出的根本性解決方案 。
【科學家發現模型單次處理容量上限,多智能體成破局關鍵】
另一方面 , 基于容量診斷的視角 , 研究團隊開辟出了一條更高效的大模型應用優化思路 。 具體來說:
首先是優化任務范式 。 對于特定的復雜任務來說 , 本次理論發現“聰明的任務分解”可能會比“昂貴的模型升級”更具性價比 。 投入海量資源去微調甚至重新訓練一個更大的模型費錢費時 , 而一個更高效、更快捷的路徑則是優化任務本身的工作流 , 通過合理的分解將任務難度控制在現有模型的有效處理范圍之內 。
其次是優化多智能體系統設計 , 讓其從同構走向異構 。 基于本次成果 , 研究團隊設計了更精細同時也更經濟的多智能體系統 。 其認為 , 既然不同的子任務階段對應著不同的信息處理需求 , 那么讓所有智能體都使用同一個骨干大模型無疑會造成資源浪費 。 更好的做法則是設計一個異構型智能體系統 , 讓小巧且高效的模型去處理低復雜度的子任務 , 僅在高信息需求的關鍵節點調用最強大的模型 。
圖 | 相關論文的第一作者萬開陽(來源:萬開陽)
闡明單一模型的物理極限 , 為研究多智能體系統提供嚴謹理論論證
據介紹 , 本次研究的背景源于對當前大模型能力邊界的深入探索 , 并尤其聚焦于大模型在處理復雜用戶指令和長篇文本任務時的表現 。 這一探索的起點源于該團隊此前打造的 CogWriter 。 CogWriter 是一個由人類認知寫作理論啟發的多智能體框架 , 它能顯著提升大模型生成復雜指令限制長文本的能力 。 針對 CogWriter 進行分析和實踐時 , 研究團隊觀察到三個既普遍又引人深思的現象 。
第一個現象是:大模型的能力與參數規模有著強關聯性 。 他們發現 , 模型的參數量是決定其能否執行復雜認知寫作步驟的關鍵因素 。 例如 , 當使用 14B 參數的模型時 , CogWriter 能夠順利執行規劃、反思和修訂等高級認知步驟 。 然而 , 當換用同一系列的、但是參數更少的 8B 模型時 , 模型在執行相同步驟時會產生混亂的計劃和無效的修改反饋 。 這說明模型參數規模與其執行復雜任務的“有效性”之間存在著緊密聯系 。
第二個現象是:大模型的指令遵循能力會隨生成長度呈現出衰減效應 。 當模型在處理長文本時 , 其表現出一種類似于“記憶衰退”的特征 。 在生成任務的初期 , 無論是簡單的單步指令還是復雜的多步指令 , 模型都能很好地遵循 。 然而 , 隨著文本長度的增加 , 模型的指令遵循能力會在某個臨界點后急劇下降 , 以至于“忘記”了最初的目標 。 這種“遺忘”現象在參數量較小的模型上尤為明顯 , 而更大參數量的模型則能將這種衰減進行推遲 。
第三個現象是:多智能體協作會帶來性能提升 。 大量領域內相關成果以及該團隊打造的 CogWriter 證明 , 當將一個復雜任務進行合理分解 , 并分配給多個專門智能體來進行協同處理 , 就能在無需額外訓練的情況下實現任務性能的質的飛躍 。 仍以 CogWriter 為例 , 當使用 Qwen2.5-14B 模型作為骨干時 , CogWriter 能將其在復雜指令任務上的平均準確率從 0.44 提至 0.61 , 這一成績甚至超越了 GPT-4o 的 0.47 的平均準確率 。
這些現象讓該團隊意識到 , 雖然他們已經明確知道類似于 CogWriter 等多智能體框架的分解協作模式是有效的 , 但是他們仍然不清楚背后原因所在:即多智能體協作憑何突破單一模型的瓶頸?這個瓶頸的本質又是什么?
基于以上疑問 , 他們希望為其在 CogWriter 等多智能體系統實踐中觀察到的現象進行理論解釋 , 并希望能在多智能體系統的設計中除了進行經驗性和啟發式的探索之外 , 能夠提供一個物理學式的理論預測視角 。 “這個視角將能闡明單一模型的物理極限 , 并能為多智能體系統產生效果的原因提供理論論證 。 ”萬開陽告訴 DeepTech 。
(來源:https://arxiv.org/pdf/2509.21199)
能否從底層原理上證明單一模型單次生成的瓶頸?
基于業內成果以及實際經驗來看 , 研究團隊認為大模型單次生成存在著一種性能上限瓶頸 , 即使增加數據微調也無法解決這一瓶頸 。 而在無需訓練下的前提之下 , 多智能體系統則能實現顯著的效果提升 。 進一步地 , 在打造多智能體系統的時候 , 智能體對于不同復雜度任務的處理能力存在明顯差異 。
因此 , 他們設想的是:能否超越經驗性和啟發式的研究思路 , 從底層原理上證明單一模型單次生成的瓶頸?以及多智能體系統該如何突破這個瓶頸?再就是到底是需要更多訓練、還是需要通過構建多智能體來突破瓶頸?總的來說 , 他們想探索的問題是:對于單次生成和多智能體這兩者來說 , 到底誰才是解決復雜自然語言處理(NLP , Natural Language Processing)問題的發展方向?
而本次研究的起點 , 則來自于一個關于模型“物理邊界”的直覺 。 這個直覺是:大模型在單次生成中 , 其輸出的 token 數量、每個 token 的表示維度 , 乃至內部注意力與多層感知機(MLP , Multilayer Perceptron)層的矩陣維度都是有限的 。 這些看似孤立的物理約束共同指向這樣一個猜想:在模型的單次推理過程中存在“信息處理的上限” 。
(來源:https://arxiv.org/pdf/2509.21199)
為了從第一性原理出發驗證這一猜想 , 研究團隊追溯到了信息的最基本單元——比特 。 既然計算機中一切數字信息的本質都是比特 , 而大模型的運算與表示也都構建于其上 , 那么信息論這門研究信息量化、存儲和通信的科學便順理成章地成為了他們最基礎的分析工具 。
基于此 , 研究團隊將大模型的單次推理過程抽象為一個處理比特流的“通信信道” 。 正是這一視角的轉換 , 使得他們得以運用信息論的嚴謹框架 , 來推導模型作為信道的信息容量上限 , 以及得以推導與復雜任務所蘊含的信息處理需求之間的數學關系 。
為了驗證并應用這一理論 , 他們又將本次研究課題從“復雜指令長文本生成”拓展至“復雜指令長文本理解” , 并選擇多跳問答任務作為分析對象 。 多跳問答任務要求模型必須在一長段充滿噪音的文本中 , 通過環環相扣的推理鏈找到答案 , 這一特點使其成為測試信息處理上限理論的絕佳場景 。 通過通信信道這樣一個視角 , 使得他們得以深入剖析多跳問答任務的內在結構 , 并揭示了多跳問答任務在單次生成范式下失敗的原因所在 。
隨后 , 他們發現法諾不等式是一個與其課題高度契合的理論工具 , 它能夠連接信息論和機器學習的性能度量 , 即能夠直接將信道中剩余的不確定性與最終的決策錯誤率掛鉤 。 而這正是研究團隊所需要的數學理論基礎 , 這一數學理論基礎能從理論上將“信息處理上限”的猜想轉化為可以量化的“模型準確率上限” 。
基于此 , 他們推導出了本次研究的核心理論:即推導出了一個針對大模型單遍推理的類法諾準確率上界公式 。 這個上界公式指出模型的最高準確率會受到兩個核心變量的制約:第一個制約是任務本身固有的信息需求量 , 第二個制約是模型單次生成所能承載的“信息容量” 。 一旦信息需求量超過模型的單次處理容量 , 那么從數學角度來看模型就不可能達到 100% 的準確率 。
(來源:https://arxiv.org/pdf/2509.21199)
更有趣的是 , 通過這一理論該團隊還預測出一個名為“準確率懸崖”的現象:即前文提到的當任務復雜度超越模型的處理上限時模型性能并不會平滑地下降 , 相反的它會像墜落懸崖一樣發生急劇的斷崖式崩潰 , 這完美地解釋了他們所觀察到的現象:即為何模型在處理某個臨界點之下的任務時游刃有余 , 而一旦超過這個節點性能就迅速變得不可接受 。
打下理論基礎之后 , 他們又將理論與實際問題進行結合 , 并形式化地定義了多跳問答任務的結構 , 借此識別出導致其信息需求量爆炸式增長的兩個原因 。
第一個原因是逐步容量溢出 。 研究團隊發現 , 隨著推理“跳數”的增加 , 模型需要記憶和處理的中間信息會呈現出超線性增長的規律 , 以至于非常容易在某一個步驟上壓垮模型的單次信息容量 。
第二個原因是跨步錯誤累積 。 由于推理鏈的依賴性 , 即使每一步只有很微小的偏差 , 這些錯誤也會在鏈條中逐級放大 , 最終導致整個推理過程出現崩潰 。
這兩個原因共同構成了一個兩難的組合困境 , 使得單次生成范式在根本上難以勝任復雜的多跳任務 。 找到問題的根源之后 , 尋找解決方案的方向也變得清晰起來:既然單次生成的瓶頸在理論上無法避免 , 那么就得超越它 。 為此 , 研究團隊設計了 InfoQA , 這是一個多輪調用(multi-call)的推理框架 , 他們將其作為一個模擬多智能體系統來證明其推測 。
(來源:https://arxiv.org/pdf/2509.21199)
據介紹 , InfoQA 的設計哲學源于該團隊的理論分析 , 他們通過以下三個核心機制來解決上述組合困境:
第一個機制是感知容量的任務分解 , 它能將一個復雜的多跳問題分解成一系列模型單次處理能力之內的單跳子問題 , 從而確保每一步都不會掉下“準確率懸崖” 。
第二個機制依賴于明確的工作流 , 它將上一步的答案顯式地注入到下一步的問題中 , 從而形成一個清晰和可控的推理鏈條 , 進而能夠保證推理路徑的魯棒性 。
第三個機制是迭代式問題壓縮 , 在每一步之后它都會主動“剪掉”不再需要的推理痕跡和上下文噪音 , 只將最核心的信息保留下來 , 以便達成負荷最小的推理過程 , 從而避免信息負載的持續膨脹 。
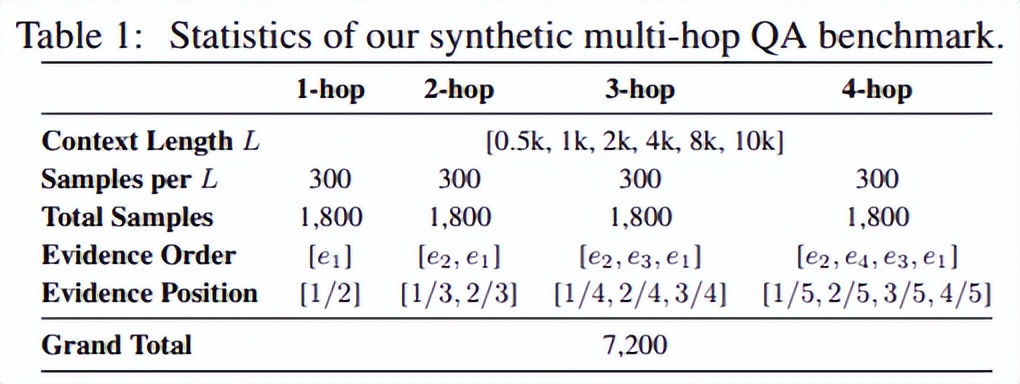
鑒于已有的基準測試無法精確地控制任務的信息復雜度 , 因此他們構建了一個充滿噪音和干擾項的合成數據集 。 這個合成數據集為他們帶來了一個高度可控的實驗環境中 , 基于此他們證明 InfoQA 框架在各種復雜度和各種長度的上下文之下 , 性能都能穩定、顯著地超越所有單遍推理的基線模型 。
而在后續 , 研究團隊計劃進行“活字印刷”的新嘗試 。 具體來說 , 其將通過多目標優化的方法在一個骨干模型中訓練多種可被獨立調用的“原子能力” , 以期能在單一巨型模型和復雜多智能體系統之間找到一個更高效和更經濟的平衡點 。
研究團隊表示 , 他們希望最終能夠打造一個“單一部署、多能協作”的高效模型 , 預計這一模型不僅功能多樣 , 又能根據任務動態調用能力 , 從而能夠顯著降低部署成本和推理成本 , 這將尤其適合在手機等資源有限的設備上運行 。
參考資料:
https://arxiv.org/pdf/2509.21199
運營/排版:何晨龍
推薦閱讀















- 內爆致5人遇難:泰坦號殘骸發現完好閃迪存儲卡!12張照片9段視頻
- 李飛飛全新「世界模型」問世,單張H100實時生成3D永恒世界
- 南洋理工揭露AI「運行安全」全線崩潰,簡單偽裝即可騙過所有模型
- 通過幾何代理任務增強視覺-語言模型中的空間感知和推理能力
- 單張顯卡實時生成3D世界,李飛飛World Labs推出全新世界模型RTFM
- 英偉達DGX Spark:小巧超算處理大模型的新選擇
- 軟件行業,迎來大模型最強暴擊!
- 科學家構建AI“賽博學術小鎮”,讓化工科研實現自主演化
- Anthropic發布入門級Claude Haiku 4.5混合推理模型
- 天貓雙11首日大模型調用150億次!對話幕后團隊:這三大功能最熱