
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
智東西
編譯 | 程茜
編輯 | 云鵬
智東西10月20日消息 , 百度10月16日開源的多語言文檔解析模型PaddleOCR-VL , 連續三天霸榜Hugging Face趨勢榜第一 。
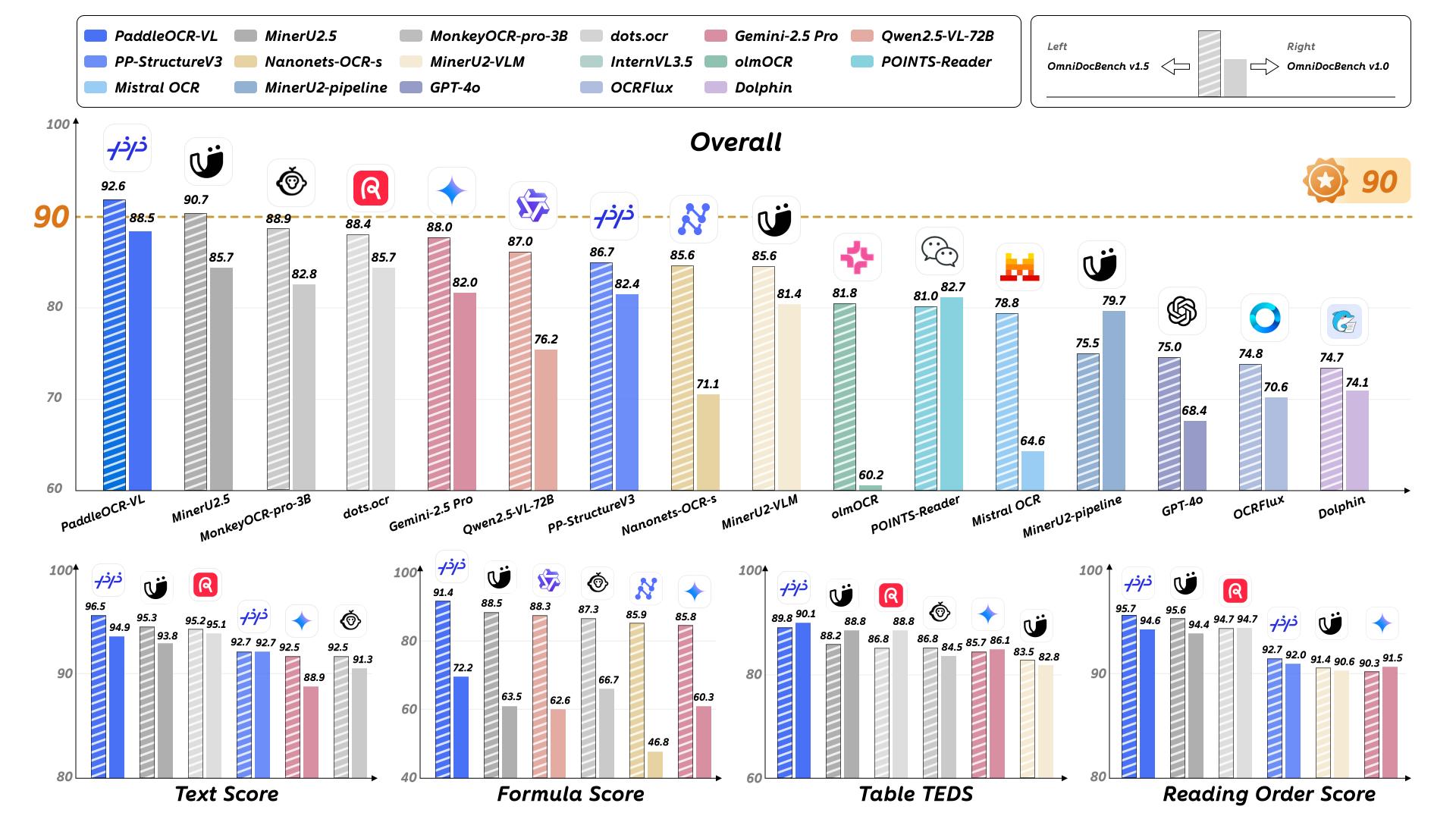
PaddleOCR-VL能識別109種語言的文本、表格、公式和圖表等復雜元素 , 包括全球主要語言以及俄語、阿拉伯語和印地語等多種語言 。 在最新的用于評估現實場景中多樣化文檔解析性能的基準測試工具OmniDocBench榜單中 , PaddleOCR-VL以92.6綜合得分拿下全球第一 , 并且在OmniDocBench v1.5、OmniDocBench v1.0均是第一 。
PaddleOCR-VL在OmniDocBench v1.5上實現了整體、文本、公式、表格和閱讀順序的SOTA性能 , 在所有關鍵指標上均超越現有流水線工具、通用VLM和其他專用文檔解析模型 。
論文中提到 , PaddleOCR-VL在文檔解析任務中實現了最佳性能 , 其擅長識別復雜的文檔元素 , 例如文本、表格、公式和圖表 , 適用于手寫文本和歷史文檔等各種具有挑戰性的內容類型 。
百度給出的官方手寫文本示例中 , 圖片中文字寫作相對規范 , 有較少不清晰文字 , 模型識別結果中錯誤較少 。
手寫文本(左)、識別結果(右)
隨后智東西上傳了一張蘇軾手札 , 相對上面的圖片僅憑肉眼很難辨認清楚且有較多繁體字 , 模型的識別結果中錯誤較多 。
手寫文本(上)、識別結果(左下)、古詩文網原文(右下)
該方案的核心組件PaddleOCR-VL 0.9B基于NaViT風格的視覺編碼器和ERNIE-4.5-0.3B語言模型構建 , 具有快速推理和低資源消耗的特點 , 適合實際部署 。
在訓練數據方面 , 研究人員采用了開源數據集、合成數據集、網絡可訪問數據集和內部數據集 。 同時 , 其開發了高質量訓練數據構建流程 , 通過公共數據采集和數據合成收集了超過3000萬個訓練樣本 , 以基于專家模型的識別結果指導通用大型模型進行自動標注 。
技術報告:file:///Users/wangquan/Desktop/2510.14528v2.pdf
Hugging Face開源地址:https://huggingface.co/PaddlePaddle/PaddleOCR-VL
體驗地址:https://aistudio.baidu.com/application/detail/98365
一、復雜公式、多語言識別準確 , 不清晰、反光文字出現少量錯誤智東西體驗了PaddleOCR-VL文檔解析能力和元素級識別能力 , 模型在中英文、韓語以及復雜公式、圖表等方面識別準確率都很高 , 在圖片有反光、不清晰時出現極個別錯誤 。
智東西上傳了PaddleOCR-VL論文的首頁 , 識別結果中 , 模型自動識別出了鏈接、郵箱地址 , 并準確將圖表進行了切分 。
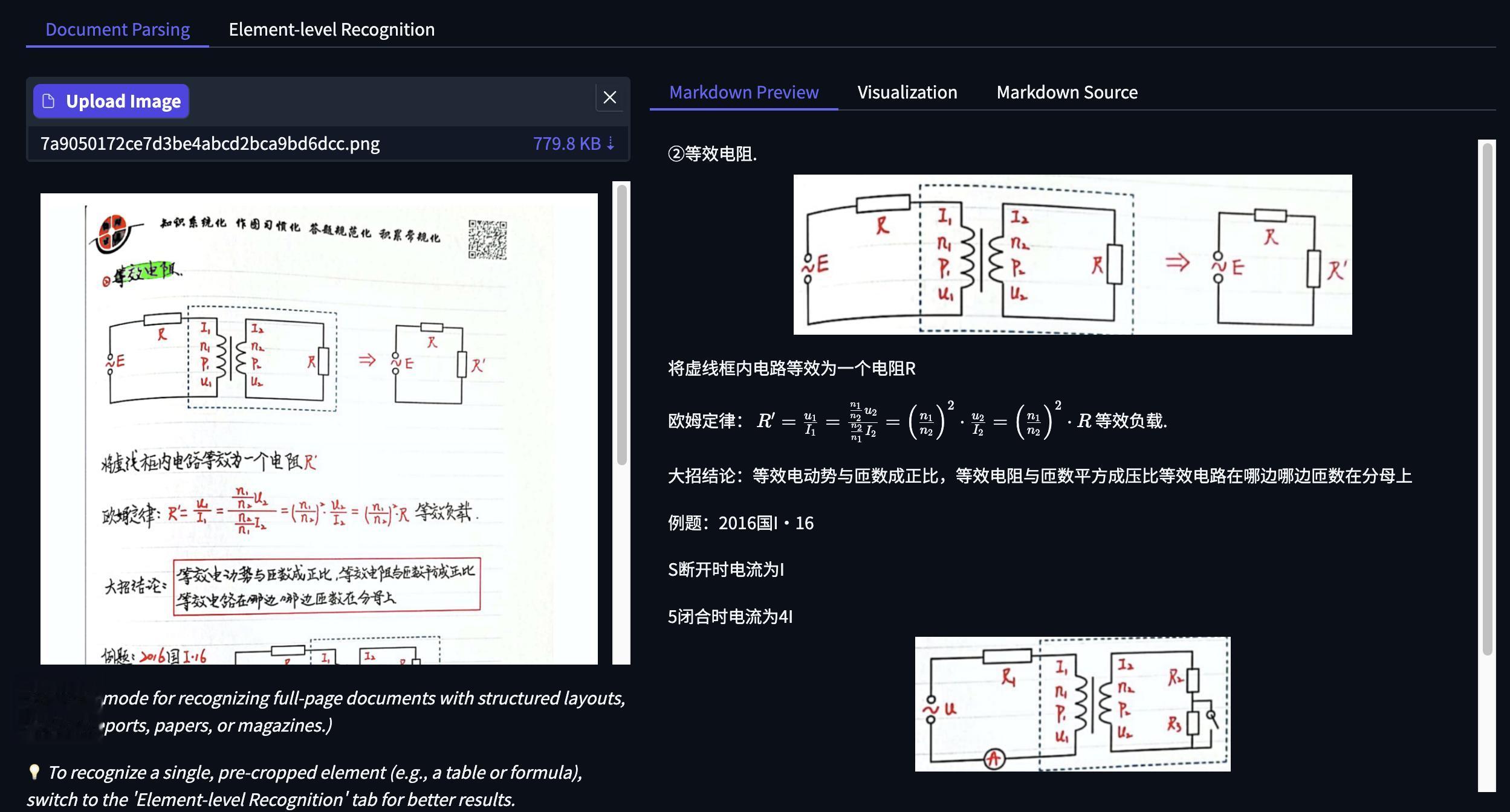
下面是一道物理題目 , 模型自動識別出了頁眉部分的標語 , 小標題、圖表、復雜公式識別準確 。
元素級識別能力中 , 先來看圖表識別 , 圖表的每一部分內容及數字表達都清晰準確 。
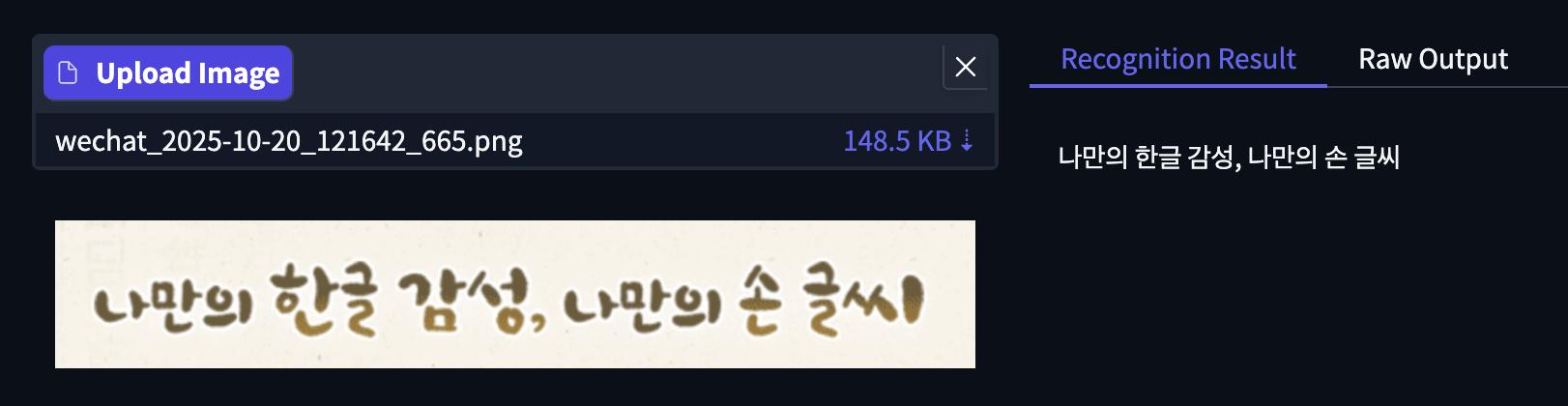
文字識別中 , 智東西上傳了中文、韓語 。 下面是一張手寫體的韓語圖片 , 模型識別結果準確 。
【僅0.9B!百度新開源模型一夜登頂,識別109種語言,綜合分全球第一】公式識別方面 , 智東西上傳了一張包含公式的圖片 , 模型將復雜公式的細節都進行了準確識別 。
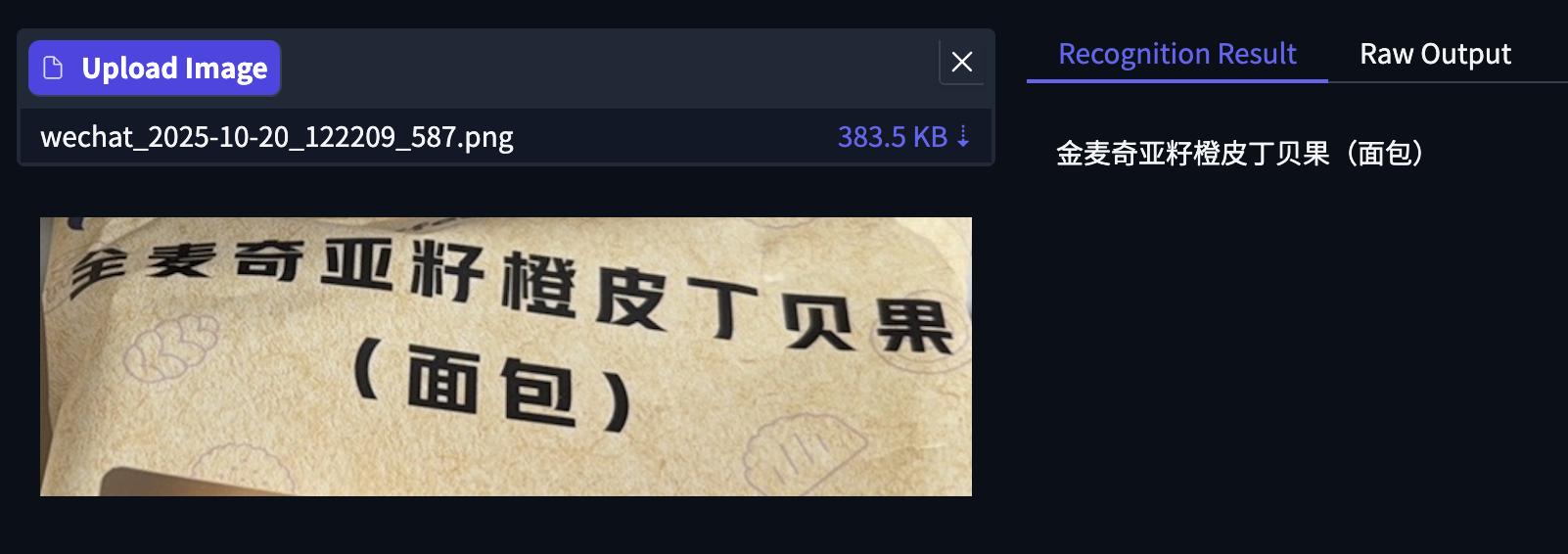
其次為畫面不清晰的中文識別 , 可以看到下面包裝袋左上角有褶皺 , 模型錯誤將第一個“全”字識別為“金” , 其余文字均準確 。
下面圖片的拍攝角度是側面 , 因此右側文字有反光 , 模型錯誤將“文”識別為“大” , 但后面的“物”即使有反光+變體 , 模型的識別結果也沒有出錯 , 同時下方的英文識別也完全正確 。
二、文檔識別先前技術有弊端 , 百度提出基于視覺語言模型的文檔解析方案文檔作為核心信息載體 , 其復雜性和數量呈指數級增長 , 使得文檔解析成為一項不可或缺的關鍵技術 。 文檔解析的主要目標是深入理解文檔布局的結構和語義 , 包括識別不同的文本塊和列 , 區分公式、表格、圖表和圖像 , 確定正確的閱讀順序 , 以及檢測關鍵元素等 。
但現代文檔較為復雜 , 其包含密集文本、復雜表格或圖表、數學表達式、多種語言和手寫文本 。 因此這一領域目前有兩種技術方法 , 一是采用基于專門的模塊化專家模型的流水線方法 , 但這種方法在處理高度復雜文檔時 , 會受到集成復雜性、累積誤差傳播和固有限制的阻礙;二是利用多模態模型的端到端方法簡化工作流程并實現聯合優化 。 然而這些方法通常難以保持正確的文本順序 , 在面對冗長或復雜的布局時甚至會產生幻覺 , 同時還會為長序列輸出帶來大量的計算開銷 。
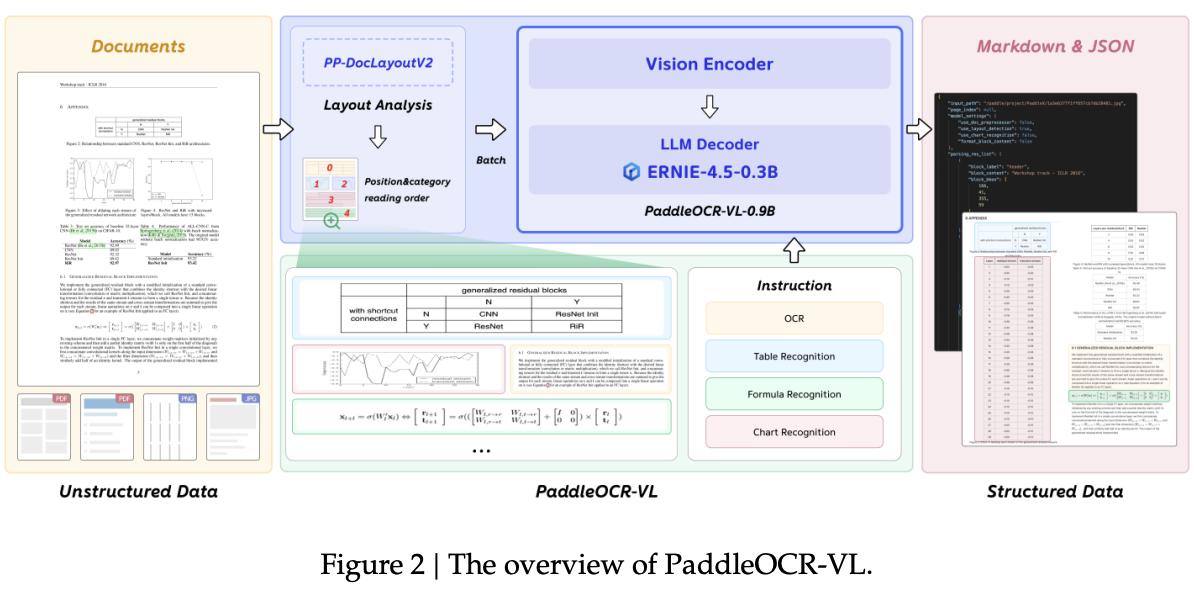
基于此 , 百度研究人員推出基于視覺語言模型的高性能、資源高效的文檔解析解決方案PaddleOCR-VL , 該方案將布局分析模型與視覺語言模型PaddleOCR-VL-0.9B相結合 。
首先 , PaddleOCR-VL會進行布局檢測和閱讀順序預測 , 獲取文本塊、表格、公式、圖表等元素的位置坐標和閱讀順序 。 論文中提到 , 與依賴基礎和序列輸出的多模態方法相比 , PaddleOCR-VL的方法推理速度更快、訓練成本更低 , 并且更易于擴展新的布局類別 。
隨后 , 這一方案會根據元素位置對其進行分割 , 并輸入PaddleOCR-VL-0.9B進行識別 。 PaddleOCR-VL-0.9B專為資源高效的推理而設計 , 擅長文檔解析中的元素識別 。 其通過將NaViT風格的動態高分辨率視覺編碼器與輕量級ERNIE-4.5-0.3B語言模型相結合 , 提升了模型的識別能力和解碼效率 。
PaddleOCR-VL概覽
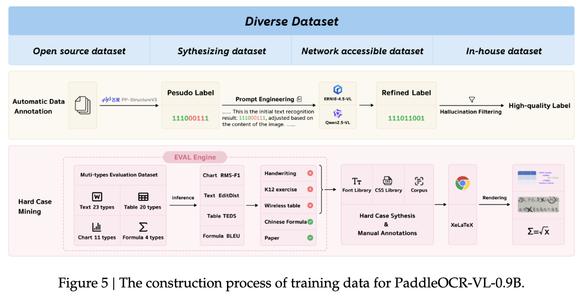
為了訓練強大的多模態模型 , 研究人員開發了高質量訓練數據構建流程 , 其通過公共數據采集和數據合成收集了超過3000萬個訓練樣本 , 以基于專家模型的識別結果指導通用大型模型進行自動標注 。 同時進行數據清理 , 以去除低質量或不一致的標注 。 此外 , 研究人員還設計了評估引擎 , 通過評估集合將每個元素劃分為更詳細的類別 , 基于此分析當前模型在不同場景下的訓練性能 。
最后 , 其還會結合少量極端情況進行人工標注 , 最終完成訓練數據的構建 。
三、文檔解析、元素識別均采用兩階段訓練方案 , 訓練數據來源有四類PaddleOCR-VL將文檔解析任務分解為兩個階段:第一階段PP-DocLayoutV2負責布局分析 , 定位語義區域并預測其閱讀順序;第二階段PaddleOCR-VL-0.9B利用這些布局預測對各種內容進行細粒度識別 。 最后 , 輕量級的后處理模塊將兩個階段的輸出聚合在一起 , 并將最終文檔格式化為結構化的Markdown和JSON格式 。
在用于版式分析的PP-DocLayoutV2的訓練方案方面 , 研究人員采用PP-DocLayoutV2模型來執行布局元素定位、分類和閱讀順序預測 。 PP-DocLayoutV2通過添加一個指針網絡(Pointer Network)來擴展RT-DETR(基于Transformer的實時目標檢測模型) , 該網絡負責預測檢測到的元素的閱讀順序 。
其訓練過程采用兩階段策略:首先訓練核心RT-DETR模型進行布局檢測和分類 , 然后凍結其參數 , 并單獨訓練指針網絡進行閱讀順序預測 。
第一階段研究人員遵循RT-DETR的訓練策略 , 使用PP-DocLayout_Plus-L預訓練權重初始化模型 , 并在其自建的20000多個高質量樣本數據集上訓練100個epoch;第二階段 , 模型輸出一個表示任意兩個元素之間成對排序關系的矩陣 , 并根據真實標簽計算廣義交叉熵損失 , 其使用恒定學習率2e-4和AdamW優化器訓練200個epoch 。
在用于元素識別的PaddleOCR-VL-0.9B訓練方案方面 , PaddleOCR-VL-0.9B包含三個模塊:視覺編碼器、投影儀和語言模型 。 其采用預訓練模型的后自適應策略 , 視覺模型使用Keye-VL的權重初始化 , 語言模型使用ERNIE-4.5-0.3B的權重初始化 。
其訓練方法分為兩個階段 , 第一階段初始階段專注于預訓練對齊 , 模型學習將圖像中的視覺信息與相應的文本表示關聯起來 , 這一關鍵步驟基于包含2900萬個高質量圖文對的海量數據集進行;第二階段預訓練完成后 , 模型將進行指令微調 , 使其通用的多模態理解適應特定的下游元素識別任務 , 此階段使用270萬個樣本數據集 。
第1階段和第2階段的訓練設置
研究人員采用的數據主要有四個來源:開源數據集、合成數據集、網絡可訪問數據集和內部數據集 。
獲取原始數據后 , 研究人員利用自動化數據標注流程進行大規模標注 。 首先其使用專家模型PP-StructureV3對數據進行初步處理 , 生成可能存在誤差的偽標簽;隨后通過提示工程創建包含原始圖像及其相關偽標簽的提示 , 并將其提交給更先進的多模態大型語言模型ERNIE-4.5-VL和Qwen2.5VL 。
PaddleOCR-VL-0.9B訓練數據的構建過程
這些模型通過分析圖像內容來細化和增強初始結果 , 從而生成更優質的標簽 。 最后 , 為了確保標簽的質量 , 系統會執行幻覺過濾步驟 , 消除大型模型生成的潛在錯誤內容 。
四、PaddleOCR-VL在文檔解析能力測試集中 , 達到SOTA為了評估PaddleOCR-VL的有效性 , 研究人員對其頁面級文檔解析和元素級識別進行了性能比較 。
首先是頁面級文檔解析 , 研究人員使用OmniDocBench v1.5、OmniDocBench v1.0、olmOCR-Bench三個基準對PaddleOCR-VL的端到端文檔解析能力進行了評估 。
OmniDocBench v1.5是全面評估文檔解析能力的測試集 , PaddleOCR-VL在OmniDocBench v1.5上實現了整體、文本、公式、表格和閱讀順序的SOTA性能 , 在所有關鍵指標上均超越現有流水線工具、通用VLM和其他專用文檔解析模型 。
具體來看 , PaddleOCR-VL模型取得了92.56的綜合最高分 , 超過了排名第二的MinerU2.5-1.2B(90.67) 。 PaddleOCR-VL在子任務中取得了新的SOTA成績 , 包括最低的Text-Edit距離、最高的Formula-CDM分數以及Table-TEDS、Table-TEDS-S 。 論文提到 , 這表明該模型在文本識別、公式識別和復雜表格結構分析方面擁有較高準確率 。
OmniDocBench v1.5文檔解析綜合評估
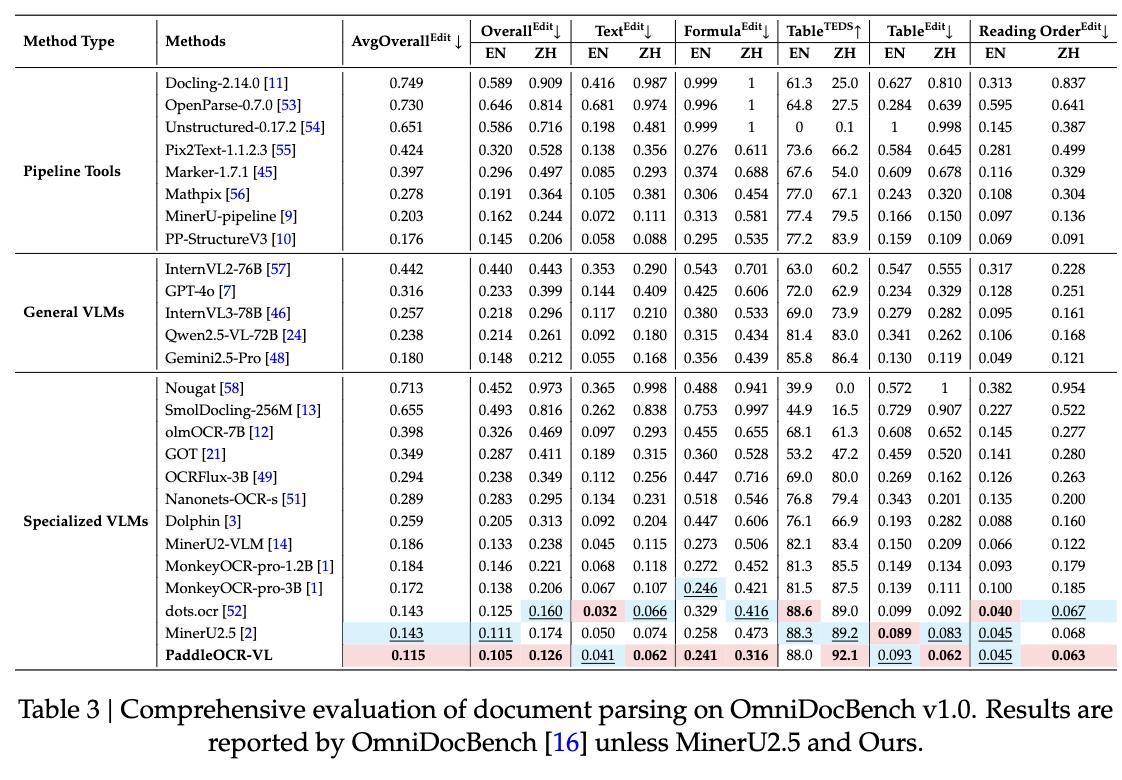
OmniDocBench v1.0專門用于評估現實世界的文檔解析能力 。 PaddleOCR-VL在OmniDocBench v1.0上實現了幾乎所有指標的總體、文本、公式、表格和閱讀順序的SOTA性能 。
PaddleOCR-VL平均整體編輯距離為0.115 。 模型在中文和英文文本編輯距離方面分別取得了SOTA最佳成績(0.062)和相當的SOTA最佳成績(0.041) 。 不過在英文表格TEDS中 , 該模型僅為88分 , 論文提到其原因是OmniDocBench v1.0中拼寫錯誤相關的標注錯誤 。
OmniDocBench v1.5文檔解析綜合評估
在閱讀順序編輯距離方面 , 該模型在中文中取得最佳成績0.063 , 在英文中取得了相當的SOTA最佳成績0.045 。
olmOCR-Bench主要通過簡單、清晰且機器可驗證的單元測試來評估工具和模型 。 PaddleOCR-VL在olmOCR-Bench評測中取得了80.0±1.0的最高總分 , 在ArXiv(85.7)、頁眉和頁腳(97.0)方面領先 , 并在多列文本(79.9)和長小文本(85.7)方面排名第二 。
olmOCR-Bench文檔解析綜合評估
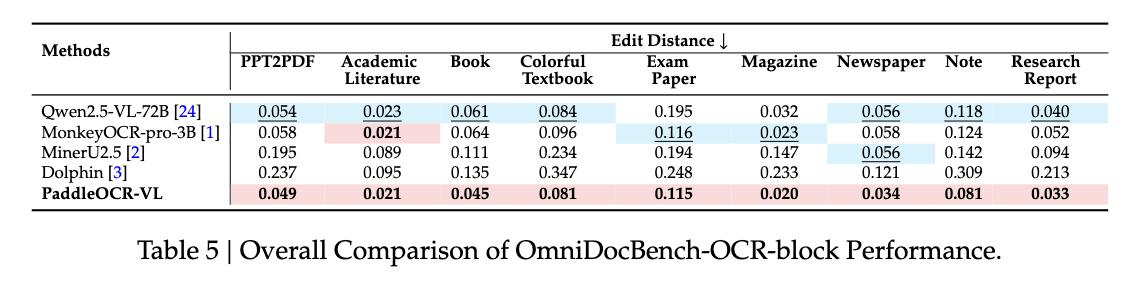
其次是元素級評估 。 在文本識別中 , PaddleOCR-VL幾乎在OmniDocBench-OCR-block評估的所有類別中都實現了最低的錯誤率;百度內部自建的文本評估數據集 , 模型在多語言指標、文本類型指標中都展現出較高的準確率 。
OmniDocBench-OCR-block性能的總體比較
Ocean-OCR-Handwritten是一個行和段落級別的手寫評估數據集 , 模型在英文中實現了0.118的最佳編輯距離 , 并在F1得分、精確度、召回率、BLEU和METEOR方面表現出色 , 模型在中文中編輯距離為0.034 。
Ocean-OCR-Bench上英文和中文OCR手寫識別性能比較
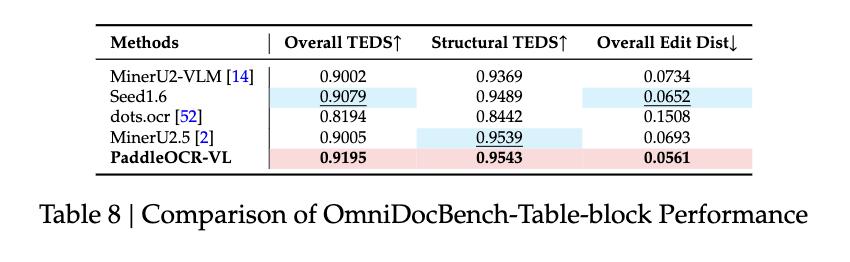
表格識別方面 , PaddleOCR-VL在OmniDocBench-Table-block基準測試中領先 , 超越Seed1.6等模型;在百度自建的表格評估數據集上 , 模型在總體TEDS、結構TEDS、總體編輯距離和結構編輯距離方面均取得了最高分 。 公式識別方面 , 模型在OmniDocBench-Formula-block獲得最佳的CDM得分0.9453;圖表識別 , 在百度內部數據集上 , PaddleOCR-VL不僅優于專業的OCR VLM , 甚至超越了一些72B級別的多模態語言模型 。
OmniDocBench-Table-block性能比較
推理性能方面 , 研究人員在OmniDocBench v1.0數據集上測量了端到端推理速度和GPU使用情況 , 并在單個NVIDIA A100 GPU上以512個批次處理PDF文件 。 PaddleOCR-VL在處理速度和內存效率方面均展現出明顯且一致的優勢 。 與領先的基準MinerU2.5相比 , 部署vLLM后端后 , 其頁面吞吐量提高了15.8% , token吞吐量提高了14.2% 。 此外 , PaddleOCR-VL GPU內存占用比dots.ocr減少了約40% 。
端到端推理性能比較
結語:或加速復雜文檔信息高效提取研究人員基于PaddleOCR-VL增強了模型的識別能力和解碼效率 , 并在保證識別高精度的同時減少計算需求 , 使其非常適合高效實用的文檔處理應用程序 。
PaddleOCR-VL廣泛的多語言支持和強大的性能有望推動多模態文檔處理技術的應用和發展 , 或將顯著提升RAG系統的性能和穩定性 , 使研究人員從復雜文檔中提取信息更加高效 , 從而為未來的AI應用提供更可靠的數據支持 。
推薦閱讀















- 從電競神器到性能旗艦的iQOO 15,重構不僅是性能,還有品牌定位
- 手機周邊份額再次出爐:小米第二,華為僅排第四!
- 中國最強光刻機廠商:離浸潤式DUV,僅一步之遙了
- 百度健康發布AI管家:能聊病癥、連名醫,支持真人醫生二次核驗
- 百度AI榜,一場遲到的本地生活實驗
- 最高僅需32999,蘋果三大新品齊發
- 京東雙11手機暢銷榜更新:小米17僅排第五,第一名意料之中
- 安卓千元機性價比榜單:iQOO Z10Turbo僅排第七,第一名意料之中
- 僅蘋果實現增長!2025年Q3中國大陸智能手機市場份額出爐
- 百度升級文心助手AIGC能力:支持8種模態 一鍵調用多工具