
文章圖片

文章圖片
文章圖片
文章圖片
隨著多模態大模型的不斷演進 , 指令引導的圖像編輯(Instruction-guided Image Editing)技術取得了顯著進展 。 然而 , 現有模型在遵循復雜、精細的文本指令方面仍面臨巨大挑戰 , 往往需要用戶進行多次嘗試和手動篩選 , 難以實現穩定、高質量的「一步到位」式編輯 。
強化學習(RL)為模型實現自我演進、提升指令遵循能力提供了一條極具潛力的路徑 。 但其在圖像編輯領域的應用 , 長期以來受限于一個核心瓶頸:缺乏一個能夠精確評估編輯質量并提供高保真度反饋的獎勵模型(Reward Model) 。 沒有可靠的「獎勵信號」 , 模型便無法有效判斷自身生成結果的優劣 , 從而難以實現高效的自我優化 。
為攻克這一難題 , 北京智源人工智能研究院 VectorSpace Lab 團隊近日發布了全新的高保真獎勵模型系列——EditScore 。 該工作直面上述挑戰 , 旨在為指令引導的圖像編輯任務提供精確、可靠的獎勵信號 , 從而為強化學習在 AIGC 領域的深入應用鋪平道路 , 真正解鎖其強大潛力 。
EditScore 是智源在成功推出統一圖像生成模型 OmniGen 系列之后 , 對更通用、更可控的生成式 AI 的又一重要探索 。 為了促進未來在獎勵建模、策略優化和??智能驅動的模型改進等領域的研究 , EditScore 模型系列和 EditReward-Bench 數據集現已全?開源 。 同時 , 經過強化學習微調的 OmniGen2-EditScore7B 模型也已同步開放 。
團隊表示 , 后續將陸續發布應?于 OmniGen2 的強化學習訓練代碼 , 以及針對 OmniGen2、Flux-dev-Kontext 和 Qwen-Image-Edit 的 Best-of-N 推理腳本 , 歡迎社區持續關注 。
論?鏈接: https://arxiv.org/abs/2509.23909 EditScore GitHub: https://github.com/VectorSpaceLab/EditScore EditScore 模型權重:https://huggingface.co/collections/EditScore/editscore-68d8e27ee676981221db3cfe EditReward-Bench 評測基準:https://huggingface.co/datasets/EditScore/EditReward-Bench RL 微調后的編輯模型 (OmniGen2-EditScore7B): https://huggingface.co/OmniGen2/OmniGen2-EditScore7B
從評估到賦能:EditScore 的系統化解決方案
為了克服圖像編輯領域缺乏高質量獎勵信號的障礙 , EditScore 團隊提出了一套系統的兩步解決方案 。
第?步:建?嚴謹的評估標準
?欲善其事 , 必先利其器 。 為了能夠直接、可靠地評估圖像編輯獎勵模型的質量 , 團隊?先構建并開源了 EditReward-Bench , 這是業界?個專?為評估圖像編輯獎勵模型?設計的公開基準 , 涵蓋了 13 個不同的?任務和 11 個當前最先進的編輯模型(包括閉源模型) , 并包含了專家級的??標注 , 為衡量獎勵信號的質量建?了??標準 。
第?步:開發強?的多功能?具
在 EditReward-Bench 的指引下 , 團隊精?策劃數據并進?訓練 , 最終成功開發出 EditScore 系列模型(分為 7B、32B、72B 三個尺?) 。 這?系列模型是專為指令圖像編輯任務設計的?保真獎勵模型 , 旨在提供?通?視覺語?模型(VLM)更精確的反饋信號 。
【智源開源EditScore:為圖像編輯解鎖在線強化學習的無限可能】
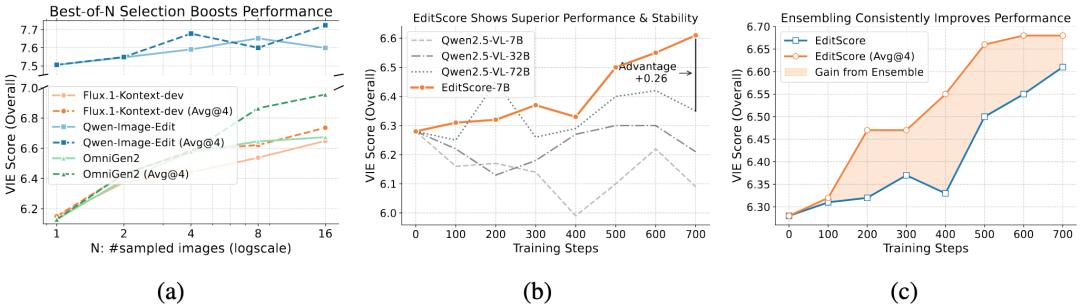
EditReward-Bench 上的基準測試結果 , 顯示了 EditScore 相較于其他模型的優越性
核心亮點:
頂尖性能:EditScore 在 EditReward-Bench 上的表現媲美甚?超越了頂級的閉源視覺語?模型 。 通過?種有效的?集成策略(self-ensembling) , 其最?規模的模型甚?在準確性上超過了 GPT-5 。 可靠的評估標準:團隊推出的 EditReward-Bench 是?個專??于評估圖像編輯領域獎勵模型的公開基準 。 簡潔易?:開發者只需??代碼 , 即可輕松地為圖像編輯結果獲得?個準確的質量評分 。 應??泛:EditScore 不僅可以作為?流的重排序器(reranker)來優化編輯輸出 , 還可以作為?保真獎勵信號 , 賦能穩定?效的 RL 微調 。
實踐出真知:EditScore 的兩?應?場景
EditScore 的實?價值在兩個關鍵應?中得到了充分驗證:
作為最先進的重排序器:通過「優中選優」(Best-of-N)的?式 , EditScore 能夠即時提升多種主流編輯模型的輸出質量 。 作為強化學習的?保真獎勵:當通?視覺語?模型在強化學習訓練中束??策時 , EditScore 能夠提供穩定且?質量的獎勵信號 , 成功解鎖了在線強化學習在圖像編輯領域的應? , 并帶來了顯著的性能提升 。團隊的實驗表明 , 將 EditScore-7B 應?于 OmniGen2 模型的 Flow-GRPO 微調后 , OmniGen2 在 GEdit 基準上的得分從 6.28 提升? 6.83 。
EditScore 作為圖像編輯的卓越獎勵信號 , 能夠精確區分編輯質量的好壞 。
將 EditScore 作為強化學習獎勵模型應用于 OmniGen2 的視覺結果對比
探索與發現:模型背后的深刻洞?
在研究過程中 , 團隊還獲得了?些有趣的洞?:
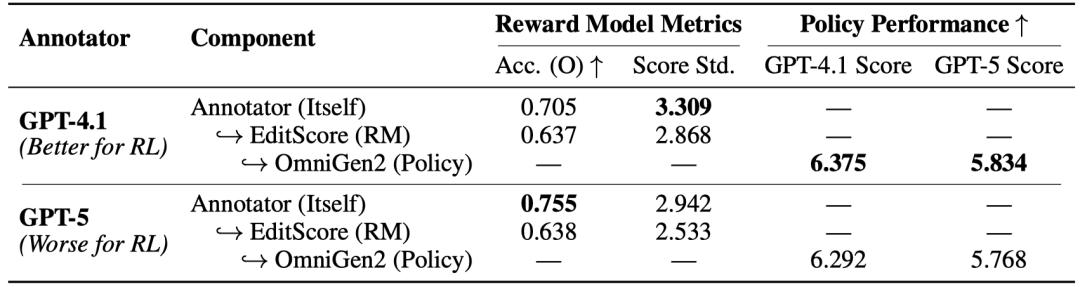
?分 ≠ 好教練? 獎勵模型的打分準確性并?決定強化學習訓練效果的唯?因素 。 ?個優秀的「AI 教練」不僅需要打分精準 , 其輸出分數的分布形態也?關重要 。 例如 , 獎勵模型打分的?差就可能會影響強化學習的效果 。
GPT-4.1 系列獎勵模型憑借更優的輸出分布特性 , 能夠更有效地指導強化學習優化
巧妙的「集成」策略:對于?成式獎勵模型 , 通過多次推理取均值的?集成擴展策略(Self-Ensemble Scaling) , 在提升性能??的效果可能優于單純地擴?模型參數量 。 這意味著 , ?個精?設計的 7B 模型 , 通過此策略可能在特定任務上達到甚?超越更?模型的性能 。
EditScore 持續的從參數拓展和測試時計算拓展(Self-ensemble)中獲得性能增益
結語
智能的成長離不開自我評估與持續進化 。 EditScore 讓模型具備了「自我審視」與「自我進化」的能力 , 為提升 AIGC 的可控性與可靠性打開了新的可能 。
智源研究團隊表示 , 將持續深入獎勵建模研究 , 「我們很高興將 EditScore、EditReward-Bench 、OmniGen2-EditScore7B 以及所有的研究發現開源 , 希望能為業界帶來新的啟發 , 期待與社區共同探索 , 讓 AIGC 模型變得更智能、更可控、更可靠 , 在更多領域釋放創造的力量」 。
推薦閱讀















- 估值翻6倍!這家爆火的開源初創正式晉升“獨角獸”
- 谷歌推出開源全棧NPU新架構,旨在實現大模型在終端的低功耗運行
- ICCV 2025 | 擴散模型生成手寫體文本行的首次實戰,效果驚艷還開源
- NeurIPS 2025 | CMU、清華、UTAustin開源ReinFlow
- 僅0.9B!百度新開源模型一夜登頂,識別109種語言,綜合分全球第一
- 400元遙操95%機械臂!上海交大推出開源項目U-Arm
- 美中AI競爭升級:美國巨額交易對戰中國開源策略
- 谷歌開源全棧平臺Coral NPU,能讓大模型在手表上全天候運行
- 僅4B!阿里千問最強視覺模型新開源,網友:我的16GB Mac有救了
- 開源鴻蒙再次發力:6.1與8.1版本均被確認,華為鴻蒙更穩定