
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片

文章圖片
編輯:桃子 好困
【新智元導讀】凌晨 , 老黃GTC主題演講華盛頓首秀 , 直接亮出下一代GPU核彈——Vera Rubin , 性能狂飆100倍 。 目前 , Blackwell已全面量產 , 2026年底兩大GPU王牌預計爆賺5000億美金 。
英偉達GTC大會 , 首次在華盛頓召開 。
在近兩小時演講中 , 老黃不僅再次上演了一波AI美隊 , 而且還給出了AI時代獨一份的洞察——
AI不是工具 , 而是會用工具的「工人」 。
當老黃首次掏出下一代「殺手锏」Vera Rubin超級芯片時 , 全場都震撼了 。
相較于九年前 , 他親手交付給OpenAI的首個超算DGX-1 , 性能足足提升了100倍 。 并且明年就能量產 。
當然 , 老黃的野心遠不止于硬件 。 接下來的一系列震撼合作 , 將英偉達的AI帝國展示在了所有人面前:
- AI原生6G:推出「AI on RAN」技術 , 將AI與6G網絡深度融合 , 讓基站成為邊緣的AI計算中心 。
- 超算基建:與美國能源部合作 , 建造7座全新的AI超算 。
- 自動駕駛:發布「開箱即用」的DRIVE Hyperion平臺 , 讓汽車「生而為Robotaxi」 。
- 量子計算:發布NVQLink技術 , 首次將AI超算與量子處理器無縫連接 , 加速量子計算的實用化進程 。
- 物理AI:通過Omniverse中的數字孿生技術 , 訓練「物理AI」 , 加速機器人在現實世界中的部署 , 目標直指美國「再工業化」 。
老黃預測 , 在2026年底前 , 僅憑「Blackwell+Rubin」就足以沖擊5000億美元的營收 。
而且 , 這一數字還未將中國市場計算在內 。
下一代Vera Rubin首秀
性能狂飆百倍
現場 , 老黃再次搬出了 , 未來三年英偉達GPU路線圖 , 從Blackwell , 到Rubin , 再到Feynman 。
他激動官宣 , 短短9個月后 , Blackwell芯片已在亞利桑那州全面量產 。
而真正站在全場C位的 , 還是下一代Vera Rubin的首次亮相 。
這是英偉達第三代NVLink 72機架級超級計算機 , 徹底實現了無線纜連接 。
目前 , Vera Rubin超級芯片已在實驗室完成測試 , 預計明年10月可以投產 。
這塊超級芯片計算能力達到100 Petaflops , 是DGX-1性能的100倍 。
換句話說 , 以前需要25個機架 , 現在一個Vera Rubin就能完成 。
如下 , 便是Rubin計算托盤 , 推理性能可達440PF 。
其底部配備了8個Rubin CPX GPU、BlueField-4數據處理器 , 還有兩顆Vera CPU , 以及4個Rubin封裝——總共8個GPU , 全部實現了無纜、全液冷 。
同時 , 英偉達還引入了一種全新「上下文處理器」(Context Processor) , 支持超100萬token上下文 。
如今 , AI模型要處理、記憶的上下文越來越多 , 它可以在回答問題前 , 學習和閱讀成千上萬份PDF、論文、視頻 。
此外 , BlueField-4革命性處理器 , 可以加速AI模型加載時間 。
還有NVLink交換機 , 可以讓所有GPU同步傳輸數據;以太網交換機Spectrum-X可以確保處理器同時通信而不擁堵 。
再加上Quantum交換機 , 三者結合 , 系統全部兼容InfiniBand、Quantum 和 Spectrum Ethernet 。
所有這些組合起來 , 一個完整的機架塞滿150萬個零件 , 重量足足有兩噸 。
它的主干網絡 , 一秒內就能傳輸相當于整個互聯網的流量 , 刷新全球最快的token生成速度 。
老黃表示 , 「一個1GW規模的數據中心 , 大概需要8000-9000臺這樣的機架 。 這就是未來的AI工廠」!
老黃拋出5000億預言
AI美隊再上線
GPU是AI革命的核心引擎 , 而AI的世界 , 遠不止ChatGPT 。
主題演講上 , 老黃親自科普了AI的定義 。
一上來 , 他就給大眾認知來了一個降維打擊 , AI并不等于聊天機器人 。
他將其比作一個數據密集型的「編程」 , 在CPU時代的舊世界 , 人們手工編碼 , 軟件在CPU上運行 , Windows主導了一切 。
而在當下 , 機器學習訓練 , 模型直接跑在GPU之上 。
能源-GPU-超算-模型-應用 , 全棧的能力構成了完整的AI 。
接下來 , 老黃還提出了一個對于AI的深刻洞察——
過去的軟件產業 , 本質上是在「造工具」 , Excel、Word、瀏覽器皆是工具 。
在IT領域 , 這些工具可能就是「數據庫」之類的 , 其市場規模大約在一萬億美元左右 。
但AI不是工具 , 是「工人」 。 事實上 , AI是「會用工具的工人」 。
這就是根本性差異 。
到目前為止 , 人類發明的一切東西 , 本質上都是工具 , 都是給自己用的 。
但這回是歷史上頭一次 , 技術自己會「干活」了 。
老黃舉例道 , 英偉達每一位工程師都在用Cursor , 生產力得以大幅提升 。 而Cursor使用的工具是VS Code 。
AI本身也正在成為一個「全新的產業」 , 當人們把各種形式的信息編程token之后 , 就需要一個「AI工廠」 。
10x的性能 , 1/10的成本
「AI工廠」不同于過去的數據中心 , 是因為它基本上只做一件事——運行AI 。
一來 , 生產盡可能有價值、更智能的token;其次 , 要用極高的速度將其生產出來 。
過去兩年 , 業界讓AI學會了變得更加聰明的方法 , 預訓練是第一階段 。
下一步就是后訓練 , 再之后就是測試時 , 讓AI不斷思考(Long Thinking) 。
這也是老黃一直以來 , 反復強調的三大Scaling Law 。
模型越聰明 , 使用的人越多;用的人越多 , 需要的算力越多 。
與此同時 , 摩爾定律邊際趨緩 , 僅靠狂堆晶體管 , 無法解決兩條指數曲線帶來的「饑餓感」 。
那么 , 摩爾定律已死 , 又該如何將成本大幅壓下來?
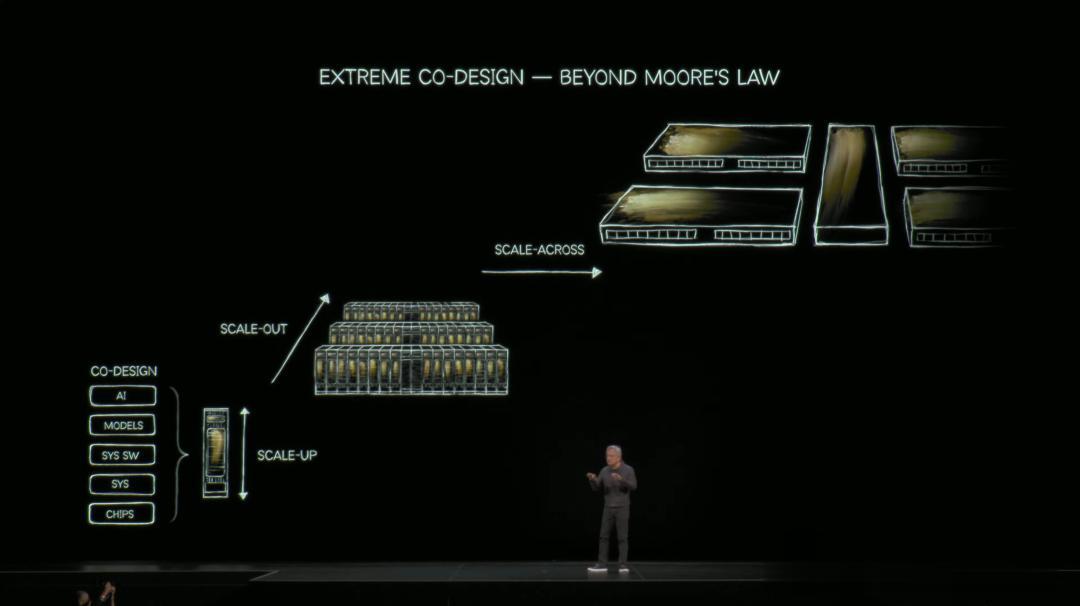
老黃給出的答案是:極致協同設計(Extreme Co-design) 。
英偉達是當今世界上 , 唯一一家真正從一張白紙開始 , 同時思考芯片、系統、軟件、模型、應用的公司 。
他們的協同設計 , 將AI算力實現了從Scale up到Scale out , 再到Scale across的擴展 。
Grace Blackwell NVL72 , 一臺思考機器 , 就是英偉達「協同設計」的典型代表 。
為了更直觀說明 , 老黃再次上演「芯片版美隊」 , 手里拿著巨型芯片 , 由72塊GPU無縫互聯 。
他還調侃道 , 「下次要演雷神 , 一伸手 , 芯片就到手里了」
為了駕馭萬億級參數模型 , 它采用了MoE架構 。 傳統系統受限于GPU間互聯帶寬 , 一塊GPU要扛32位專家的計算 。
在NVLink 72架構下 , 每塊GPU可以放4位專家 。
SemiAnalysis最新基準測試顯示 , Grace Blackwell每塊GPU的性能 , 是H200的十倍 。
只多了一倍晶體管 , 速度卻快了十倍 , 秘訣就在于——極致協同設計 。
GB200 , 這臺世界上最昂貴的計算機 , 卻能生成成本最低的token 。
它的極致性能 , 均攤了每一次計算的總擁有成本(TCO) , 也就是說——
10倍性能 , 十分之一成本 。
而此刻 , 這一突破正逢其時 。
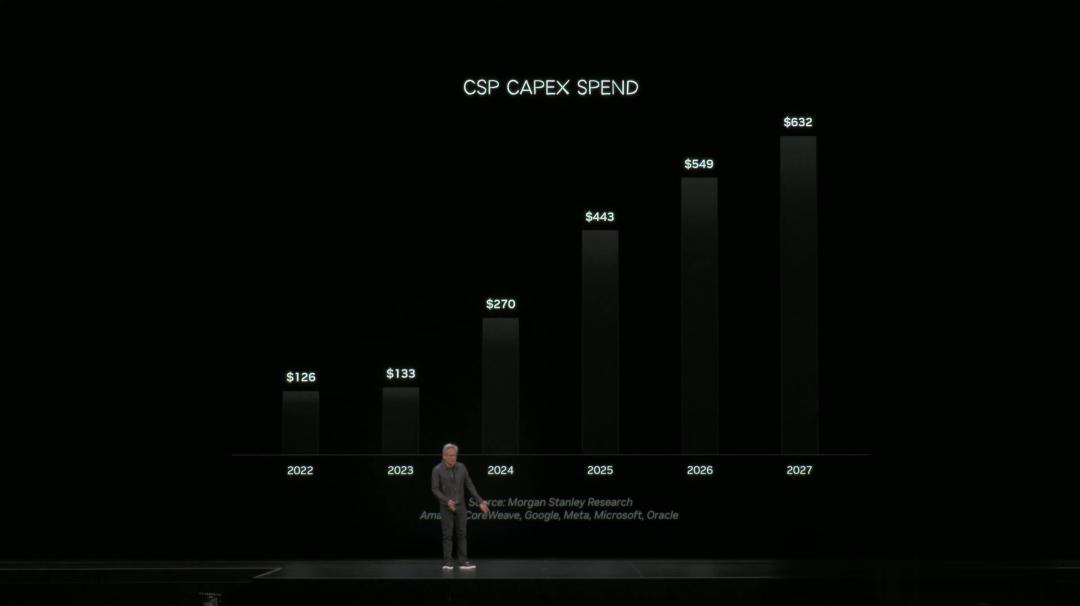
老黃展示了 , 全球六大云巨頭的資本支出曲線(CapEx) , 正以史無前例的速度飆升 。
它還聯手能源部 , 官宣未來要建七大全新AI超算 。
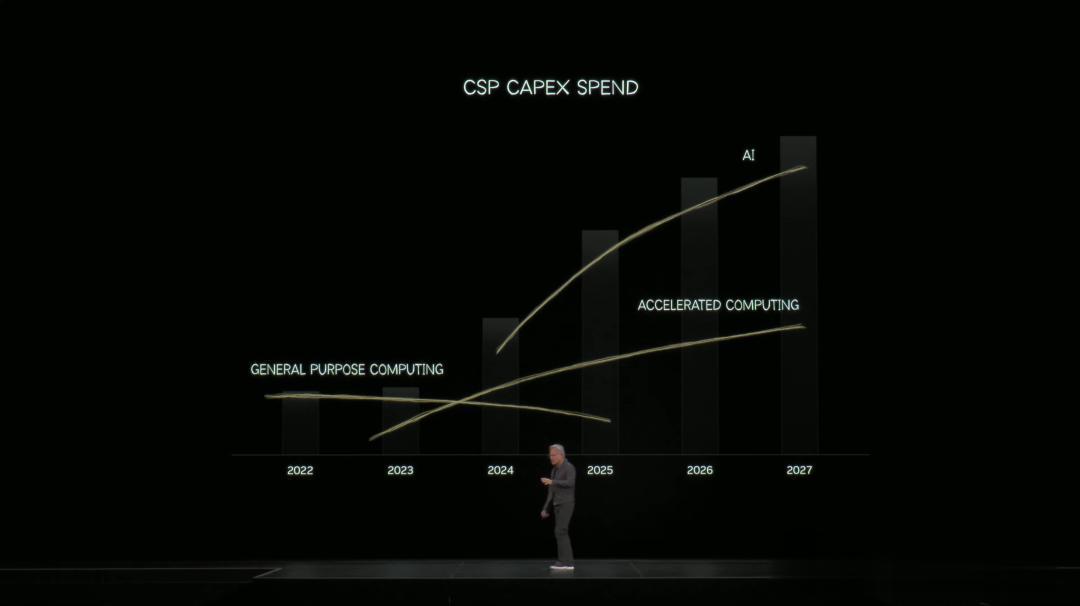
與此同時 , 老黃還指出 , 這場變革不是單線的 , 而是「雙平臺遷移」 。
即通用計算轉向加速計算 , 工具計算轉向智能計算 。
而英偉達GPU是唯一兼容以上所有的架構 , 包括加速計算和AI 。
最令人震驚是 , 他預測 , 截至2026年 , Blackwell+Rubin的可預見性收入累計5000億美元 。
算上目前已經出貨的600萬塊Blackwell , 未來兩年將達2000萬GPU出貨量 , 相較于Hopper增長5倍(400萬塊) 。
老黃正在釋放一種信號——AI工廠已成新基建 。
開源扛把子 , 沒有弱項
不僅如此 , 老黃這場演講 , 還在向世界宣告:英偉達不僅是算力之王 , 更是AI生態的絕對核心 。
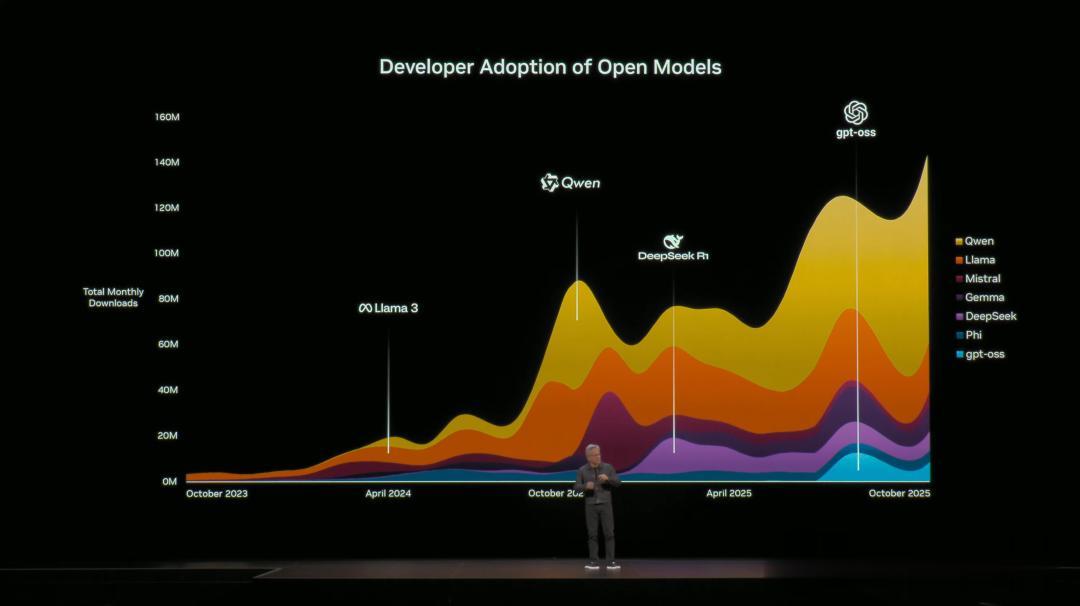
老黃一針見血 , 「過去幾年 , 開源AI在推理、多模態、蒸餾效率三大維度上 , 實現巨大飛躍」 。
正是這些進步 , 讓開源模型第一次真正成為開發者手中非常實用的工具 。
全世界 , 都離不開開源 。
為此 , 英偉達也在全力投入這一方向 。 目前 , 他們在全球開源貢獻榜上 , 23個模型上榜 , 覆蓋了語言、物理AI、語音、推理等全領域 。
我們擁有全球第一的語音模型、第一的推理模型、第一的物理AI模型 。 下載量也非常驚人 。
物理AI時代
三臺計算機鑄真神
當AI走向應用最后一層堆棧 , 那便是物理AI(Physical AI) 。
一直以來 , 老黃認為 , 要實現物理AI , 需要三臺計算機——
一個是GPU超算用于訓練 , 一個通過Omniverse Computer用于模擬 , 另一個是機器人計算機 。
以上這三種計算機上都運行著CUDA , 由此才能推動「物理AI」發展 , 也就是理解物理世界、物理定律、因果關系的AI 。
目前 , 英偉達正聯手伙伴 , 打造一個工廠級的物理AI 。 一旦建成 , 就會有大量機器人在數字孿生的世界中工作 。
Robotaxi , 也是一種機器人
在自動駕駛領域 , 英偉達推出了一套「開箱即用的L4級自動駕駛底座」——DRIVE AGX Hyperion 10 。
它搭載了NVIDIA DRIVE AGX Thor系統級芯片、經過安全認證的NVIDIA DriveOS操作系統、一套經過完整認證的多模態傳感器套件(包含14個高清攝像頭、9個雷達、1個激光雷達和12個超聲波傳感器)以及認證的板卡設計 。
- 算力與模型:共有兩顆基于Blackwell架構的DRIVE AGX Thor , 每顆算力超2000 FP4 TFLOPS(1000 INT8 TOPS) , 專為Transformer、VLA與GenAI優化 , 360°融合多模態傳感器 , 面向L4自動駕駛 。
- 迭代與驗證:平臺可OTA升級、兼容現有AV軟件 , 并引入Foretellix Foretify Physical AI工具鏈做測試與驗證;同時開放全球最大多模態AV數據集(1700小時、25國) , 用于基礎模型的開發/后訓練/驗證 。
在數萬億英里真實及合成駕駛數據的加持下 , 新一代VLA(視覺-語言-動作)推理模型 , 讓車輛不只能識別紅綠燈 , 還能在無結構路口或人車行為突變時做出類人判斷(比如理解交警臨時指揮、突發改道) , 而且是在車上實時完成 。
對于行業來說 , 公司可以直接拿到可量產的參考架構與數據/驗證閉環 , 更快把Robotaxi或無人配送車跑起來 。
NVIDIA ARC:用AI重新定義6G網絡
在通信行業 , 英偉達則宣布與諾基亞達成合作 , 并推出了支持AI原生6G的加速計算平臺——Aerial RAN Computer Pro(ARC-Pro) 。
- ARC-Pro = AI基站主機:融合了「連接+計算+感知」能力的6G-ready加速計算平臺;運營商未來可以通過軟件升級的方式從5G-Advanced升到6G 。
- AI-RAN = 無線+AI共生:把AI推理(如頻譜調度、節能控制、用戶體驗優化)和傳統RAN處理跑在同一套、由GPU加速的軟定義基礎設施上;同一站點還能順帶承載生成式/智能體AI的邊緣服務 , 有效利用「基站閑時算力」 。
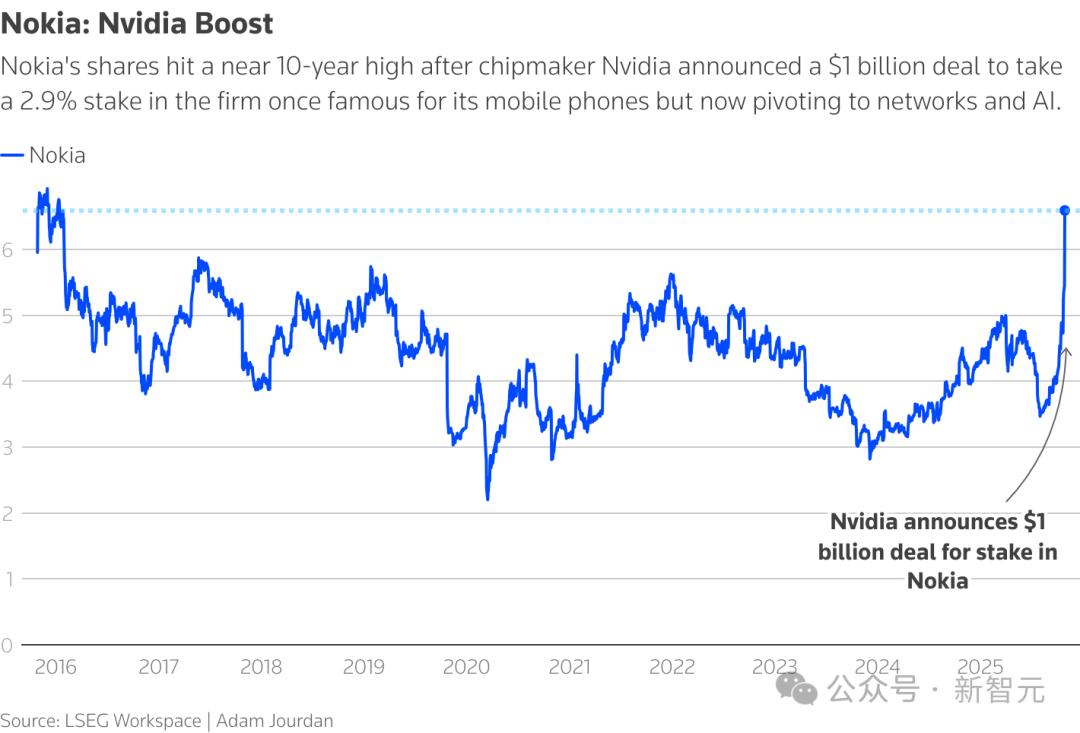
與此同時 , 英偉達還將以每股6.01美元的認購價向諾基亞投資10億美元 。
交易宣布后 , 諾基亞股價收盤上漲20.86% , 創下自2016年1月下旬以來的新高 。
NVQLink:打通AI與量子的融合之路
【「美隊」老黃深夜扔出地表最強GPU!算力百倍狂飆,下次改演雷神】在量子計算領域 , 眾所周知 , 量子計算機的核心「量子比特」(Qubits) , 雖具備碾壓傳統計算機的并行計算潛力 , 但在計算過程會不斷產生錯誤 。
為了讓它們正常工作 , 就必須依賴一臺傳統的超級計算機 , 通過一條要求嚴苛的超低延遲、超高吞吐量的連接 , 實時進行復雜的校準和糾錯 。
這條連接線 , 就是量子計算通往現實世界的最大瓶頸 。
為此 , 英偉達推出了一款全新的互連技術——NVQLink , 首次將量子處理器與AI超級計算機無縫地、緊密地連接在一起 , 形成一個單一、連貫的超級系統 。
- 硬件層:通過NVQLink , 研究人員可以把不同量子路線(超導、離子阱、光子等)的處理器和控制硬件直接接到GPU超算上 , 避免了「繞以太網一大圈」的抖動與時延;同時 , 連在一起的GPU集群還可以繼續向外擴展 。
- 軟件層:通過CUDA-Q , 研究人員可以在同一套編程接口里 , 把CPU、GPU、QPU編排成一臺「混合超算」 , 讓仿真、編排、實時控制能夠在一個平臺里閉環 。
- 生態層:集合9家美國實驗室、17家量子硬件公司、5家控制系統公司之力 , 目標是把校準、糾錯、混合應用做成可復用的「套路」 。
參考資料:
https://www.youtube.com/watch?v=lQHK61IDFH4
推薦閱讀














- AI不再「炫技」,淘寶要讓技術解決用戶每一個具體問題
- 小米17 Ultra曝取消「妙享背屏」,200MP潛望+50MP主攝彌補遺憾?
- 「進化+壓力測試」自動生成的競賽級編程題,大模型誰更hold住?
- 小說一鍵轉有聲劇!豆包語音團隊「AI多人有聲劇」,沉浸感拉滿了
- 「不僅會想,還能準確去做」VLA-R1把「推理+行動」帶進真實世界
- iPhone 19「沒了」,18 又要漲價!
- 硅谷的「十萬大裁員」:Meta按代碼量裁員
- 馬斯克「世界模擬器」首曝,1天蒸餾人類500年駕駛經驗,擎天柱同腦進化
- ?一個對話助理,如何盤活整個「夸克宇宙」?
- AI時代,努力沒用了,「躺平」才是最賺錢的方式