文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片

文章圖片

文章圖片
文章圖片
【導讀】馬斯克的終極設想 , 正在成形 。 今天 , 特斯拉放出了「世界模擬器」震撼演示 。 一個神經網絡 , 每天狂吞500年人類駕駛經驗 , 并在無限的虛擬世界中自我進化 。 同款AI大腦 , 擎天柱也可共用 。
一個神經網絡模型 , 統治了一切 。
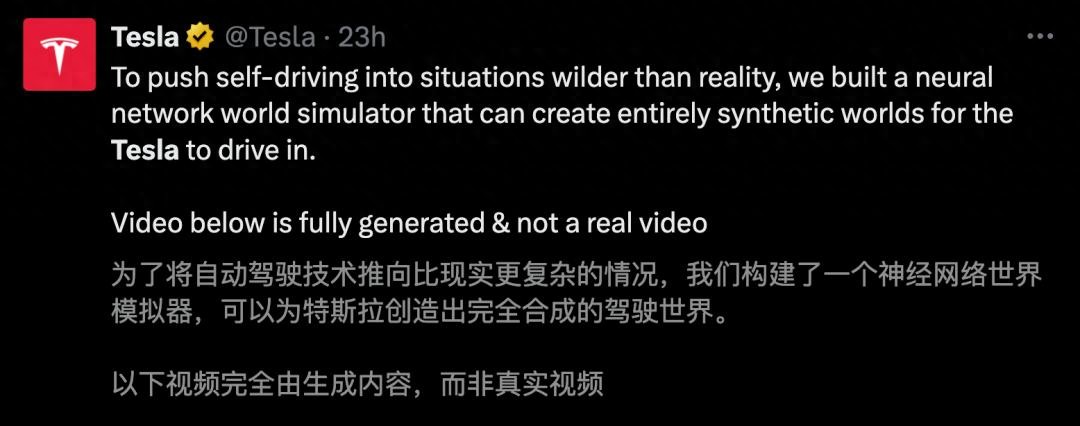
今天 , 特斯拉官宣神經網絡「世界模型器」 , AI可以直接模擬、合成自動駕駛的「孿生世界」 。
如下九宮格演示中 , 特斯拉「世界模擬器」生成了汽車行駛過程中的不同視角 。
同時 , 一些長尾場景 , 諸如行人橫穿馬路、車輛加塞 , AI都可以直接「腦補」生成 。
從相同的初始視頻出發 , 讓模擬中的汽車以對抗性方式形式
以往遇到的挑戰場景 , 「世界模擬器」能夠在虛擬世界中不斷試煉 。
從相同的初始視頻片段(綠色小方塊)開始 , 模擬會根據新的動作集發散到不同狀態
這種數據的合成 , 還可以通過像玩游戲一樣 , 在模擬的世界中駕駛 。
如下所示 , 神經網絡成功合成8個攝像頭、24幀/秒的連續畫面 , 一次直出長達6分鐘的逼真駕駛體驗 , 細節還原度驚人 。
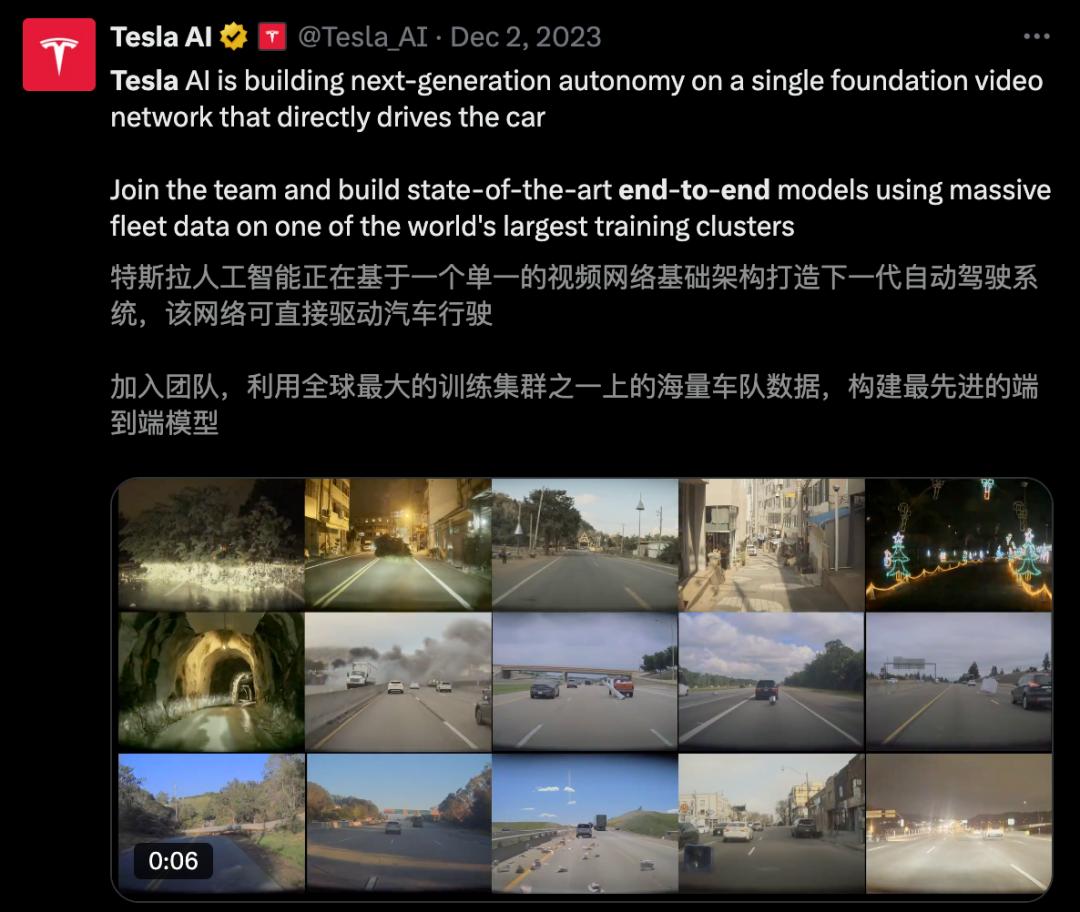
一直以來 , 馬斯克宣稱 , 特斯拉所打造「世界模型」是一套共用的AI大腦 , 并為其配上不同的「身體」——自動駕駛汽車、機器人 。
沒錯 , 這個「世界模擬器」所有合成的環境 , 同樣可以模擬多種真實場景 , 訓練擎天柱 。
擎天柱正在特斯拉的神經網絡虛擬世界中穿行
擎天柱的各種不同動作 , 都能精準地反映在虛擬世界的模擬當中
這種無限的絕佳試煉場 , 正是特斯拉讓FSD和擎天柱 , 不斷精進的秘密武器 。
那么 , 特斯拉「世界模擬器」是如何學習、訓練 , 并用于測試的呢?
近來 , 在ICCV 2025主題演講中 , 特斯拉AI團隊的負責人Ashok Elluswamy揭開了內幕 。
一個神經網絡大腦 , 兩個身體眾所周知 , 特斯拉利用一個「端到端」的神經網絡來實現自動駕駛 。
這個端到端網絡處理來自多個攝像頭、車輛速度等運動學信號、音頻、地圖及導航信息 , 最終生成控制車輛行駛的指令 。
選擇「端到端」這條技術路線 , 意味著什么?
要理解特斯拉在做什么 , 我們首先得知道 , 自動駕駛領域存在著兩條截然不同的技術路線 。
第一條路 , 也是絕大多數公司選擇的路 , 可以稱之為「模塊化」的方法 。 這種方法將駕駛任務拆解成幾個獨立的步驟:
感知(Perception):利用激光雷達、高清攝像頭等傳感器 , 識別出道路上的所有物體——這是車 , 那是人 , 這是一條車道線 。
預測(Prediction):利用感知數據 , 預測這些物體的下一步動向——那輛車可能會變道 , 那個行人可能會過馬路 。
規劃(Planning):根據預測結果 , 規劃出自己車輛的最佳行駛路徑——應該減速 , 還是應該繞行 。
這種方式的好處顯而易見:分工明確 , 每個模塊都可以獨立開發和調試 , 在項目初期更容易上手 。
第二條路 , 也是特斯拉所選擇的:是「端到端」(End-to-End)神經網絡 。
在特斯拉的系統中 , 不存在獨立的感知、預測和規劃模塊 , 只有一個龐大而統一的神經網絡 。
這個網絡的「輸入端」 , 是車輛攝像頭捕捉到的原始像素畫面、車輛自身的速度、音頻、地圖導航信息等一切原始數據;
這也是特斯拉一直以來 , 所推崇的「純視覺」方案 。
而它的「輸出端」 , 則直接是兩個指令:轉動方向盤的角度 , 和踩下油門/剎車的力度 。
在特斯拉看來 , 與依賴激光雷達等昂貴傳感器的「模塊化」(感知、預測、規劃分立)方案相比 , 端到端方案擁有根本性優勢:
1. 學習人類價值觀
復雜的現實路況充滿了「迷你電車難題」 , 這些權衡難以用代碼規則窮舉 , 但可以從海量的人類駕駛數據中隱式學習 。
舉個栗子 , 在下面的場景中 , AI需要決定是直接碾過前方一大片水洼 , 還是借道對向車道 。
通常來說 , 突然駛入另一側車道會存在一定的危險 。
傳統的「模塊化」系統會在這里陷入邏輯沖突 。
它的程序里可能有兩條寫死的規則:「規則A:絕對不能駛入對向車道」和「規則B:避免駛過障礙物(如此大的水坑)」 。
當兩條規則沖突時 , 系統該如何抉擇?
但眼下能見度足夠高 , 在可預見的未來未來不會有對向車輛駛來;其次 , 水坑比較大 , 最好是避開 。
而這種權衡 , 很難用傳統編程邏輯描述出來 , 但人看一眼就知道該怎么做了 。
這只是經典「迷你電車難題」其中一個案例 , 現實中 , 自動駕駛汽車還會遇到各種罕見的問題 。
AI不是在執行規則 , 而是在學習一種更接近人類價值觀的判斷方式 。
2. 消除模塊間的信息損失
在傳統方案中 , 感知、預測和規劃模塊之間的接口難以明確界定 。
而在端到端系統中 , 梯度能夠從最終的控制指令一直反向傳播至傳感器輸入 , 從而對整個網絡進行整體性優化 。
如下兩段路況:一個是雞群要過馬路 , 另一個是鵝群在路中間溜達 。
若在「感知」和「規劃」這兩個模塊之間 , 建立一套明確的判斷規則(本體論ontology)非常困難 。
對于模塊化系統 , 「感知」模塊可能會給「規劃」模塊傳遞這樣的信息:「識別到一群鳥類」 。
但這種信息是冰冷的 。
這群鳥的「意圖」——一種微妙、難以量化的信息——在模塊之間的傳遞過程中很容易丟失 。
「規劃」模塊無法知道 , 它應該為這群雞減速讓行 , 還是可以安全地繞過這群鵝 。
一群雞正在路邊 , 看起來有要過馬路的意圖;FSD停車等待
一群鵝在路邊 , 但它們只是想待在原地;FSD直接繞行
在「端到端」的網絡里 , 不存在這種信息傳遞的壁壘 。
【馬斯克「世界模擬器」首曝,1天蒸餾人類500年駕駛經驗,擎天柱同腦進化】整個網絡作為一個整體 , 直接從像素中理解了「雞要過馬路」和「鵝想待著」這兩種不同的「軟意圖」(soft intent) , 并直接輸出減速或繞行的駕駛行為 。
從輸入到輸出 , 信息是完整流動的 , 不存在中間環節的損耗 。
正是基于這些原因 , 特斯拉選擇了「端到端」這條路 。 當然 , 也伴隨著巨大的挑戰 。
3. 可擴展性與簡潔性
它能更好地處理現實世界中無窮無盡的「長尾問題」 , 并且計算架構統一 , 延遲確定 。
4. Scaling Law的延續
總體而言 , 這更符合「苦澀的教訓」(The Bitter Lesson)所揭示的規律——即強大的通用方法和海量算力 , 最終將超越復雜的人工設計 。
正是因為上面這些原因 , 以及其更多其他的考量 , 特斯拉才選擇了「端到端」架構來做自動駕駛 。
不過話說回來 , 要打造這樣的系統 , 還得克服不少難題 。
20億token輸入 , 跳出「維度詛咒」在真實世界中 , 一個安全的自動駕駛系統 , 需要處理高幀率、高分辨率、長時間序列的輸入信息 。
特斯拉算了一筆賬:
7個攝像頭×36幀/秒×500萬像素×30秒歷史數據 未來幾英里的導航地圖和路線 100 Hz車輛動態數據 , 如速度、慣性測量單元(IMU)、里程計等 48 KHz音頻數據如果將這些輸入token拆分成最小的「信息單元」 , 比如每個圖像塊是5x5像素 , token總數將高達20億個 。
神經網絡的任務 , 就是在這20億個輸入信息單元中 , 找到正確的因果關系 , 并最終將其壓縮成2個token——方向盤和加減速 。
這是一個極其棘手的問題 , AI很容易在如此海量的數據中 , 學到錯誤的、偶然的「相關性」 , 而非真正的「因果性」 。
特斯拉的解法簡單粗暴:用巨大的數據量來解決問題 。
他們坐擁一個數據寶庫 , 其車隊每天能產生相當于人類500年駕駛時長的海量數據 。
負責人Ashok Elluswamy將其稱之為 , 「Niagara Falls of data」 。 當然 , 并非所有數據都有用 。
因此 , 特斯拉建立了一套復雜的「數據引擎」流水線 , 從海量視頻中自動篩選出最有趣、最罕見、最高質量的學習樣本 。
當AI學習了足夠多這樣的「疑難雜癥」數據后 , 它就能展現出驚人的泛化能力 。
比如在一個雨天路滑的場景中 , AI在前方車輛還未明顯失控時 , 就提前開始減速 。
它理解到:下雨、前車可能打滑、撞上護欄后可能反彈回車道……這種對「二階效應」的預判 , 只有在見過足夠多復雜情況后才能學會 。
FSD思維過程揭開 , 全憑攝像頭「端到端」系統最大的詬病在于——「黑箱」特性 。
如果車輛做出了一個奇怪的舉動 , 工程師如何知道是哪里出了問題?
Ashok認為 , 這個「黑箱」其實可以被打開 。
特斯拉神經網絡在輸出最終駕駛指令的同時 , 也能輸出可供人類理解的「中間token」(Intermediate Tokens) 。
這些token可以被看作是AI的「思考過程」 , 也是人們常說的CoT 。
完整架構與可解釋性輸出
其中一項最直觀的技術 , 叫做「生成式高斯潑濺」(Generative Gaussian Splatting) 。
車輛在行駛過程中 , 軌跡通常是線性的 , 導致視角變化不足 , 用傳統方法重建3D模型質量不高 。
尤其是 , 在新視角下更容易失真 。
此外 , 3D高斯潑濺還需要以來 , 其他pipeline良好的初始化 , 整體優化時間可能長達數分鐘 。
另一方面 , 它還具備了出色的泛化能力 。
無需初始化 , 全程運行時間僅約220毫秒 , 能夠對動態物體進行建模 , 還能和端到端大模型聯合訓練 。
最厲害的是 , 所有這些高斯點 , 都基于車上配置的攝像頭生成 。
特斯拉神經網絡生成的高斯潑濺渲染的新視角
此外 , AI還能用自然語言解釋它的決策 。 這套系統已經在FSD v14.x版本中部分運行 。
自然語言推理
世界模擬器 , AI無限試錯最后一個 , 也是最難的挑戰是——評估 。
一個訓好的自動駕駛系統 , 若在真實道路上測試 , 既危險又緩慢 。
即使AI在歷史數據上表現完美 , 也不意味著它能在真實世界中應對自如 。
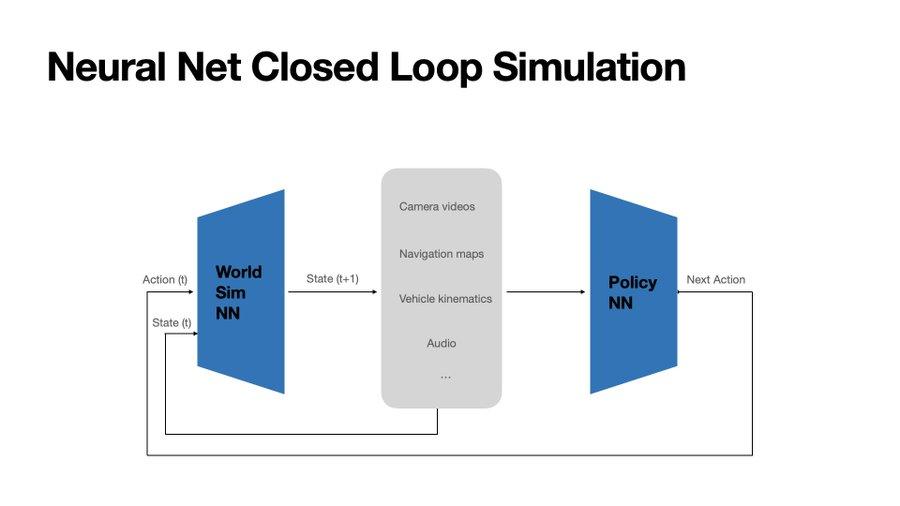
為此 , 特斯拉亮出了終極武器:一個完全由神經網絡構成的「世界模擬器」 。
這個模擬器和駕駛AI一樣 , 也是用海量真實世界數據訓練出來的 。
但它的功能不同:它不是根據當前狀態預測「下一步該怎么開」 , 而是根據「當前狀態」和「一個駕駛動作」 , 來生成「下一秒世界會變成什么樣」 。
這個模擬器能以極高的保真度 , 實時生成車輛所有攝像頭應該看到的畫面 。 它就像一個由AI創造的、無限逼真的駕駛視頻游戲 。
如前所述 , 這個「世界模擬器」的威力在于:
閉環評估:可以將新的駕駛AI模型放入這個模擬世界中 , 讓它自由駕駛 , 評估其長期表現 。
情景再現與修改:可以截取一段真實發生的危險場景 , 讓AI在這個模擬世界里用不同的方式重新應對一次 , 看看結果是否會更好 。
創造對抗性場景:可以人為地在模擬世界中創造出極端、罕見的危險情況 , 比如讓一輛車突然做出不合常理的舉動) , 專門測試AI的應對極限 。
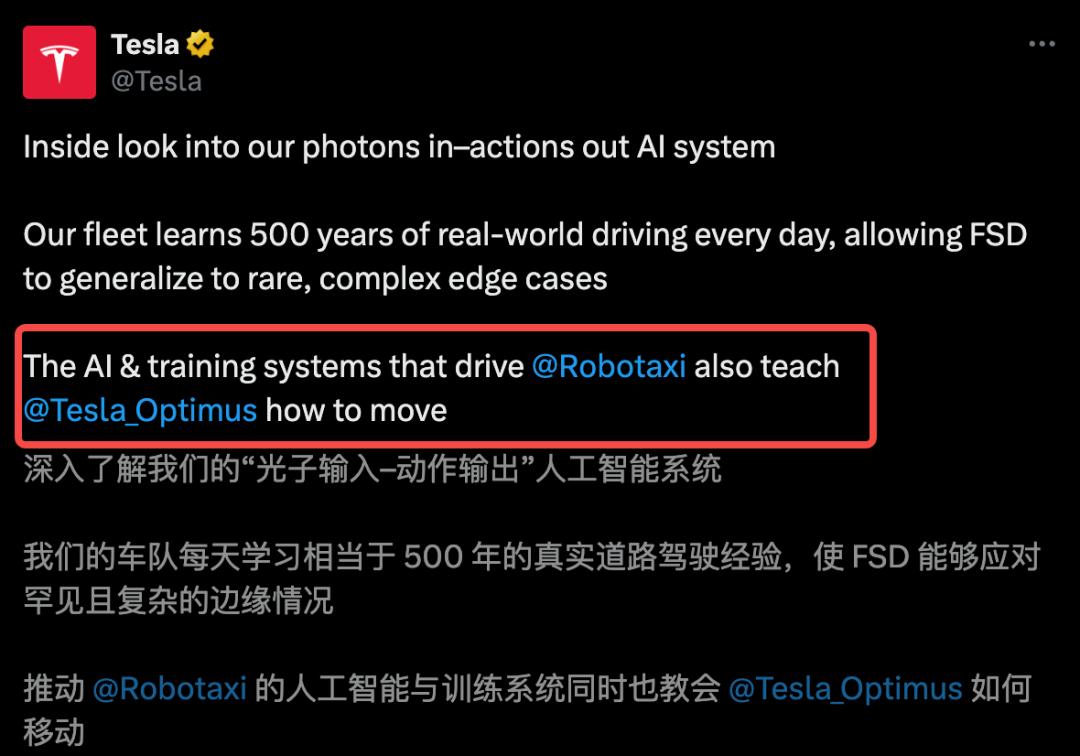
真正的終局:人形機器人講到這里 , 你會發現 , 特斯拉的野心早已超越了「造車」 。
汽車 , 只是他們收集數據的觸手 , 和這套AI系統的第一個應用載體 。 他們真正打造的 , 是一套可以解決通用物理世界交互問題的底層AI引擎 。
最好的證據是 , 這套系統已經無縫遷移到了他們的另一個人形機器人項目——擎天柱(Optimus)上 。
為FSD打造的「世界模擬器」 , 同樣可以為擎天柱生成在工廠里漫步的場景 , 測試和訓練它在物理世界中的導航與交互能力 。
而這 , 才是特斯拉自動駕駛故事背后 , 那個更宏大、也更激動人心的未來 。
擴展閱讀:CVPR史上首次!中國車廠主講AI大模型 , 自動駕駛也玩Scaling Law?
參考資料:
https://x.com/aelluswamy/status/1981644831790379245
https://www.youtube.com/watch?v=wHK8GMc9O5A
https://x.com/Tesla/status/1982255564974641628
本文來自微信公眾號“新智元” , 編輯:桃子 好困, 36氪經授權發布 。
推薦閱讀














- 馬斯克沉迷二次元!Grok推出AI伴侶新角色Mika
- ?一個對話助理,如何盤活整個「夸克宇宙」?
- 馬斯克冤家,挖到腦機接口猛將
- AI時代,努力沒用了,「躺平」才是最賺錢的方式
- 奧特曼搶走小扎印鈔機,Meta「占領」OpenAI,20%都是前同事
- 永別了,死亡!她用AI「復活」丈夫,讓愛重生
- AI時代,開發者不能再當 i 人了,「云計算代言人」敬告
- 夸克對話助手PK豆包:兩種路線,大戰在即?
- 庫克底褲都輸掉了,蘋果集體訴訟案敗訴或賠142億元
- 死磕「文本智能」,多模態研究的下一個前沿