
文章圖片

文章圖片
文章圖片
文章圖片
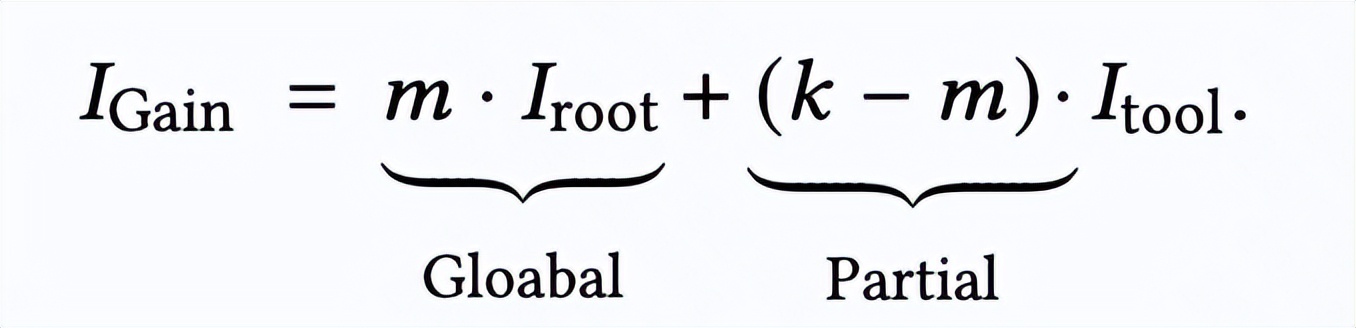
文章圖片

文章圖片

文章圖片
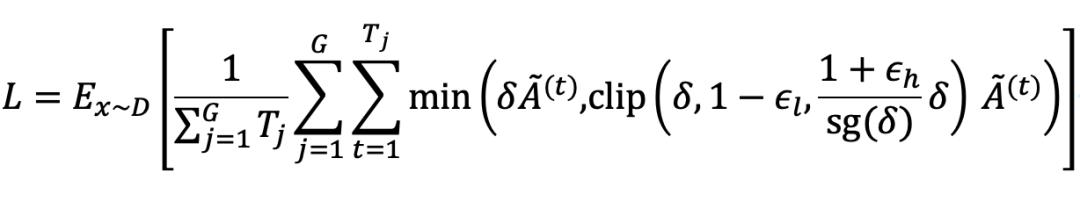
文章圖片
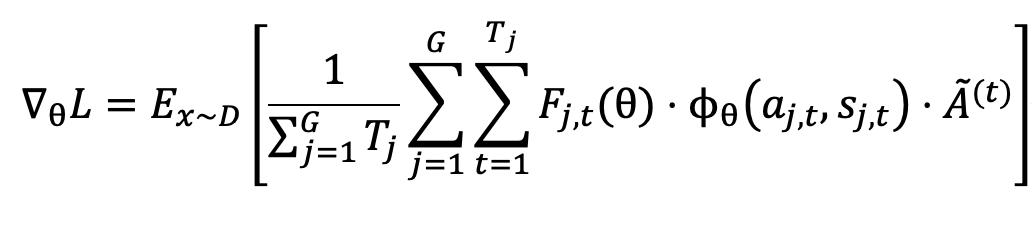
文章圖片
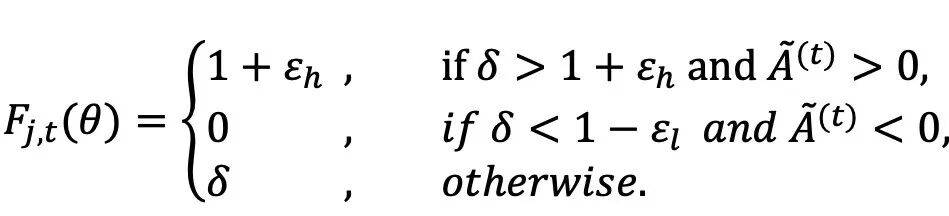
文章圖片

文章圖片
文章圖片
在智能體強化學習的快速發展中 , 如何在探索與穩定之間取得平衡已成為多輪智能體訓練的關鍵 。 主流的熵驅動式智能體強化學習(Agentic RL)雖鼓勵模型在高不確定性處分支探索 , 但過度依賴熵信號常導致訓練不穩、甚至策略熵坍塌問題 。
為此 , 中國人民大學高瓴人工智能學院與快手 Klear 語言大模型團隊聯合提出 Agentic Entropy-Balanced Policy Optimization(AEPO) , 一種面向多輪智能體的熵平衡強化學習優化算法 。
AEPO 系統性揭示了「高熵 Rollout 采樣坍縮」和「高熵梯度裁剪」問題 , 并設計了「動態熵平衡 Rollout 采樣」與「熵平衡策略優化」兩項核心機制 。 前者通過熵預監控與連續分支懲罰實現全局與局部探索預算的自適應分配 , 后者在策略更新階段引入梯度停止與熵感知優勢估計以保留高熵 token 的探索梯度 。
圖 1:AEPO 性能概覽:左圖對比深度搜索任務性能 , 右圖對比通用推理任務性能
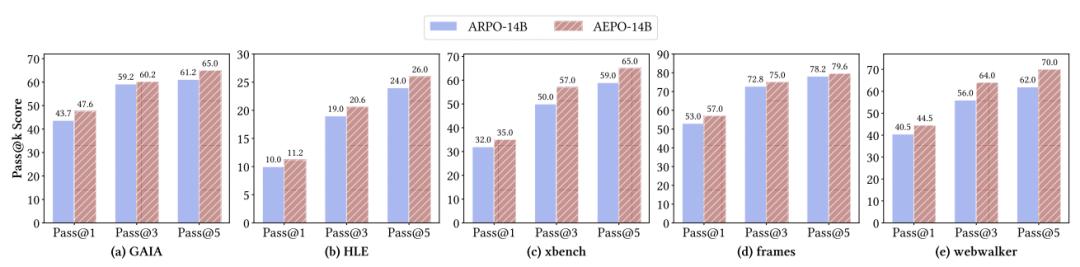
實驗結果表明 , AEPO 在 14 個跨領域基準上顯著優于七種主流強化學習算法 。 特別是深度搜索任務的 Pass@5 指標:GAIA (65.0%) Humanity’s Last Exam (26.0%) WebWalkerQA (70.0%) 。 在保持訓練穩定性的同時進一步提升了采樣多樣性與推理效率 , 為通用智能體的可擴展強化訓練提供了新的優化范式 。
論文標題:Agentic Entropy-Balanced Policy Optimization 論文鏈接:https://arxiv.org/abs/2510.14545 代碼倉庫:https://github.com/dongguanting/ARPO 開源數據模型:https://huggingface.co/collections/dongguanting/aepo-68ef6832c99697ee03d5e1c7目前 AEPO 在 X 上收獲極高關注度 , Github 倉庫已獲星標 700 余枚 , 同時榮登 Huggingface Paper 日榜第二名!
研究動機:在高熵中尋求平衡
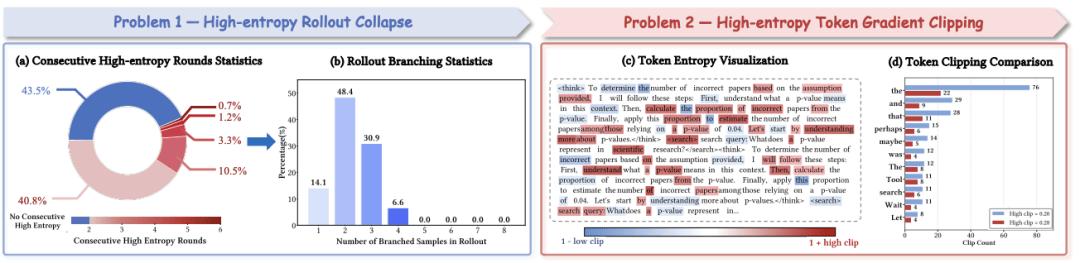
隨著 Agentic RL 的發展 , 如何在持續探索與訓練穩定之間取得平衡已成制約智能體性能的關鍵 。 現有方法(如 ARPO)通常依賴熵信號作為依據 , 并在高熵時刻觸發分支采樣探索潛在推理路徑 。 我們的研究發現熵驅動的探索雖能提升多樣性 , 卻也帶來了顯著的訓練不穩定:模型在連續高熵的工具調用階段容易出現單一鏈條過度分支 , 導致探索受限(如下圖左側);同時在策略更新階段 , 高熵 token 的梯度常被無差別裁剪 , 使模型難以學習的探索行為(如下圖右側) 。 這種熵失衡也使智能體在強化學習中容易陷入局部最優解 。
圖 2:智能體中的高熵 Rollout 坍縮與高熵梯度裁剪現象
因此 , 如何在高熵驅動下同時實現高效探索與穩定優化 , 成為智能體強化學習亟待突破的核心瓶頸 。 為此 , 我們提出 AEPO , 一種面向多輪智能體的熵平衡強化學習優化算法 。 我們的貢獻如下:
我們系統性分析并揭示了現有熵驅動的 Agentic RL 在高熵階段易出現的「rollout 坍縮」和「梯度裁剪」問題 , 為后續算法設計提供了經驗與理論依據 。 我們提出了 AEPO 算法 , 旨在通過「動態熵平衡 Rollout 采樣」與「熵感知策略優化」兩個階段實現強化學習探索與穩定的協同優化 。 在 14 個挑戰性基準上的實驗結果表明 , AEPO 在采樣多樣性、訓練穩定性及工具調用效率方面均優于 7 種主流強化學習算法 , 為智能體在復雜開放環境下的可擴展訓練提供了新的啟發 。工具調用的熵變現象:高熵集聚與梯度困境
通過分析智能體在多輪工具調用強化學習中的 token 熵變與訓練過程 , 我們發現以下核心現象:
高熵工具調用步驟存在連續性:連續的高熵工具調用輪次占比達 56.5% , 部分軌跡甚至出現 6 次連續高熵調用 , 這種連續性導致 rollout 階段的分支預算分配嚴重傾斜(如下圖左側); 高熵 Token 梯度裁剪:傳統 Agentic RL 算法在策略更新階段存在「無差別梯度裁剪」問題 , 未區分其是否包含有價值的探索行為 , 這些 token 大多是在推理中激發工具調用 , 反思等行為的提示(如下圖右側) 。
圖 3:智能體強化學習訓練中兩種熵相關問題的量化統計
上述現象本質是高熵信號的雙重矛盾:高熵是智能體探索工具使用潛力的必要條件 , 但無約束的高熵連續性會破壞 rollout 資源分配 , 激進的梯度裁剪又會扼殺高熵的探索價值 。
AEPO 算法:熵驅動的精準探索與梯度保護
圖 4:AEPO 概述
動態熵平衡 Rollout 采樣:
1.熵預監測:按信息增益分配采樣預算
傳統 RL 算法(如 ARPO)憑經驗分配全局采樣與分支采樣的坍縮資源 , AEPO 則基于信息增益理論 , 根據問題與工具的信息增益動態調整采樣預算 , 具體來說 , 在總 rollout 采樣的預算為 k(包含 m 次全局采樣與 k-m 次高熵分支采樣)的條件下 , 將 Rollout 階段的信息增益簡單地建模為:
在語言模型的自回歸解碼過程中 , 輸入問題的信息增益通常由模型解碼的 token 熵值來衡量 , 因此我們可以得到如下正相關關系:
因此 , 我們的目標是盡可能增大 Rollout 階段的信息增益 , 基于上述公式 , AEPO 按信息增益分配采樣預算:
2.連續高熵分支懲罰:避免單一軌跡過度分支
即使預算分配合理 , 連續高熵調用仍可能導致單一軌跡過度分支 。 因此 AEPO 通過動態分支概率施加懲罰:
實驗驗證:如下圖所示 , 相比于 ARPO 通常僅分支 2-3 條軌跡 , 而 AEPO 可覆蓋全部 8 條預算軌跡(右圖) , 采樣聚類數從 54 提升至 62(左 2 圖) , 大幅提升 Rollout 采樣的多樣性 。
圖 5:采樣多樣性 ARPO vs AEPO(左)與 Rollout 的分支采樣分布(右)
【AEPO:智能體熵平衡策略優化,讓探索更穩,推理更深!】熵平衡策略優化:
1.熵裁剪平衡機制:保留高熵 Token 梯度
收到 GPPO 啟發 , AEPO 將「梯度停止」操作融入到策略更新的高熵裁剪項中 , 保證了前向傳播不受影響 , 同時保護了高熵 token 的梯度在反向傳播時不被裁剪 。 AEPO 在策略更新時使用如下公式:
這一設計讓高熵探索性 Token 的梯度得以保留 , 避免訓練初期探索能力流失 。
2.熵感知優勢估計:優先學習高價值探索行為
實驗結果:14 個基準驗證 AEPO 的高效與穩定
為了充分評估 AEPO 的泛化性和高效性 , 我們考慮以下三種測試集:
計算型推理任務:評估模型的計算推理能力 , 包括 AIME24、AIME25、MATH500、GSM8K、MATH 。 知識密集型推理任務:評估模型結合外部知識推理的能力 , 包括 WebWalker、HotpotQA、2WIKI、MisiQue、Bamboogle 。 深度搜索任務:評估模型的深度搜索能力 , 包括 HLE、GAIA、SimpleQA、XBench、Frames 。深度信息檢索任務:小樣本實現大突破
如上表所示 , 僅用 1K RL 訓練樣本 , Qwen3-14B+AEPO 在關鍵任務上表現優異:
AEPO 在 Pass@1 上較 ARPO 平均提升 3.9%;在 Pass@5 上較 ARPO 平均提升 5.8%; 對比梯度裁剪優化 RL 算法(DAPO、CISPO、GPPO):AEPO 在 GAIA 任務上領先 7%-10% , 在 Qwen3-14B 基座上取得了 47.6% 的 Pass@1 與 65% 的 Pass@5 , 這證明熵平衡機制優于單純的梯度裁剪優化 RL 算法; 對比傳統 RL(GRPO、Reinforce++):AEPO 在 HLE 任務上領先 2.6%-3.4% , 在 Qwen3-14B 基座上取得了 11.2% 的 Pass@1 與 26% 的 Pass@5 , 凸顯 Agentic RL 中熵平衡的必要性 。
我們比較了 7 種強化學習算法在 10 個推理任務中的表現 , 發現:
梯度裁剪優化算法的穩定性差:在 Qwen 2.5-7B-instruct 上 , 梯度裁剪優化算法表現良好 , 但在 Llama3-8B 上未顯著優于 GRPO , 且易導致熵崩潰 。 Agentic RL 算法具備泛化能力:ARPO , GIGPO , AEPO 等算法在不同模型上表現穩定 , 證明在高熵環境下的分支探索有效 。 AEPO 優勢顯著:AEPO 在所有測試中表現突出 , 一致性高于 7 種主流 RL 算法 。 并且平均準確率比 GRPO 高 5% , 更適合訓練多輪次 Web 智能體 。實驗:熵穩定與準確率分析
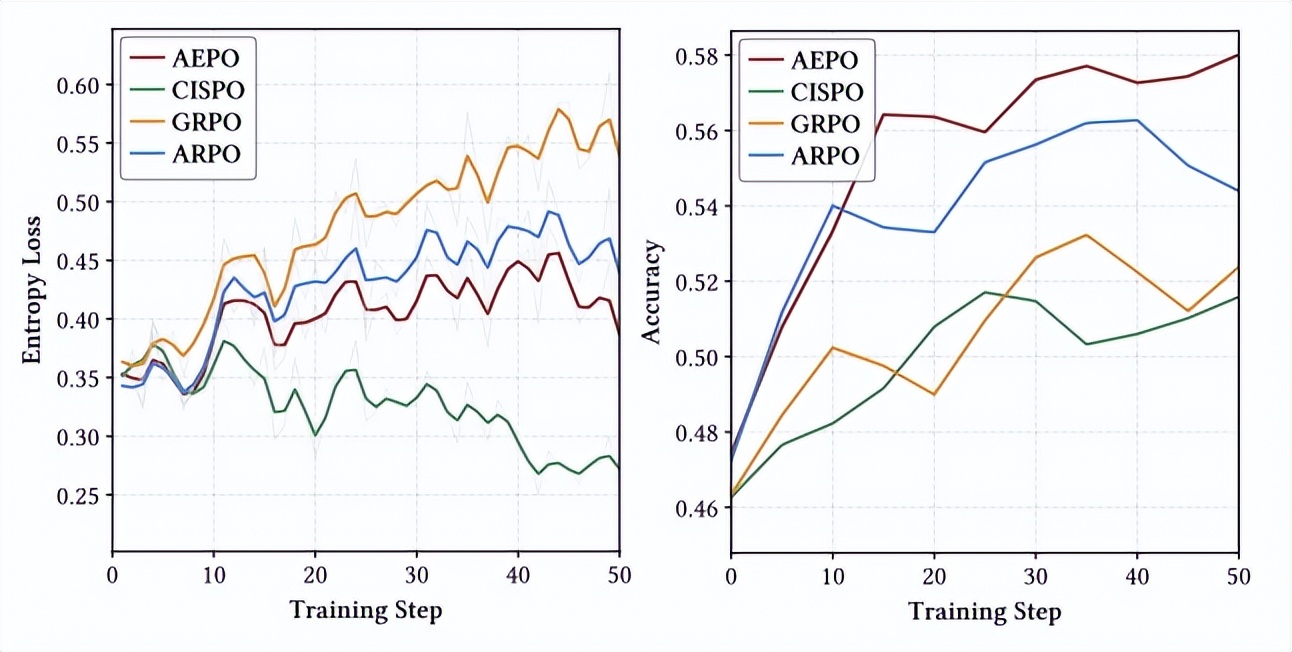
在 Agentic RL 訓練中 , 熵動態穩定性與訓練準確率收斂性是衡量算法有效性的核心指標:熵過高易導致探索失控 , 熵過低則會引發探索不足;而準確率的持續提升則直接反映模型對有效工具使用行為的學習能力 。
我們對比 AEPO 與主流 RL 算法(含 ARPO、GRPO、DAPO 等)在 10 個推理任務中的訓練動態 , 清晰揭示了 AEPO 在「熵穩定」與「準確率提升」雙維度的優勢 。 實驗發現訓練的熵損失驟增與下降都不會對性能帶來增益;相比之下 , AEPO 的熵損失全程維持高且穩定 , 對應穩定的性能增益 。 其表現遠超其他 RL 算法 , 且解決了 ARPO 在訓練后期熵波動的問題 。
圖 5:訓練指標可視化 , 包括各訓練步驟的熵損失(左)和準確率(右)
總結與未來展望
未來可從三個方向進一步拓展:
多模態 Agent:當前 AEPO 與 ARPO 均聚焦文本任務 , 未來可擴展至圖像、視頻等多模態輸入 , 探索多模態工具的熵平衡優化 , 解決多模態反饋帶來的熵波動問題 。 工具生態擴展:引入更復雜工具(如 MCP 服務、外部訂機票酒店服務調用、代碼調試器) , 基于 AEPO 的熵感知機制優化多工具協作策略 , 提升復雜任務表現 , 超越現有工具協作能力 。 多智能體強化學習:探索在更多智能體的協作學習 , 互相任務交互與博弈中找到平衡 , 實現收斂 。作者介紹
董冠霆目前就讀于中國人民大學高瓴人工智能學院 , 博士二年級 , 導師為竇志成教授和文繼榮教授 。 他的研究方向主要包括智能體強化學習、深度搜索智能體 , 大模型對齊等 。 在國際頂級會議如 ICLR、ACL、AAAI 等發表了多篇論文 , 并在快手快意大模型組、阿里通義千問組等大模型團隊進行實習 。 其代表性工作包括 ARPO、AUTOIF、Tool-Star、RFT、Search-o1、WebThinker、Qwen2 和 Qwen2.5 等 。
個人主頁:dongguanting.github.io本文的通信作者為中國人民大學的竇志成教授與快手科技的周國睿 。
推薦閱讀














- 谷歌Gemini 3確認年內發布 主攻復雜智能體
- 工業具身智能矩陣成型!普羅宇宙發布大白機器人2.0 及靈巧手
- 實測:什么是“全智能手表”,到底又好在哪?
- 智元機器人真機強化學習落地工業產線,開啟具身智能規模化新階段
- 達摩院推出多智能體框架ReasonMed,打造醫學推理數據生成新范式
- 聚焦人工智能、腦機接口等前沿 國際圖象圖形學學術會議舉行
- OPPO連續四年承辦,2025中國高校計算機大賽-智能交互創新賽圓滿落幕
- 不知不覺,小米又第一名了,智能門鎖拿下26.5%的份額
- 智能體系統如何「邊做邊學」?斯坦福團隊探索在線優化的新范式
- 機器人做開場主持人?金融街論壇企業家圓桌會議關注“具身智能”