
文章圖片
文章圖片

去年年底 Physical Intelligence 發布機器人基礎模型 π0 時 , 其團隊成員將其比作“機器人領域的 GPT-1” 。 就像 OpenAI 在 2018 年推出第一代語言模型時開啟了一個時代 , π0 預示著機器人智能也許會走上類似的路:模型越大、數據越多 , 能力就越強 。 但在那個時候 , 這更多還只是個愿景 。 機器人領域的 Scaling Law 始終沒有被明確建立 。
2025 年 11 月 4 日 , 由前 Google DeepMind 高級研究員 Pete Florence 創立的初創公司 Generalist AI 為這一問題給出了迄今為止最有力的答案 。 該公司發布的 GEN-0 模型不僅展示了機器人基礎模型的擴展能力 , 更重要的是 , 首次在機器人領域觀察到了一個此前只在語言模型訓練中出現的關鍵現象:模型僵化(ossification) 。 這一發現表明 , 機器人領域的智能確實存在可量化的擴展定律 , 但其運作方式比我們想象的更加復雜 。
物理智能的閾值之謎
在計算機視覺和自然語言處理領域 , scaling laws 已經成為一個被廣泛接受的現象 。 但在機器人領域 , 這樣的規律一直未能建立 , 主要原因是缺乏足夠規模的高質量數據 , 以及足夠大的模型來驗證這種關系 。
盡管 MIT 和慕尼黑工業大學的研究人員在 2024 年通過對 327 篇論文的元分析發現機器人基礎模型確實存在 scaling laws , 但這些研究都是基于相對較小規模的模型和數據集 。 如果我們將模型規模推向數十億參數 , 將訓練數據推向數十萬小時時 , 會發生什么?
圖丨相關論文(來源:arXiv)
【27萬小時的真實數據,終于驗證了機器人領域的Scaling Law?】
GEN-0 的實驗給出了一個意外的答案 。 研究團隊發現 , 當將模型從 1B(十億)參數擴展到 7B 參數的過程中 , 存在一個明顯的相變點 。 1B 參數的模型在訓練過程中很快就表現出僵化現象 , 即模型權重變得無法吸收新的信息 , 訓練損失不再下降 。 這種現象此前只在語言模型的特定訓練場景中被觀察到 , 但那些模型的參數規模要小得多 , 大約在 10M(百萬)量級 。
(來源:Generalist AI)
而當模型規模達到 6B 參數時 , 情況開始改變 。 這些模型能夠有效地從預訓練中受益 , 展現出強大的多任務能力 。 到了 7B 參數及以上 , 模型不僅能夠內化大規模的機器人預訓練數據 , 還能夠僅通過幾千步的后訓練就遷移到下游任務 。 Generalist AI 已經將 GEN-0 擴展到 10B+ 參數規模 , 觀察到隨著規模增加 , 模型對新任務的適應越來越快 , 需要的后訓練越來越少 。
研究團隊認為這一發現與人工智能史上一個著名的 Moravec 悖論(Moravec's Paradox)相呼應 。 1988 年 , 機器人學家 Hans Moravec 指出 , 對人類來說輕而易舉的事情 , 比如感知和靈巧操作 , 對機器來說需要巨大的計算復雜度 , 而抽象推理這種人類覺得困難的事情 , 對機器反而相對簡單 。 GEN-0 的實驗結果為這個悖論提供了定量證據:物理世界的常識(physical commonsense)確實有更高的“激活閾值” , 需要更大規模的計算才能涌現 。
(來源:Generalist AI)
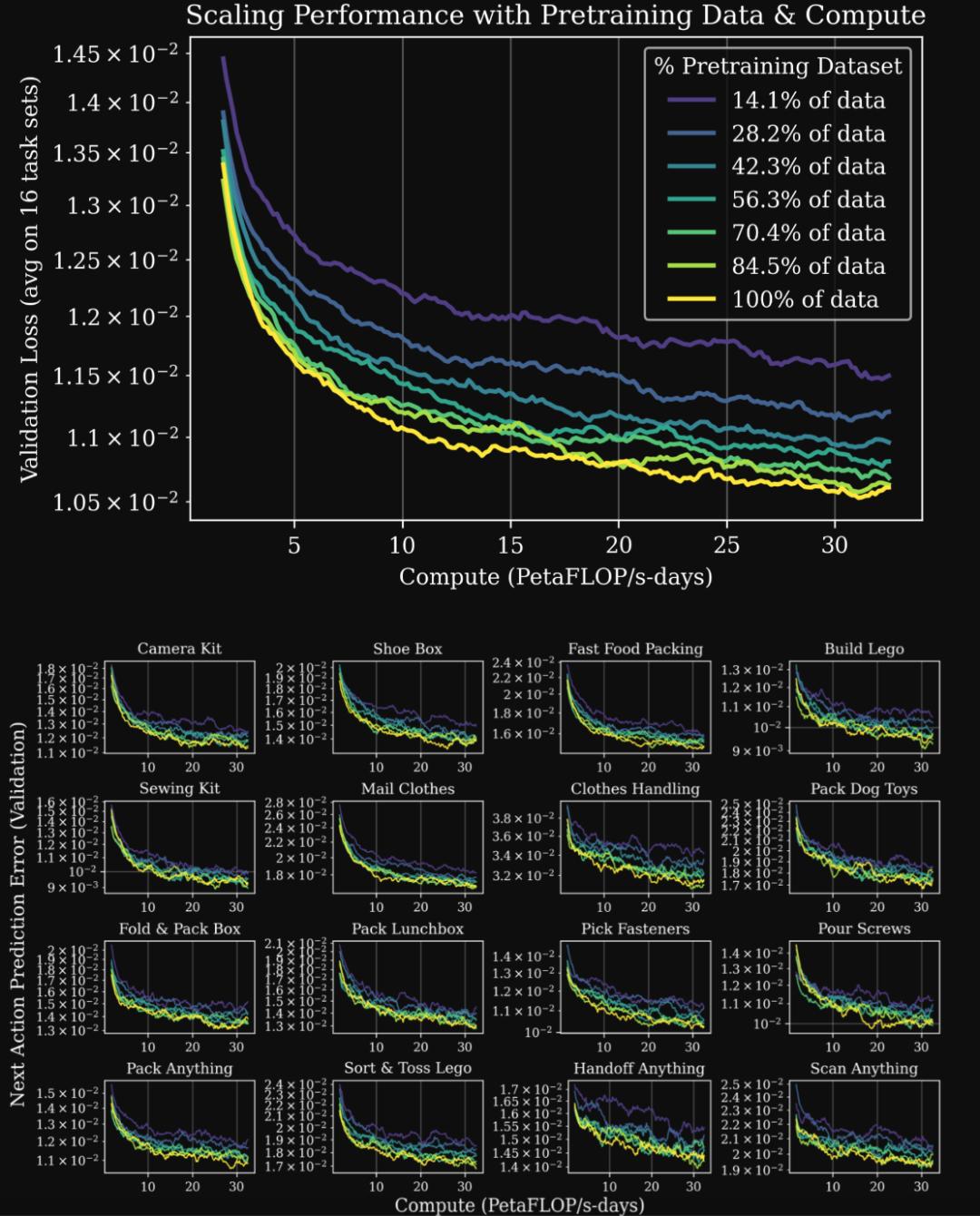
這種可預測的擴展關系對工程實踐有重要意義 。 研究團隊可以用冪律公式預測:給定特定規模的預訓練數據 , 在某個下游任務上投入固定的微調預算 , 最終能達到什么樣的性能水平 。 以服裝處理任務為例 , 他們可以估算需要多少預訓練數據才能將動作預測誤差降到特定閾值 。 這種預測能力讓資源分配不再是賭博式的探索 , 而是有明確回報預期的投資 。
Harmonic Reasoning:協調思考與行動
如果說擴展規律解決了能不能學的問題 , 那么 GEN-0 引入的 Harmonic Reasoning 則回答了“怎么學” 。 這是一個針對物理世界特性設計的訓練機制 , 核心在于協調“思考”與“行動”之間的時間關系 。
在語言模型中 , 讓系統“多想一會兒再回答”相對容易 , 只需在生成回復前多運行幾步推理 。 但物理世界不會暫停等待 。 當機器人面對需要精細操作的任務時 , 它既要實時響應環境變化 , 又要進行更高層次的規劃 。
傳統的 System 1-System 2 架構試圖將這兩種過程分離 , 用快速反應系統處理即時響應 , 用慢速規劃系統處理長期決策 。 但這種分離帶來了接口設計的復雜性 , 也限制了系統的靈活性 。
Harmonic Reasoning 采用了不同的思路 。 它將感知、思考和行動都視為在連續時間軸上異步發生的 token 流 , 通過訓練讓模型學會在這些流之間建立協調的相互作用 。
模型在處理視覺輸入的同時 , 可以生成“內部推理”的 token , 這些 token 不會直接轉化為動作 , 而是影響后續的決策;同時 , 模型持續輸出動作 token 來控制機器人的關節 。 這種設計讓模型可以在執行當前動作的同時思考未來步驟 。
從展示的案例來看 , 這種能力在長程任務中表現明顯 。 在組裝相機套件的演示中 , 機器人需要完成一系列精細操作:將清潔布放入盒子、折疊紙板托盤、從塑料袋中取出相機、放入盒中、合上盒蓋并插入細小的固定卡扣 , 最后丟棄塑料袋 。 整個過程持續超過一分半鐘 , 模型從未依賴顯式的子任務分解 , 而是在一個統一的推理流中完成全部步驟 。
這種訓練方式不依賴推理時的額外引導(inference-time guidance) 。 許多現有系統需要在部署時引入啟發式規則或外部規劃器來輔助決策 , 但 GEN-0 的所有能力都內化在預訓練模型中 。 團隊認為 , 這種端到端的學習路徑是實現真正通用性的前提 。 就像語言模型不需要為每個應用場景單獨設計提示一樣 , 機器人模型也應該通過大規模預訓練自然涌現出適應性 。
二十七萬小時的真實數據
長期以來 , 數據稀缺一直是機器人學習的主要瓶頸 。 相比于語言模型可以從互聯網上獲取數萬億 tokens 的文本數據 , 機器人數據的收集需要真實的硬件在物理世界中執行操作 , 成本高昂且難以擴展 。
Generalist AI 在這個問題上的答案是:建立工業級的數據收集基礎設施 。 GEN-0 在一個前所未有的數據集上進行預訓練:270000 小時的真實世界操作軌跡 , 收集自全球數千個家庭、倉庫和工作場所 。 這個數據規模比目前公開的最大機器人數據集大了好幾個數量級 。
(來源:Generalist AI)
二十七萬小時的數據意味著什么?如果一個機器人一周工作七天、每天二十四小時不間斷運行 , 也需要超過三年才能積累這么多經驗 。 Generalist AI 通過在全球范圍內部署數千個數據收集設備和機器人 , 實現了并行化的數據獲取 。
團隊甚至為此鋪設了專用網絡線路 , 以支持從各個站點到云端的高帶寬數據上傳 。 在訓練端 , 他們動用了數萬個核心進行持續的多模態數據處理 , 壓縮了數十 PB 的原始數據 , 使得訓練系統每天能夠消化相當于 6.85 年的真實世界操作經驗 。
但規模只是一方面 , 質量與多樣性同樣關鍵 。 團隊進行了大規模的消融實驗 , 對比了來自不同數據源和收集策略的預訓練數據集對模型性能的影響 。 他們將數據分為三類:Class 1 是針對特定任務的演示數據 , Class 3 是“什么都做”的開放式數據 , Class 2 介于兩者之間 。 實驗結果顯示 , 不同數據混合會導致模型呈現出不同的特性 。
一些數據配置訓練出的模型在預測誤差和反向 KL 散度上都較低 , 這類模型更適合后續的監督微調 。 而另一些數據配置雖然預測誤差較高 , 但反向 KL 散度低 , 表明模型的輸出分布具有更高的多模態性 , 這對強化學習后訓練更有利 。
這些發現對數據收集策略有直接指導意義 。 Generalist AI 與多家“數據鑄造廠”(data foundry)合作 , 在不同環境中采集數據 。 通過持續的 A/B 測試 , 他們可以評估各個合作伙伴的數據質量 , 并據此調整數據采購比例 。
在博文附帶的可視化工具中 , 研究人員展示了一個內部開發的數據探索系統 。 用戶可以輸入文本描述 , 系統會在預訓練數據集的語義嵌入空間中定位到相關區域 , 并隨機采樣展示相關視頻片段 。 這個工具不僅用于數據質量檢查 , 也幫助團隊理解“操作的宇宙”究竟包含哪些任務類型 。 從削土豆到穿針引線 , 從在面包店打包食品到在洗衣房整理衣物 , GEN-0 的訓練數據試圖覆蓋人類日常操作的全部光譜 。
“讓通用機器人成為現實”
Generalist AI 由三位來自 Google Deepmind 和波士頓動力的資深研究員成立 。 Pete Florence、Andy Zeng 和 Andrew Barry 雖然學術背景各異 , 但研究軌跡在過去幾年中逐漸交匯 , 最終聚焦于讓機器人學習像大語言模型那樣規模化 。
Pete Florence 在麻省理工學院攻讀博士期間專注于視覺引導的操作 , 提出了 Dense Object Nets 等開創性工作 , 強調從原始感知到動作的端到端學習 。 加入 Google 后 , 他迅速轉向大模型與機器人的融合 , 參與了 RT-2、PaLM-E、Code as Policies 等多個項目 , 探索用統一的大模型框架處理感知、理解和控制 。
圖丨 Pete Florence(來源:Pete Florence)
Andy Zeng 則從機器人抓取和物體理解起步 。 他的代表作 TossingBot(一個能自主學習投擲不同物體的系統)曾獲得了 RSS 2019 最佳系統論文獎提名 。 在 Google 期間 , Andy 與 Pete 密切合作 , 聯合發表了超過十七篇論文 , 研究覆蓋從低層操作控制到高層語言推理的全鏈路問題 。
Andrew Barry 帶來了硬件與系統集成的經驗 。 他在 MIT 期間專注于高速自主無人機導航 , 畢業后在波士頓動力工作了五年 , 參與 Spot 機器狗的機械臂項目研發 。
三人見證了具身智能研究從分散突破走向系統化的過程 , 自大模型被引入機器人領域后 , 他們愈發認為創造通用機器人的時機在逐漸成熟 , 而真正需要的是重新關注數據、模型和硬件的交匯點 。 單靠從互聯網上下載任何數據 , 都無法創造出能夠與物理世界交互的快速、流暢、精確、反應靈敏的智能層 。 出于這一共識 , 他們決定成立 Generalist AI 。 而他們的目標就是“讓通用機器人成為現實 。 ”
正如團隊在博客中指出的 , GEN-0 或許標志著一個新時代的開始:具身基礎模型的能力可以通過物理交互數據可預測地擴展 。
不過 , 這項工作也留下了許多待解答的問題 。 Generalist AI 尚未公開 GEN-0 模型的架構細節、訓練算法或代碼 。 Harmonic Reasoning 的具體實現方式也仍然未知 。 數據收集的具體方法、質量控制流程、標注策略等關鍵細節也未披露 。 此外 , 雖然團隊展示了一些表現出色的演示視頻 , 但沒有提供系統的成功率統計或與其他方法的詳細對比 , 這使得很難準確評估模型的實際性能水平 。
但無論如何 , GEN-0 證明 , 通過持續擴大模型規模和高質量物理交互數據 , 機器人智能可以遵循與語言模型類似但又獨特的發展軌跡 。 Moravec 悖論提醒我們 , 物理智能的激活閾值更高 , 但 GEN-0 證明了這個閾值是可以跨越的 。
參考資料:
1.https://generalistai.com/blog/nov-04-2025-GEN-0
2.https://x.com/GeneralistAI/status/1985742083806937218
運營/排版:何晨龍
推薦閱讀














- Mate70Air配置匯總及真機上手!能用的“超薄”機?
- Juniper Research:電信業正迎來前所未有的重要拐點
- 小米手機被當成國禮送出 姚洋:透出中國的科技自信
- 史上最強Neo!iQOO Neo11開售2小時銷量超前代全天
- 自己家的雙11,釘釘AI表格殺瘋了
- 從掃街榜到Robotaxi,空間智能徹底打開了高德的想象空間
- 浪潮信息劉軍:速度就是金錢,AI超節點的核心是Token交互速度!
- 性價比第一的手機,7410mAh+324W+金屬框+IP68,有點香啊
- 雙11換手機買對不買貴,值得“閉眼買”的一款手機,512G低價高配
- 辦公游戲雙全能!飛利浦275S9LRB顯示器為何成職場人的優選