
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
臨床診斷并非一次性的「快照」 , 而是一場動態(tài)交互、不斷「探案」的推理過程 。 然而 , 當(dāng)下的大模型大多基于靜態(tài)數(shù)據(jù)訓(xùn)練 , 難以掌握真實(shí)診療中充滿不確定性的多輪決策軌跡 。 如何讓AI學(xué)會「追問」、選擇檢查 , 并一步步抽絲剝繭 , 邁向正確診斷?
來自上海交通大學(xué)人工智能學(xué)院、上海人工智能實(shí)驗(yàn)室、螞蟻集團(tuán)與北京大學(xué)的聯(lián)合團(tuán)隊(duì)提出了全新的「環(huán)境—智能體」訓(xùn)練框架 。 他們構(gòu)建了面向醫(yī)學(xué)診斷的世界模型 DiagGym , 并在其中訓(xùn)練可自主演進(jìn)的診斷智能體 DiagAgent 。 在該框架中 , 診斷智能體可以在安全可控的虛擬世界中反復(fù)探索 , 通過與虛擬病人的交互反饋持續(xù)優(yōu)化自身的動態(tài)決策策略 。
研究團(tuán)隊(duì)還設(shè)計(jì)了聚焦診斷推理過程的評測基準(zhǔn) DiagBench 。 該基準(zhǔn)共包含 750 個(gè)病例 , 提供了經(jīng)醫(yī)生驗(yàn)證的中間檢查推薦和最終診斷結(jié)果;其中有 99 個(gè)病例 , 另外由醫(yī)生手工撰寫了 973 條關(guān)于診斷過程的詳細(xì)評估準(zhǔn)則 。 在 DiagBench 上的實(shí)驗(yàn)結(jié)果顯示 , 該框架下訓(xùn)練得到的診斷智能體在 DiagAgent 多輪診斷流程管理能力方面 , 顯著優(yōu)于 DeepSeek、Claude-4 等先進(jìn)模型 。
代碼、模型、測試數(shù)據(jù)均已全部開源 。
- 論文標(biāo)題:Evolving Diagnostic Agents in a Virtual Clinical Environment
- 論文鏈接:https://arxiv.org/abs/2510.24654
- 代碼倉庫:https://github.com/MAGIC-AI4Med/DiagGym
從靜態(tài)問答到動態(tài)決策 ,
AI 診斷需要主動問詢
真實(shí)的臨床診斷是一個(gè)復(fù)雜的多輪決策過程:醫(yī)生需要根據(jù)不完整的初步信息 , 提出一系列可能的鑒別診斷 , 然后主動選取、推薦一系列的檢驗(yàn)檢查「軌跡」來逐步排除或確認(rèn) , 最終在信息充足時(shí)做出診斷 。
然而 , 當(dāng)前多數(shù)醫(yī)療 LLM 的訓(xùn)練范式更像是在做「開卷考試」——它們基于靜態(tài)、完整的病歷數(shù)據(jù)進(jìn)行指令微調(diào) 。 這種模式忽略了診斷過程中的交互性和長期策略性 , 導(dǎo)致模型難以處理真實(shí)診療中的三大核心挑戰(zhàn):
- 主動探索:如何主動選擇下一步檢查?
- 動態(tài)調(diào)整:如何根據(jù)新的檢查結(jié)果更新診斷假設(shè)?
- 適時(shí)收斂:何時(shí)應(yīng)該停止檢查并給出最終診斷?
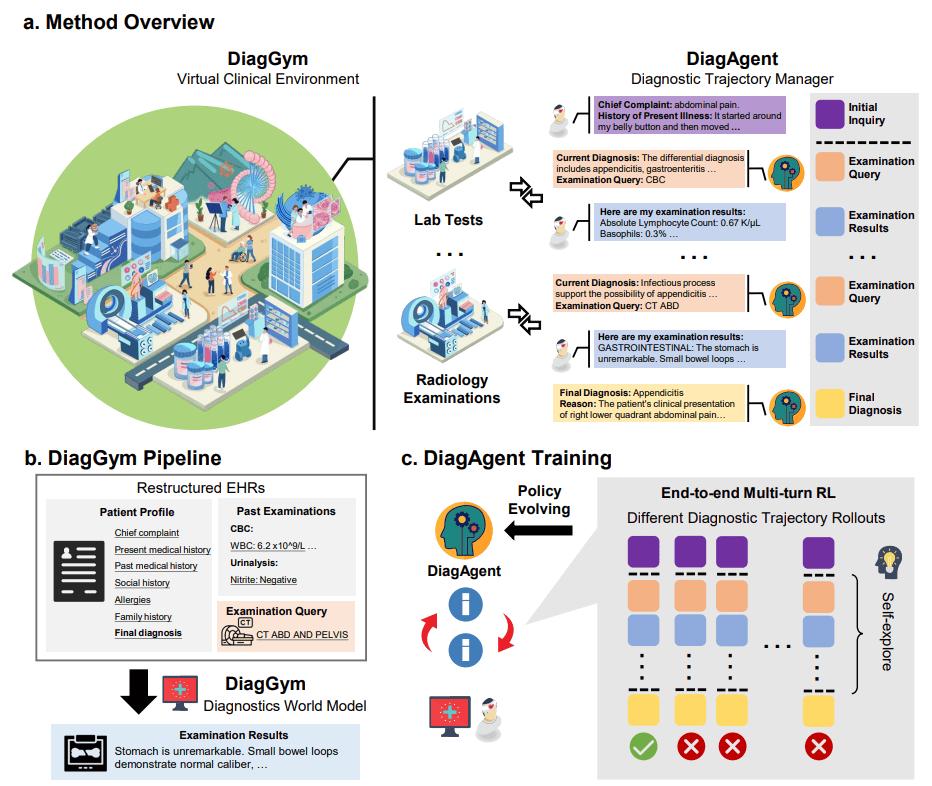
圖1. 端到端的診斷智能體訓(xùn)練范式
核心貢獻(xiàn):
虛擬臨床環(huán)境、診斷智能體
與基于 Rubric 的評測基準(zhǔn)
這項(xiàng)工作的核心貢獻(xiàn)可以概括為三個(gè)環(huán)環(huán)相扣的部分:
虛擬臨床環(huán)境:構(gòu)建醫(yī)學(xué)診斷的世界模型 DiagGym
研究團(tuán)隊(duì)基于海量真實(shí)電子病歷(EHR)訓(xùn)練了一個(gè)條件生成模型 。 這個(gè)模型可以根據(jù)患者的初始情況和已有的檢查記錄 , 實(shí)時(shí)生成「下一項(xiàng)檢查的結(jié)果」 。 它構(gòu)建了一個(gè)低成本、安全、可復(fù)現(xiàn)的閉環(huán)虛擬臨床環(huán)境 , 為智能體的交互式訓(xùn)練提供了完美沙盒 。 更重要的是 , 這個(gè)環(huán)境兼具高保真度與高多樣性 , 能模擬從典型到罕見的各種診療路徑 。
主動問詢能力:端到端診斷智能體自主演進(jìn) DiagAgent
在上述的虛擬環(huán)境中 , DiagAgent 通過端到端強(qiáng)化學(xué)習(xí)進(jìn)行訓(xùn)練 。 智能體需要學(xué)習(xí)在每個(gè)決策點(diǎn)做出最優(yōu)選擇——是繼續(xù)建議檢查 , 還是給出最終診斷 , 不斷同診斷學(xué)世界模型進(jìn)行交互 , 獲得當(dāng)前病人信息 。 其目標(biāo)是學(xué)會通過動態(tài)決策 , 主動進(jìn)行檢查推薦 , 并在信息足夠時(shí)做出診斷 , 從而實(shí)現(xiàn)高效動態(tài)問診 。
診斷過程化評測基準(zhǔn):人工檢驗(yàn)診斷軌跡規(guī)范性 DiagBench
為了全面評估診斷智能體的能力 , 團(tuán)隊(duì)構(gòu)建了 DiagBench 。 它不僅包含 750 個(gè)經(jīng)人工檢查的帶有參考診斷路徑的案例 , 更創(chuàng)新性地引入了由醫(yī)生撰寫的 973 條診斷過程評估準(zhǔn)則(rubrics) 。 這些準(zhǔn)則帶有權(quán)重 , 可以細(xì)粒度地評估診斷交互過程的合規(guī)性與質(zhì)量 , 強(qiáng)調(diào)「如何達(dá)成診斷」的過程 , 而不僅僅是「診斷結(jié)果是否正確」 。
實(shí)驗(yàn)結(jié)果顯示 , 無論是在單步?jīng)Q策場景 , 還是在端到端多步診斷決策場景 , 經(jīng)過強(qiáng)化學(xué)習(xí)訓(xùn)練的 DiagAgent 均顯著優(yōu)于包括 GPT4o、DeepSeekv3 在內(nèi)的 10 個(gè)代表性大模型 , 以及兩種主流智能體框架 。 這一結(jié)果表明 , 在交互式環(huán)境中進(jìn)行策略學(xué)習(xí) , 能夠賦予模型更強(qiáng)的動態(tài)決策與長期診斷管理能力 。
技術(shù)框架:
訓(xùn)練診斷學(xué)世界模型與端到端
交互式診斷智能體強(qiáng)化學(xué)習(xí)自主演進(jìn)
第一步:DiagGym , 構(gòu)建可交互的診斷世界模型 , 打造虛擬臨床環(huán)境
首先 , 團(tuán)隊(duì)需要一個(gè)能模擬真實(shí)臨床反饋的「沙盒」 。 他們收集了超過 11 萬份患者的真實(shí)診療數(shù)據(jù) , 覆蓋近 5000 種疾病 。 這些數(shù)據(jù)包含了患者基本信息以及按時(shí)間排序的檢查序列(如化驗(yàn)、影像等) 。
【上交×螞蟻發(fā)布 DiagGym:以世界模型驅(qū)動交互式醫(yī)學(xué)診斷智能體】利用這些數(shù)據(jù) , 團(tuán)隊(duì)訓(xùn)練了一個(gè)自回歸語言模型 。 這個(gè)模型的核心能力是條件性文本生成:給定患者基本信息和歷史檢查記錄 , 它能精準(zhǔn)預(yù)測下一項(xiàng)檢查可能出現(xiàn)的結(jié)果 。 這個(gè)模型就是 DiagGym , 一個(gè)能夠?qū)崟r(shí)模擬檢查反饋的診斷學(xué)世界模型 。
圖2:基于臨床序列數(shù)據(jù)的 DiagGym 自回歸語言模型訓(xùn)練范式
第二步:DiagAgent , 端到端強(qiáng)化學(xué)習(xí)驅(qū)動 , 讓診斷智能體自主演進(jìn)
有了「虛擬臨床環(huán)境」 , 就可以開始訓(xùn)練「診斷智能體」了 。 DiagAgent 的訓(xùn)練分為兩個(gè)階段:
- 冷啟動(Supervised Fine-Tuning):首先 , 使用 1000 條從真實(shí)病歷中抽取的診斷互動軌跡進(jìn)行監(jiān)督微調(diào) , 讓模型學(xué)會基本的交互格式和臨床語言 。
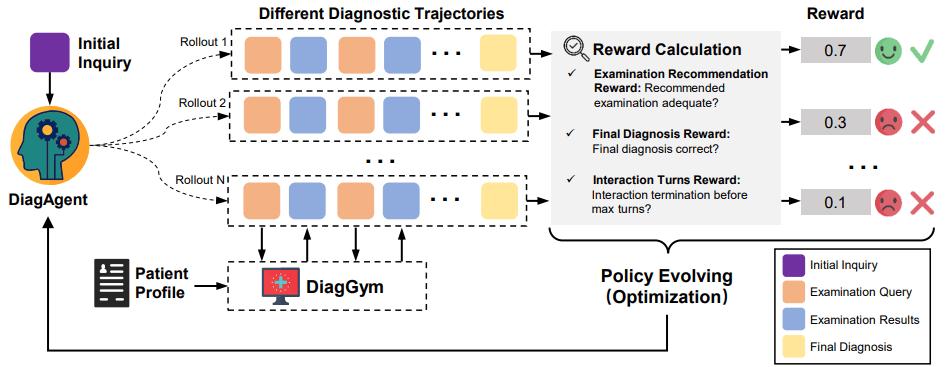
- 強(qiáng)化學(xué)習(xí)(Reinforcement Learning):接著 , 將智能體放入 DiagGym 中進(jìn)行多輪實(shí)戰(zhàn)演練 。 智能體在環(huán)境中自主決策 , 獲得環(huán)境反饋 , 并根據(jù)最終的獎(jiǎng)勵(lì)進(jìn)行策略優(yōu)化 。
- 診斷正確性:最終診斷是否準(zhǔn)確?
- 檢查推薦質(zhì)量:推薦的檢查是否關(guān)鍵、有效?(通過 F1 分?jǐn)?shù)衡量)
- 交互輪數(shù)懲罰:是否用最少的步驟完成診斷?(鼓勵(lì)高效)
圖3:采用強(qiáng)化學(xué)習(xí)驅(qū)動的DiagAgent策略演進(jìn)的訓(xùn)練架構(gòu)
第三步:DiagBench , 手工打造規(guī)則驅(qū)動新評測基準(zhǔn) , 評估AI診斷交互能力
在評估診斷性能方面 , 不僅需要模型能給出正確答案 , 更要能展示出嚴(yán)謹(jǐn)?shù)脑\斷思路 。 但如何衡量這個(gè)「思路」呢?傳統(tǒng)的自動化指標(biāo)顯然不夠 。
為此 , 研究團(tuán)隊(duì)打造了一套全新的手工打造規(guī)則驅(qū)動的評測基準(zhǔn)——DiagBench , 旨在深入評估AI在多輪診斷交互中的過程質(zhì)量 。 具體步驟如下:
- 醫(yī)生驗(yàn)證的高質(zhì)量案例庫:基準(zhǔn)包含了 750 個(gè)經(jīng)過醫(yī)生團(tuán)隊(duì)逐一驗(yàn)證的真實(shí)診斷案例 , 每個(gè)案例都附有標(biāo)準(zhǔn)的參考診斷路徑和最終結(jié)果 。
- 手工打造的核心評估準(zhǔn)則(Rubrics):研究團(tuán)隊(duì)還引入了一套由資深醫(yī)生手工打造的、基于規(guī)則的評估體系 。 研究團(tuán)隊(duì)邀請多位醫(yī)生 , 對 99 個(gè)復(fù)雜病例進(jìn)行深度復(fù)盤 , 將診斷過程中的關(guān)鍵決策點(diǎn)、推理邏輯、以及必須遵守的臨床準(zhǔn)則 , 提煉成 973 條具體的評估細(xì)則(Rubrics) 。
- 帶權(quán)重的精細(xì)化打分:在此基礎(chǔ)上 , 醫(yī)生還為每一條準(zhǔn)則都附上權(quán)重 , 以區(qū)分其臨床重要性 。
實(shí)驗(yàn)結(jié)果:
虛擬環(huán)境與智能體的雙重驗(yàn)證
DiagGym:虛擬環(huán)境有多真實(shí)?
一個(gè)可靠的虛擬環(huán)境是成功訓(xùn)練智能體的前提 。 實(shí)驗(yàn)證明 , DiagGym在多個(gè)維度上都表現(xiàn)出色:
- 高保真度:DiagGym 在逐步生成檢查結(jié)果時(shí)展現(xiàn)出卓越性能 。 如表 1 所示 , 在逐步生成檢查結(jié)果時(shí) , 其步驟相似度(3.57/5分)和整鏈一致性(96.9%)均遠(yuǎn)超 Qwen2.5-72B 等強(qiáng)基線模型 。 更關(guān)鍵的是 , 根據(jù)醫(yī)生評測結(jié)果(表2) , DiagGym 同樣大幅領(lǐng)先 , 其生成的報(bào)告獲得了 4.49 分的平均相似度和 95.00% 的多數(shù)投票一致性 , 這證明 DiagGym 的結(jié)果更連貫 , 更少出現(xiàn)與病情矛盾的「過度陽性」結(jié)果 , 臨床可信度高 。
- 高多樣性:生成的檢查結(jié)果分布與真實(shí)數(shù)據(jù)高度對齊 。 如表1所示 , 數(shù)值型 1-Wasserstein 距離僅 0.128 , 同時(shí)保持了接近真實(shí)數(shù)據(jù)的多樣性 , 有效避免了模型模式崩潰 。
- 高效率:DiagGym 的部署和推理成本極低 。 表 1 數(shù)據(jù)顯示 , 它僅需單卡 A100 即可部署 , 單次生成僅耗時(shí)約 0.52 GPU·s , 而同類任務(wù)若使用 DeepSeek-v3-671B 則需要至少 16 張GPU和超過 62 GPU·s 的算力 。 這為大規(guī)模、高頻次的智能體交互訓(xùn)練提供了可能 。
表1:DiagGym 與基線模型的定量評測結(jié)果 。
表2:DiagGym 與基線模型生成結(jié)果的臨床專家主觀評測結(jié)果 。
DiagAgent:診斷智能體的「醫(yī)術(shù)」如何?
1、單輪能力評測:決策精準(zhǔn)度大幅提升
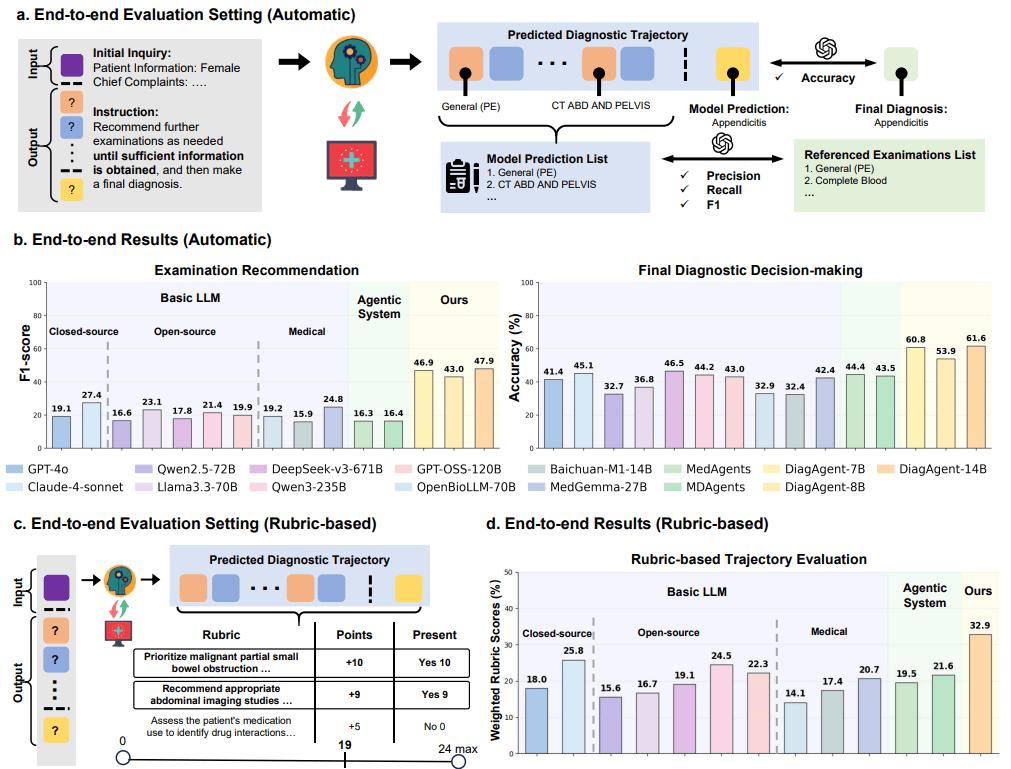
在單輪能力評測中 , 如圖 4a 所示 , 我們評估了智能體在給定部分病歷、僅需做出下一步?jīng)Q策的能力 。 結(jié)果證明 , DiagAgent 在這種單輪決策場景下展現(xiàn)了壓倒性優(yōu)勢(結(jié)果見圖 4c)
- 檢查推薦命中率提升 44.03% , 最終診斷準(zhǔn)確率提升 9.34%(相較于次優(yōu)模型) 。
- DiagAgent-7B 的檢查推薦命中率高達(dá) 72.56% , 而 MedGemma 和 DeepSeek-v3 等強(qiáng)模型僅為 20%-28% 。
圖4:DiagAgent在單輪決策場景下的評估框架與性能對比 。
2、端到端全程診斷評測:過程與結(jié)果雙優(yōu)
在模擬真實(shí)診療、從頭到尾完成診斷的全流程測試中 , 如圖5a 所示 , 模型需要根據(jù)患者信息進(jìn)行多輪問診 , 最終給出診斷 。 DiagAgent 在這一復(fù)雜任務(wù)中再次表現(xiàn)最佳:
- 核心診斷指標(biāo)全面領(lǐng)先 。 如圖 5b 所示 , DiagAgent-14B 平均交互 6.66 輪 , 檢查推薦F1分?jǐn)?shù)達(dá)到 46.59% , 最終診斷準(zhǔn)確率 61.27% , 均遠(yuǎn)超其他模型 。 相比之下 , 許多大模型基線(如 DeepSeek-v3)傾向于在 2-4 輪內(nèi)草草結(jié)束 , 導(dǎo)致檢查不充分(Recall 較低) , 診斷準(zhǔn)確性也大打折扣 。
- 過程質(zhì)量獲臨床準(zhǔn)則認(rèn)可 。 我們進(jìn)一步引入醫(yī)生制定的流程化準(zhǔn)則(rubrics)進(jìn)行評估(如圖5c 所示) 。 在圖5d的加權(quán)得分對比中 , DiagAgent-14B的得分比強(qiáng)基線(如Claude-sonnet-4)高出7-8個(gè)百分點(diǎn) 。 這說明它不僅「診斷對」 , 而且「過程好」 , 更好地遵循了關(guān)鍵檢查優(yōu)先、基于證據(jù)收斂等臨床金標(biāo)準(zhǔn) 。
圖5:DiagAgent端到端全程診斷評測框架與結(jié)果 。
消融實(shí)驗(yàn):
訓(xùn)練虛擬環(huán)境支撐強(qiáng)化學(xué)習(xí)
比簡單利用現(xiàn)有樣本進(jìn)行SFT更加高效
框架的成功并非偶然 。 通過一系列消融實(shí)驗(yàn) , 我們深入探究了DiagAgent 成功的關(guān)鍵因素 。 我們的消融實(shí)驗(yàn)結(jié)果如表3所示:
- 強(qiáng)化學(xué)習(xí)(RL)顯著優(yōu)于監(jiān)督微調(diào)(SFT):在同等模型規(guī)模下 , 由DiagGym 虛擬環(huán)境支撐的強(qiáng)化學(xué)習(xí)策略 , 普遍為模型帶來 10 至 15 個(gè)百分點(diǎn)以上的診斷準(zhǔn)確率增益 。
- 獎(jiǎng)勵(lì)設(shè)計(jì)是策略優(yōu)化的核心:同時(shí)優(yōu)化「診斷準(zhǔn)確性」和「檢查推薦質(zhì)量」的雙重獎(jiǎng)勵(lì) , 能讓模型在提升最終準(zhǔn)確率的同時(shí) , 大幅改善診斷路徑的合理性 。
- 強(qiáng)基座模型潛力更大:雖然所有模型都能從RL中獲益 , 但更強(qiáng)的基座模型(如Qwen2.5-14B)能達(dá)到更高的性能上限 。
表3:消融實(shí)驗(yàn)結(jié)果
研究價(jià)值與未來展望
研究價(jià)值
對齊真實(shí)臨床工作流:它將AI診斷從靜態(tài)問答升級為動態(tài)策略學(xué)習(xí) , 讓智能體學(xué)會在不確定性下「主動搜證-評估-收斂」 , 更貼近真實(shí)世界 。
開創(chuàng)「環(huán)境-智能體」閉環(huán)訓(xùn)練范式:DiagGym作為一個(gè)診斷學(xué)世界模型 , 提供了一個(gè)安全、可擴(kuò)展的診斷智能體「訓(xùn)練場」 , 讓智能體系統(tǒng)能自主探索海量診療路徑 , 包括各種非典型的診斷交互軌跡 , 擺脫了舊有監(jiān)督學(xué)習(xí)范式對收集有限、保守的診斷過程數(shù)據(jù)的依賴 。
推動過程化評估:DiagBench首次在診斷交互軌跡上引入了帶權(quán)重的rubrics來衡量「診斷過程」的質(zhì)量 , 推動診斷AI的開發(fā)從「唯結(jié)果論」轉(zhuǎn)向關(guān)注中間決策的合理性 。
局限與展望
模型規(guī)模:當(dāng)前實(shí)驗(yàn)主要基于7B-14B模型 , 未來擴(kuò)展到千億級模型有望進(jìn)一步提升策略的深度和推理的上限 。
任務(wù)范圍:目前聚焦于「診斷」 , 未來可將「治療方案、預(yù)后評估」等環(huán)節(jié)納入虛擬環(huán)境和獎(jiǎng)勵(lì)函數(shù) , 構(gòu)建「診療一體化」的超級智能體 。
環(huán)境擴(kuò)展:DiagGym未來可以加入更多維度的模擬 , 如治療反饋、費(fèi)用/安全約束等 , 構(gòu)建一個(gè)更全面的虛擬臨床系統(tǒng) 。
總結(jié)
這項(xiàng)工作通過「虛擬臨床環(huán)境+端到端強(qiáng)化學(xué)習(xí)」的范式 , 成功地將 LLM 從一個(gè)靜態(tài)的「問答引擎」轉(zhuǎn)變?yōu)橐粋€(gè)能夠進(jìn)行「長期、多輪」診斷管理的「AI醫(yī)生」 。 高保真、低成本的世界模型DiagGym為訓(xùn)練提供了沃土 , 而智能體DiagAgent則在其中學(xué)會了動態(tài)決策的藝術(shù) , 在各項(xiàng)評測中全面領(lǐng)先 。
推薦閱讀













- NuerIPS唯一滿分論文曝光,來自清華上交
- iPhone Air 2 突然反轉(zhuǎn),發(fā)布時(shí)間改了
- 智元上緯發(fā)布機(jī)器人預(yù)熱海報(bào),展示人形與四足可變形態(tài)新品
- 根本不急!曝英偉達(dá)RTX 50 SUPER系列顯卡發(fā)布時(shí)間仍待定
- 榮耀 500 系列將于月底發(fā)布
- 突破AI產(chǎn)業(yè)落地卡點(diǎn),螞蟻韋韜:數(shù)據(jù)是變革關(guān)鍵
- OPPO新機(jī)官宣:11月17日,正式發(fā)布
- 為什么感覺小鵬機(jī)器人一發(fā)布就是宇樹科技無法達(dá)到的高度?
- 測試智算性能!新一期國際排行榜AIPerf發(fā)布
- 大廠AI新戰(zhàn)場:AQ狂飆,螞蟻押注大健康賽道