
文章圖片

文章圖片
【Nano Banana,OpenAI你學(xué)不會】
文章圖片

文章圖片
文章圖片
奧特曼向OpenAI的全體員工發(fā)了一封內(nèi)部信 , 他坦言道 , 雖然OpenAI仍處于領(lǐng)先地位 , 但是谷歌正在縮短差距 。 并奧特曼也承認(rèn) , 正是由于谷歌最近一系列的產(chǎn)品發(fā)布 , 為OpenAI帶來了不小的壓力 。
事實(shí)也正如奧特曼所言 , 谷歌這次帶來的 , 除了贏得滿堂彩的Gemini 3 Pro , 還有讓整個(gè)AIGC圈震撼的Nano Banana Pro 。 在此之前 , 所有生圖模型的底層邏輯都是臨摹世界 。 通過海量的數(shù)據(jù)庫 , 尋找最接近描述的圖 , 將其拼湊給你 。
而Nano Banana Pro的出現(xiàn) , 則徹底打破了這個(gè)規(guī)則 。 它并不是在“畫圖” , 而是在“模擬物理世界” 。 其最大的突破在于 , 引入了思維鏈(Chain of Thought)推理機(jī)制 , 先讓模型進(jìn)行思考 , 再去畫圖 。
在落下第一個(gè)像素之前 , 模型會先在潛空間內(nèi)進(jìn)行邏輯推演 , 計(jì)算物體的數(shù)量、確定光影的投射角度、規(guī)劃空間嵌套關(guān)系 。 它不再依賴文本作為中轉(zhuǎn)站 , 推理結(jié)果直接以高維向量的形式指導(dǎo)像素生成 。
那么問題來了 , 為什么OpenAI開發(fā)不出Nano Banana Pro?
01
在回答問題之前 , 不妨先看看Nano Banana Pro , 它和OpenAI現(xiàn)在生圖主要使用的GPT-4o到底有何區(qū)別 。
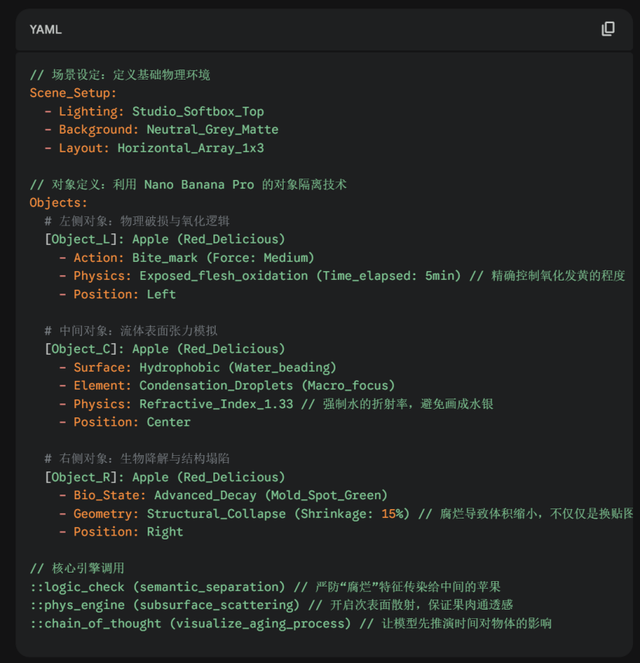
以“三個(gè)蘋果”的生成任務(wù)為例 , 提示詞為:“左側(cè)蘋果帶有咬痕 , 中間蘋果附著水珠 , 右側(cè)蘋果呈現(xiàn)腐爛狀態(tài)” 。 面對這一指令 , GPT-4o通常會迅速生成一張色彩明艷、構(gòu)圖完美的圖像 。
但在細(xì)節(jié)核驗(yàn)時(shí)往往暴露出概率生成的缺陷 , 中間蘋果上面的水珠其排布不符合客觀規(guī)律 , 而右邊蘋果的腐爛看起來又過于刻意 。
相比之下 , Nano Banana Pro輸出的圖像不僅數(shù)量精確 , 且每個(gè)對象的屬性都嚴(yán)格對應(yīng)——左側(cè)的缺口、中間的折射光感、右側(cè)的氧化紋理 , 均被精準(zhǔn)還原 。
這種表象差異的背后 , 是兩條截然不同的技術(shù)路徑 。
GPT-4o的生成機(jī)制本質(zhì)上基于統(tǒng)計(jì)學(xué)相關(guān)性 , 它在海量訓(xùn)練數(shù)據(jù)中檢索“蘋果+咬痕”的視覺特征 , 并通過概率分布進(jìn)行拼貼與融合 。 它并未真正理解“三個(gè)”的數(shù)量概念 , 也未構(gòu)建“腐爛”的物理模型 , 僅是根據(jù)高維空間中的特征距離進(jìn)行近似匹配 。
而Nano Banana Pro引入了思維鏈(Chain-of-Thought CoT)機(jī)制 , 將圖像生成過程從單純的“像素預(yù)測”升級為“邏輯推演” 。 在落下第一個(gè)像素前 , 模型內(nèi)部已完成了一輪符號化的規(guī)劃:首先確立實(shí)體對象(Object 1 2 3) , 隨即分配空間坐標(biāo) , 最后綁定物理屬性 。
針對“咬痕” , 它推演的是幾何形態(tài)的改變;針對“水珠” , 它計(jì)算的是光學(xué)反射與折射的物理規(guī)律;針對“腐爛” , 它模擬的是材質(zhì)屬性的演變 。 這是一套從語義理解到邏輯規(guī)劃 , 再到執(zhí)行生成的全鏈路閉環(huán) 。
這種機(jī)制在處理涉及物理規(guī)律的復(fù)雜場景時(shí)優(yōu)勢尤為凸顯 。
提示詞“窗臺上的半杯水 , 陽光從左側(cè)射入” 。
GPT-4o所生成的圖片 , 僅0具備視覺合理性 , 但在物理上自相矛盾的光影關(guān)系 。 此時(shí) , 窗臺左側(cè)應(yīng)存在由玻璃杯反射出來的陽光 , 但是圖片中僅存在右側(cè)折射出來的光線 。
而具Nano Banana Pro會先行計(jì)算光源向量 , 推導(dǎo)陰影投射方向以及液體介質(zhì)的光線折射率 。 這種基于物理常識的推理 , 使得生成結(jié)果不再是視覺元素的堆砌 , 而是對物理世界的數(shù)字模擬 。
更為深層的架構(gòu)差異在于 , OpenAI目前的體系存在顯著的“文本信息瓶頸”(Text Information Bottleneck) 。 在ChatGPT中調(diào)用繪圖功能時(shí) , 用戶的簡短指令往往會被GPT改寫為一段詳盡的Prompt , 再傳遞給圖片生成模型 。
這一過程看似豐富了細(xì)節(jié) , 實(shí)則引入了噪聲 。 文本作為一維的線性信息載體 , 在描述三維空間關(guān)系、拓?fù)浣Y(jié)構(gòu)及復(fù)雜的物體屬性綁定時(shí) , 存在天然的低帶寬缺陷 。 改寫過程極易導(dǎo)致原始意圖中的關(guān)鍵約束被修飾性語言淹沒 , 造成信息的有損傳輸 。
此外 , 漢字對于圖片生成大模型來說也是一個(gè)噩夢 。 GPT-4o在很長時(shí)間里 , 寫字都是“亂碼生成器” , 甚至讓它寫“OpenAI” , 它都能寫成“OpanAl”或者一堆奇怪的符號 。
我讓GPT-4o以字母榜LOGO為參考 , 生成一個(gè)字母榜的招牌 。
但Nano Banana Pro實(shí)現(xiàn)了對文字的精準(zhǔn)控制 。 在同樣的提示詞下 , Nano Banana Pro提取出了上方的字母榜 , 左右兩側(cè)的A和Z , 以及最下方的弧線 , 并將這些元素置于不同的圖層、不同的材質(zhì) 。
Nano Banana Pro則采用了原生多模態(tài)(Native Multimodal)架構(gòu) , 這是一種統(tǒng)一模型的解決方案 。
用戶的輸入在模型內(nèi)部直接映射為包含語義、空間及物理屬性的高維向量 , 無需經(jīng)過“文本-圖像”的轉(zhuǎn)譯中介 。 這種端到端的映射關(guān)系 , 如同建筑師直接依據(jù)藍(lán)圖施工 , 而非依賴翻譯人員的口述傳達(dá) , 從而根除了中間環(huán)節(jié)的信息熵增 。
但這也造成了另外一個(gè)問題 , 提示詞門檻被拉高了 。 我們回到一開始三個(gè)蘋果的提示詞上 。
這是輸入給GPT-4o的提示詞 , 簡單易懂 , 就是在描述畫面構(gòu)成 。
而這是給Nano Banana Pro的提示詞 。 看起來就像Python代碼一樣 , 通過函數(shù)和()來控制生成的圖片 。
在涉及計(jì)數(shù)、方位布局、多物體屬性綁定(Attribute Binding)等精確控制任務(wù)上 , Nano Banana Pro表現(xiàn)出色 。 它能清晰區(qū)分不同對象的屬性歸屬 , 避免了擴(kuò)散模型常見的“屬性泄露”問題(如將紅杯子的顏色錯(cuò)誤渲染到藍(lán)杯子上) 。
當(dāng)然 , GPT-4o依然保有其獨(dú)特的生態(tài)位 。 其優(yōu)勢在于推理速度與基于RLHF(人類反饋強(qiáng)化學(xué)習(xí))調(diào)優(yōu)后的審美直覺 。
由于剝離了復(fù)雜的邏輯推理環(huán)節(jié) , 其生成效率更高 , 且更能迎合大眾對高飽和度、戲劇化光影的視覺偏好 。 對于追求視覺沖擊力而非邏輯嚴(yán)謹(jǐn)性的通用場景 , GPT-4o依然是高效的選擇 。
然而 , 當(dāng)需求從“好看”轉(zhuǎn)向“準(zhǔn)確” , 從“相關(guān)性”轉(zhuǎn)向“因果性” , Nano Banana Pro所代表的“先思考、后執(zhí)行”模式便構(gòu)成了降維打擊 。 它犧牲了部分的生成速度與討好眼球的濾鏡感 , 換取了對物理邏輯的忠實(shí)還原 。
02
橘生淮南則為橘 , 生于淮北則為枳 。 Nano Banana Pro和GPT-4o之所以會有如此的差距 , 正是因?yàn)槠溟_發(fā)者 , 谷歌和OpenAI在AI這條路上 , 選擇兩種完全不同的發(fā)展方向 。
谷歌選擇的是“原生多模態(tài)”這條路 。
就是從模型訓(xùn)練的第一天起 , 文本、圖像、視頻、音頻就混在一起 , 扔進(jìn)同一個(gè)神經(jīng)網(wǎng)絡(luò)里讓它學(xué) 。 在Gemini的眼里 , 一這些事物本質(zhì)上沒有區(qū)別 , 都是數(shù)據(jù) 。 它不需要先把圖片翻譯成文字 , 再去理解文字 。
這就像一個(gè)人從小就會說中文、英文、法文 , 這三種語言在他腦子里是同時(shí)存在的 , 他不需要先把英文翻譯成中文再思考 。
而OpenAI走的是“模塊化拼接”這條路 。
它的邏輯是 , 讓專業(yè)的人做專業(yè)的事 。 GPT-5負(fù)責(zé)理解語言和邏輯推理 , GPT-4o負(fù)責(zé)生成圖像 , Whisper負(fù)責(zé)處理語音 。
每個(gè)模塊都做得很好 , 然后通過API把它們連起來 。 這就像一個(gè)團(tuán)隊(duì) , 有文案、有設(shè)計(jì)師、有程序員 , 大家各司其職 , 通過開會和文檔來協(xié)作 。
這兩種路線 , 沒有絕對的對錯(cuò) , 但會導(dǎo)致完全不同的結(jié)果 。
谷歌最大的優(yōu)勢 , 來自于YouTube 。 這是全世界最大的視頻庫 , 里面有幾十億小時(shí)的視頻內(nèi)容 。 這些視頻不是靜態(tài)的圖片 , 而是包含了時(shí)間序列、因果關(guān)系、物理變化的動態(tài)數(shù)據(jù) 。 Gemini從一開始就是“看這些視頻長大的” 。
換句話說 , Gemini從誕生之初 , 就理解物理世界的基本運(yùn)行邏輯 。 杯子掉在地上會摔碎 , 水倒進(jìn)杯子里會形成液面 。 這些東西不是靠文字描述學(xué)來的 , 而是通過看真實(shí)世界的視頻 , 自己總結(jié)出來的 。
所以當(dāng)你讓Nano Banana Pro畫“一個(gè)杯子從桌子上掉下來的瞬間” , 它不會畫出一個(gè)漂浮在空中、姿態(tài)僵硬的杯子 。 它會畫出杯子在下落過程中的傾斜角度 , 杯子里的水濺起來的形態(tài) , 甚至是杯子即將觸地時(shí)周圍空氣的擾動感 。 因?yàn)樗娺^太多這樣的場景 , 它知道真實(shí)世界是怎么運(yùn)作的 。
除了YouTube , 谷歌還有另一個(gè)護(hù)城河:OCR 。 谷歌做了幾十年的光學(xué)字符識別 , 從Books到Lens , 谷歌積累了全球最大的“圖片-文字”對齊數(shù)據(jù)庫 。 這直接導(dǎo)致了Gemini在文字渲染上的碾壓性優(yōu)勢 。
它知道漢字在圖片里應(yīng)該長什么樣 , 知道不同字體、不同大小、不同排列方式下 , 文字應(yīng)該怎么呈現(xiàn) 。 這也是為什么Nano Banana Pro能精準(zhǔn)識別漢字 。
反觀OpenAI , 它的起家靠的是文本 。 從GPT-1到GPT-3再到GPT-5 , 它在語言模型上一路狂奔 , 確實(shí)做到了世界頂級 。 但視覺能力是后來才加上去的 。
DALL-E早期是獨(dú)立發(fā)展的 , 訓(xùn)練數(shù)據(jù)主要來自網(wǎng)絡(luò)抓取的靜態(tài)圖片 , 來自Common Crawl這樣的數(shù)據(jù)集 。 這些圖片質(zhì)量參差不齊 , 而且都是靜態(tài)的 , 沒有時(shí)間維度 , 沒有物理過程 , 沒有因果關(guān)系 。
所以DALL-E學(xué)到的 , 更多是“這個(gè)東西大概長這樣” , 而不是“這個(gè)東西為什么長這樣”或者“這個(gè)東西會怎么變化” 。 它可以畫出一只很漂亮的貓 , 但它不理解貓的骨骼結(jié)構(gòu) , 不理解貓的肌肉如何運(yùn)動 , 不理解貓?jiān)谔S時(shí)身體會呈現(xiàn)什么姿態(tài) 。 它只是見過很多貓的照片 , 然后學(xué)會了“貓長這樣” 。
更關(guān)鍵的是訓(xùn)練方式的差異 。
正是因?yàn)镺penAI走的是RLHF路線 。 所以他們雇了大量的人類標(biāo)注員 , 給生成的圖片打分:“這張好看嗎?”“這張更符合要求嗎?”標(biāo)注員們在選擇的時(shí)候 , 自然而然會傾向于那些色彩鮮艷、構(gòu)圖完美、皮膚光滑、光影戲劇化的圖片 。
這導(dǎo)致GPT-4o被訓(xùn)練成了一個(gè)“討好型人格”的畫家 。 它學(xué)會了怎么畫出讓人眼前一亮的圖 , 學(xué)會了怎么用高對比度和飽和色來抓住眼球 , 學(xué)會了怎么把皮膚修得像瓷器一樣光滑 。 但代價(jià)是 , 它犧牲了物理真實(shí)感 。
GPT-4o生成的圖片 , 有一種很典型的“DALL-E濾鏡” 。 皮膚像涂了蠟 , 物體表面特別光滑 , 光影過度戲劇化 , 整體感覺就是“一眼假” 。 它不敢畫出皮膚上的毛孔 , 不敢畫出布料的褶皺 , 不敢畫出不完美的光照 。 因?yàn)樵谟?xùn)練過程中 , 那些帶有瑕疵的、粗糙的、不那么“美”的圖片 , 都被標(biāo)注員打了低分 。
而谷歌沒有走這條路 。 Gemini的訓(xùn)練更注重“真實(shí)”而不是“美” 。 世界本就如此 , 它沒有書本里描繪的那么美 。
03
那么谷歌又是如何追上OpenAI , 以至于讓奧特曼發(fā)內(nèi)部信來強(qiáng)調(diào)危機(jī)感的呢?
谷歌選擇在“準(zhǔn)確性”和“邏輯”上發(fā)力 。 谷歌將其稱為“Grounding” , 也就是“接地氣” , 也就是“真實(shí)性” 。
為了實(shí)現(xiàn)這個(gè)目標(biāo) , 谷歌把思考過程 , 引入了圖像生成過程 。 這個(gè)決策會大大增加計(jì)算成本 , 因?yàn)樵谏蓤D像的時(shí)候加入推理步驟 , 生成速度也就變慢了 。 但谷歌判斷這個(gè)代價(jià)是值得的 , 因?yàn)樗鼡Q來的是質(zhì)的提升 。
當(dāng)你給Nano Banana Pro一個(gè)提示詞 , 比如“畫一個(gè)廚房 , 左邊是冰箱 , 右邊是灶臺 , 中間的桌子上放著三個(gè)碗” , 模型不會直接開始畫 。 它會先啟動思維鏈:
首先 , 識別場景類型:廚房 。 然后 , 識別對象:冰箱、灶臺、桌子、碗 。 接著 , 確定空間關(guān)系:冰箱在左 , 灶臺在右 , 桌子在中間 。 再確定數(shù)量:三個(gè)碗 。 然后推理物理邏輯:廚房里通常會有什么光源?桌子應(yīng)該離冰箱和灶臺多遠(yuǎn)才合理?三個(gè)碗應(yīng)該怎么排列?最后 , 確定視角和構(gòu)圖:從什么角度看這個(gè)場景最合適?
這一整套思考完成后 , 模型會在內(nèi)部生成一些“思考圖像” , 這些圖像用戶看不到的 , 但它們幫助模型理清了思路 。 最后 , 模型才開始生成真正的輸出圖像 。
這個(gè)過程看起來復(fù)雜 , 但它解決了一個(gè)核心問題:讓模型“理解”而不是“猜測” 。
GPT-4o以及市面上絕大多數(shù)生成圖片的模型 , 都是靠概率猜 , “用戶說廚房 , 那我就把我見過的廚房元素拼起來 , 大概就對了 。 ”
而Nano Banana Pro則是真正去理解廚房這個(gè)概念:“用戶說廚房 , 廚房是用來洗菜做飯的 , 所以這個(gè)廚房需要滿足這些空間關(guān)系和物理邏輯 , 我要按照這個(gè)邏輯來構(gòu)建 。 ”
反觀OpenAI , 它目前的策略是把最強(qiáng)的推理能力集中在o1系列模型上 , 也就是之前代號為Strawberry的項(xiàng)目 。 o1在數(shù)學(xué)推理和代碼生成上確實(shí)很強(qiáng) , 它能解決一些人類數(shù)學(xué)家都覺得有挑戰(zhàn)的問題 , 能寫出復(fù)雜的算法代碼 。
至于圖像生成 , OpenAI的判斷是:目前GPT-4o的“直覺式”生成已經(jīng)足夠好了 , 足夠維持用戶體驗(yàn) , 足夠在市場上保持領(lǐng)先 , 并不需要繼續(xù)提升 。
還有一個(gè)因素是產(chǎn)品理念的差異 。 OpenAI一直強(qiáng)調(diào)的是PMF , 也就是Product-Market Fit , 產(chǎn)品市場契合度 。 它的策略是“快速迭代 , 快速驗(yàn)證” 。
DALL-E 3只要能通過提示詞和GPT-4拼起來用 , 那就先發(fā)布 , 先占領(lǐng)市場 。 后臺的架構(gòu)可以慢慢改 , 用戶看不見的地方可以慢慢優(yōu)化 。
這個(gè)市場策略被稱為“膠水科技” , 其最大的弊端在于積累的技術(shù)債太多了 。 當(dāng)你一開始選擇了模塊化拼接的架構(gòu) , 后面想要改成原生多模態(tài) , 就不是簡單地加幾行代碼的問題了 。 這可能需要重新訓(xùn)練整個(gè)模型 , 需要重新設(shè)計(jì)數(shù)據(jù)管道 , 需要重新構(gòu)建工具鏈 。
谷歌慢工出細(xì)活 , 可他們也有自己的難處 。
原生多模態(tài)模型的維護(hù)成本也更高 。 如果你想提升圖像生成能力 , 就需要調(diào)整整個(gè)模型 。 這就是為什么 , Nano Banana Pro只能伴隨著Gemini 3的更新 , 沒辦法自己單獨(dú)更新 。
這種“按下葫蘆浮起瓢”的問題 , 在模塊化架構(gòu)里就不存在 , 因?yàn)楫?dāng)你你只需要優(yōu)化圖像生成模塊 , 根本不用擔(dān)心影響到文本模塊 。
所以O(shè)penAI確實(shí)沒辦法訓(xùn)練出來Nano Banana Pro 。
然而這并不意味著谷歌可以高枕無憂了 , 因?yàn)锳I領(lǐng)域迭代速度太快了 。 我敢打賭 , 不出半個(gè)月 , 就會有一大幫生圖模型問世 , 直接對標(biāo)Nano Banana Pro 。
推薦閱讀








- 挖走多名AI工程師后 OpenAI又在從蘋果硬件團(tuán)隊(duì)大量挖人
- Nano Banana終于不是文盲了,但我可能會變「傻」
- 押注超級智能+聯(lián)手富士康 OpenAI多重舉措應(yīng)對谷歌壓力
- Nano Banana Pro保姆級指南!全網(wǎng)最火玩法+官方7大技巧+免費(fèi)渠道,都在這了
- 谷歌發(fā)布Nano Banana Pro ,把設(shè)計(jì)師的飯碗給開源了?
- Nano Banana Pro 深夜炸場,但最大的亮點(diǎn)不是 AI 生圖
- 并行擴(kuò)散架構(gòu)突破極限,5分鐘AI視頻生成,叫板OpenAI與谷歌?
- 李開復(fù):OpenAI的燒錢策略是一場高風(fēng)險(xiǎn)的豪賭,更看好中國模式
- OpenAI 發(fā)布最強(qiáng)編程模型 GPT-5.1
- 全世界在等的Gemini 3終于來了!強(qiáng)到斷崖領(lǐng)先,連馬斯克OpenAI都夸好