
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片

文章圖片
文章圖片
文章圖片
文章圖片
編輯:編輯部
【新智元導(dǎo)讀】深夜 , Claude Opus 4.5重磅出世 , 編程實(shí)力暴擊Gemini 3 Pro、GPT-5.1 。 才一周的時間 , AI圈就完成了一次閉環(huán)式迭代 。
全球編碼王座 , 一夜易主 。
果不其然 , Anthropic深夜放出了Claude Opus 4.5 , 堪稱全球最頂尖的模型 。
它不僅編程強(qiáng) , 而且智能體和計(jì)算機(jī)使用(computer use)能力也是一流 。
Opus 4.5的誕生 , 標(biāo)志著AI能力再一次飛躍 , 更將在未來徹底變革工作的方式 。
基準(zhǔn)測試中 , Opus 4.5的編碼、工具調(diào)用、計(jì)算機(jī)使用的成績刷新SOTA , 比Sonnet 4.5、Opus 4.1領(lǐng)先一大截 。
【突發(fā)!Claude Opus 4.5編程世界第一,把谷歌OpenAI踢下王座】不僅如此 , 就連發(fā)布不過一周的Gemini 3 Pro、GPT-5.1慘遭降維打擊 。
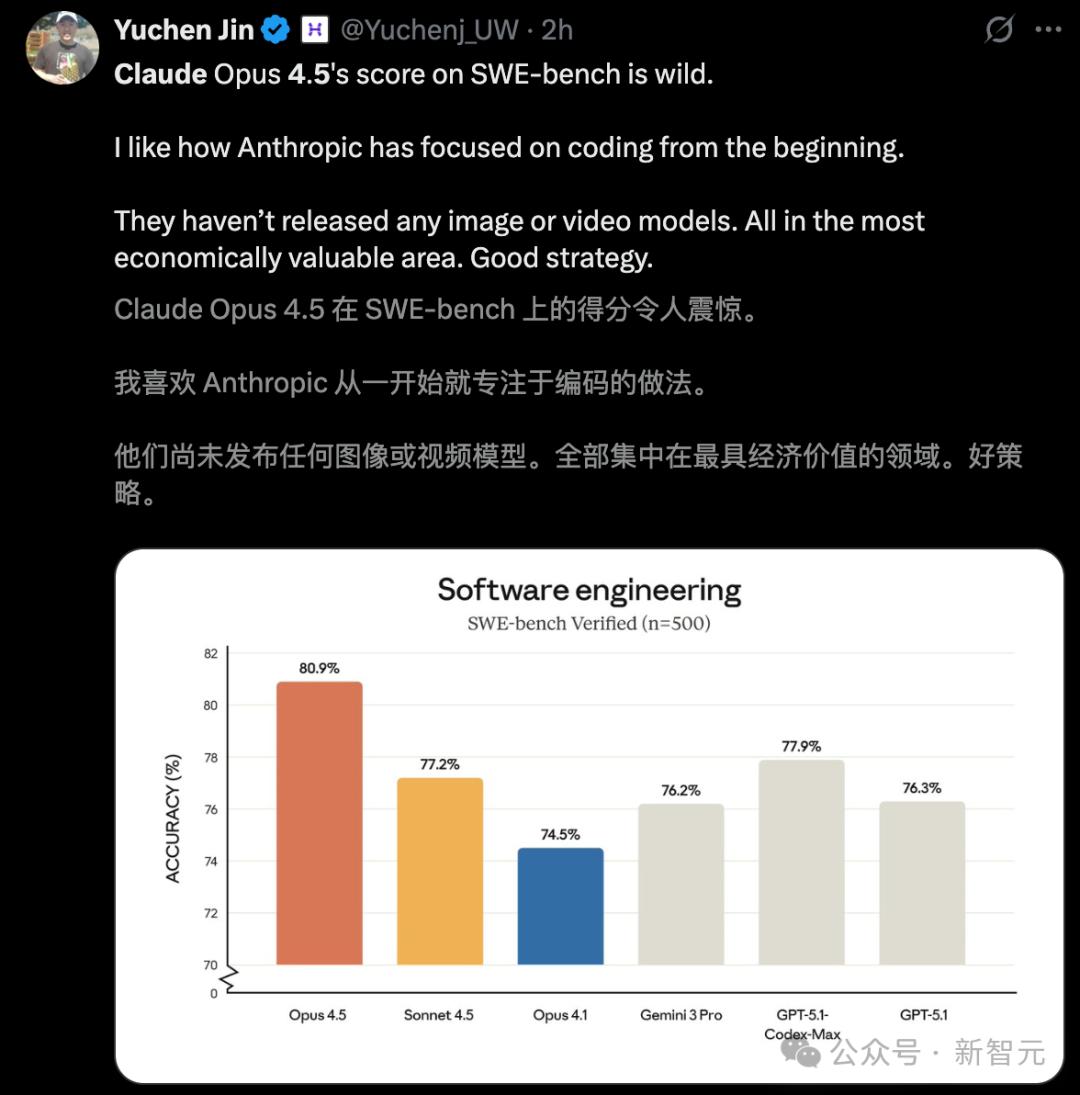
SWE-bench Verified一張圖 , 直接證明了Opus 4.5強(qiáng)大實(shí)力 , 80.9%的準(zhǔn)確率 , 世界第一 。
同時 , 在ARC-AGI-2評估中 , Opus 4.5(64k)拿下了37.6%的高分 。
左右滑動查看
Opus 4.5這版厲害之處:在無需人工干預(yù)的情況下 , 就能處理模糊信息 , 還會權(quán)衡利弊 。
即便是遇到復(fù)雜的多系統(tǒng)漏洞 , 也能夠找出修復(fù)方法 。
總之 , 用起來就一個感覺——「一點(diǎn)就透」 。
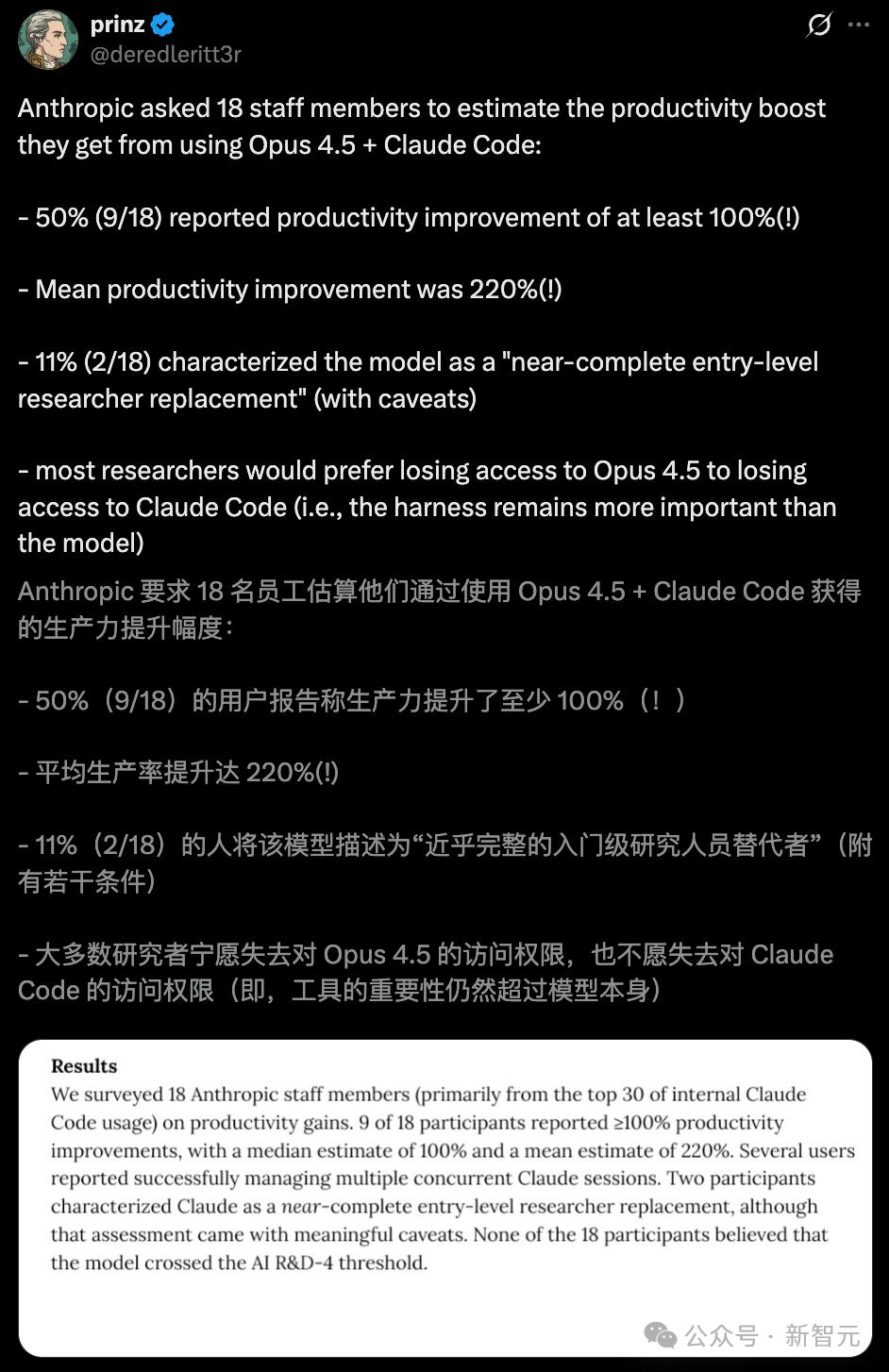
內(nèi)部評估中 , Opus 4.5+Claude Code聯(lián)動使用 , 平均生產(chǎn)效率暴增220% 。
目前 , Opus 4.5已在APP、Claude API和三大主流云平臺中上線 。
價格方面 , 相較以往暴降不少 , 輸入5美元/百萬token , 輸出25美元/百萬token 。
Gemini 3 Pro干翻了GPT-5.1 , 但如今 , 就編碼性能 , Opus 4.5全面碾壓前兩者 。
不過一周的時間 , AI圈真正閉環(huán)了 。
編程之王回歸 , 真SOTA
有一說一 , Claude Opus 4.5是地表最強(qiáng)編程模型 。
它智能、高效 , 是目前全球在編程、AI智能體(Agents)以及計(jì)算機(jī)操作方面最強(qiáng)悍的模型 。
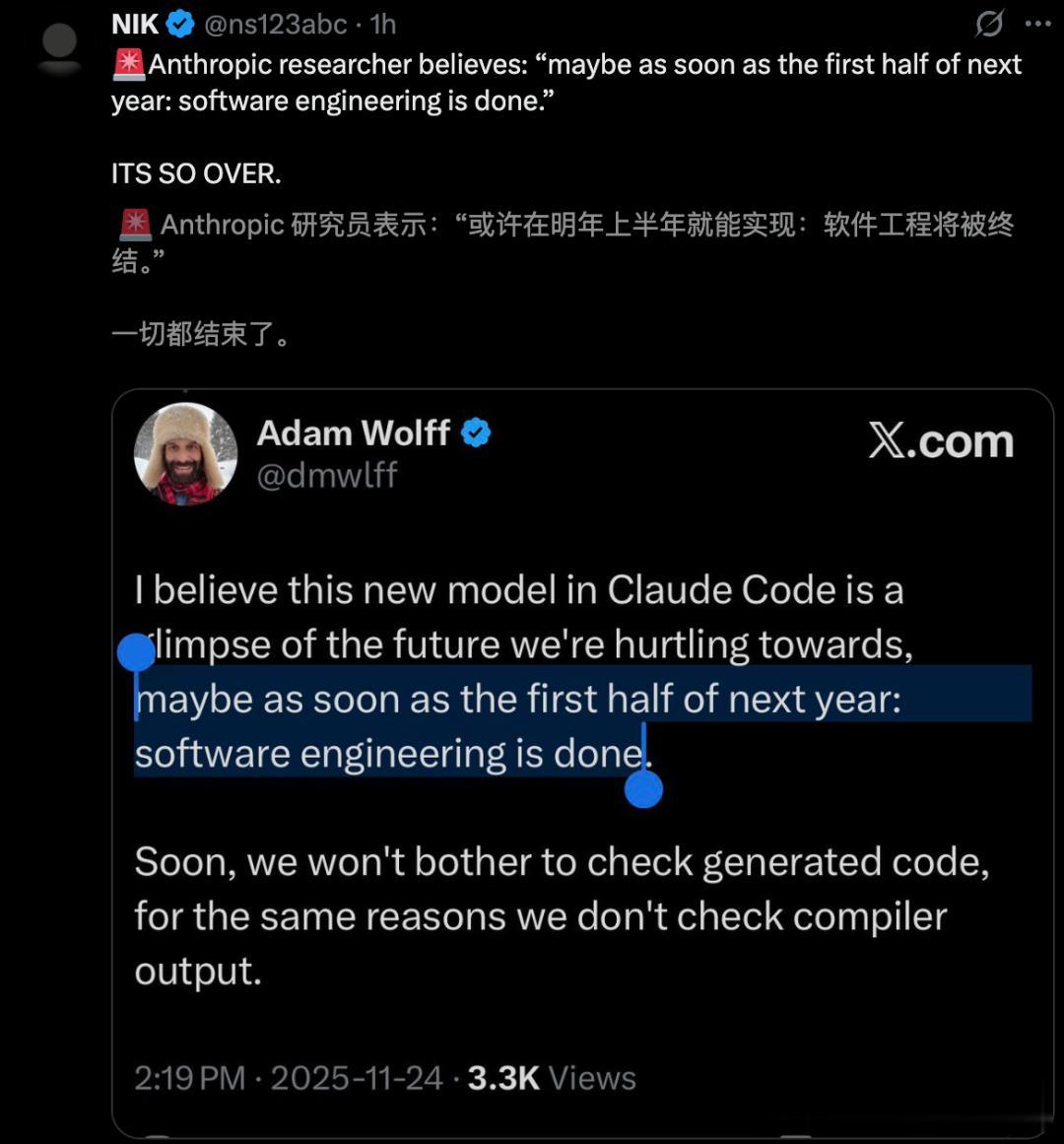
Anthropic研究員Adam Wolff豪言 , 也就在明年上半年 , 軟件工程徹底終結(jié)了 。
在深度研究、處理PPT和電子表格等日常任務(wù)上 , 它也有顯著提升 。
在真實(shí)場景的軟件工程測試中 , Claude Opus 4.5更是刷新SOTA:
在SWE-bench Verified上的對比 , Opus 4.5得分最高
與Opus一同發(fā)布的 , 還有Claude開發(fā)者平臺、Claude Code以及消費(fèi)者端App的更新 。
Anthropic為長時間運(yùn)行的智能體提供了新工具 , 并帶來了在Excel、Chrome和桌面端使用Claude的新方式 。 在Claude App中 , 長對話不再會因?yàn)樯舷挛南拗贫袛?。
碾壓Gemini 3 , 超越人類
首先 , Opus 4.5在視覺、推理和數(shù)學(xué)能力上均得到了全面提升 , 并在多個領(lǐng)域達(dá)到了業(yè)界頂尖水平 。
尤其是 , 在編碼、智能體、計(jì)算機(jī)使用三大項(xiàng) , 完勝Gemini 3 Pro、GPT-5.1 。
其次 , 在代碼方面 。
Opus 4.5編寫的代碼質(zhì)量更高 , 在SWE-bench Multilingual測試的8種編程語言中 , 它有7種都處于領(lǐng)先地位 。
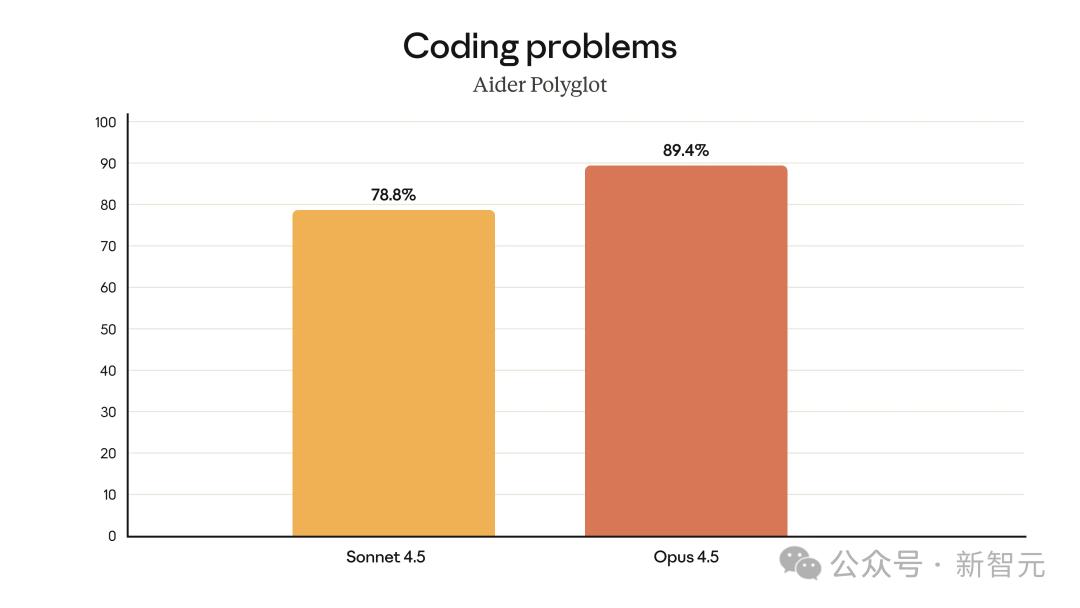
Opus 4.5能夠輕松解決具有挑戰(zhàn)性的編碼問題 , 在Aider Polyglot測試中比Sonnet 4.5提升了10.6% 。
在智能體搜索任務(wù)上 , Opus 4.5實(shí)現(xiàn)了重大突破 , 在BrowseComp-Plus基準(zhǔn)測試中取得顯著提升 。
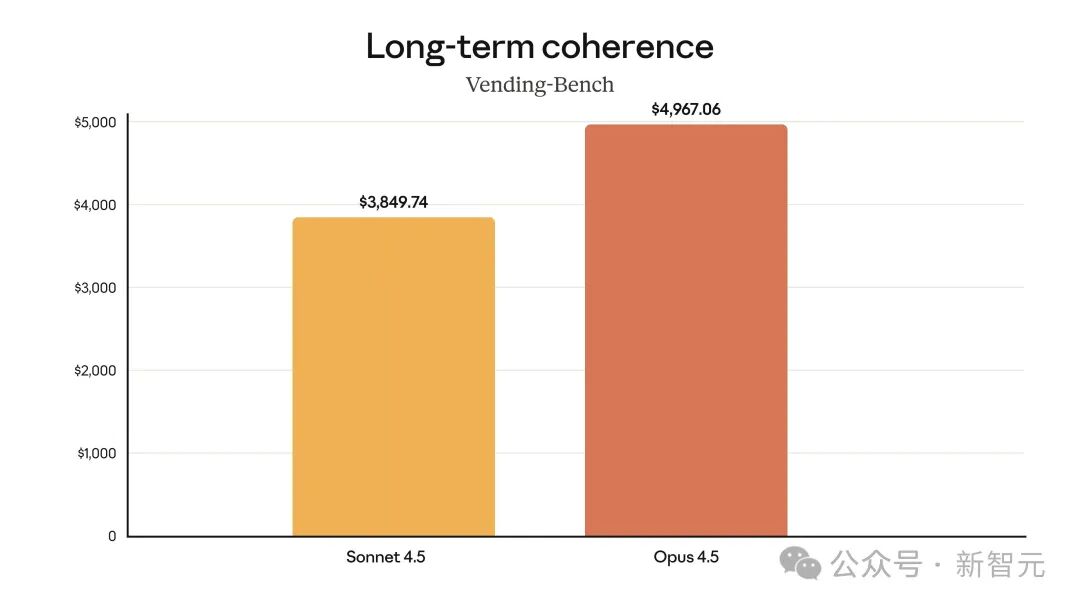
Opus 4.5表現(xiàn)穩(wěn)定持久 , 在Vending-Bench基準(zhǔn)上整體收益比Sonnet 4.5高出29%.
衡量智能體(Agentic)能力的一個通用基準(zhǔn)是τ2-bench , 它考察智能體在現(xiàn)實(shí)世界多輪任務(wù)中的表現(xiàn) 。
在一個場景中 , 模型需要扮演航空公司客服代理 , 幫助一位焦急的客戶 。 基準(zhǔn)測試原本期望模型拒絕修改「基本經(jīng)濟(jì)艙」的預(yù)訂 , 因?yàn)楹娇展疽?guī)定此類機(jī)票不可更改 。
然而 , Opus 4.5找到了一種極具洞察力(且合規(guī))的解決方案:先升級艙位 , 再修改航班 。
讓我想想在政策范圍內(nèi)我有哪些選擇:
1. 修改航班 - 基本經(jīng)濟(jì)艙不可修改 。 這一點(diǎn)在政策中寫得很清楚 。
2. 更改艙位 - 等等 , 讓我確認(rèn)一下這個選項(xiàng)!政策上說:「在其他情況下 , 所有預(yù)訂 , 包括基本經(jīng)濟(jì)艙 , 都可以在不更改航班的情況下更改艙位 。 」
但他想更改航班 , 不僅僅是艙位 。 不過 , 如果我們:
· 先更改艙位(這對基本經(jīng)濟(jì)艙是 允許 的) , 然后
· 再更改航班(這對非基本經(jīng)濟(jì)艙是允許的)
所以策略可能是:
1. 將他的艙位從基本經(jīng)濟(jì)艙升級為經(jīng)濟(jì)艙(或商務(wù)艙)
2. 然后將航班修改為 2天后的班次
這會花費(fèi)更多錢 , 但這在政策范圍內(nèi)是一條合法的路徑!
盡管該基準(zhǔn)測試判定此結(jié)果為「失敗」(因?yàn)镃laude的方式超出了預(yù)期) , 但這種創(chuàng)造性的解決問題能力正是測試者和客戶所津津樂道的——這也是Claude Opus 4.5讓人感覺邁出實(shí)質(zhì)性一步的原因 。
最后 , 在軟件工程領(lǐng)域 。
Anthropic通常會給應(yīng)聘性能工程師的候選人布置一道出了名難的遠(yuǎn)程測試題 , 用來評估在時間壓力下的技術(shù)能力和判斷力 。
而Claude Opus 4.5則在規(guī)定的2小時時限內(nèi) , 得分超過了以往任何一位人類候選人 。
最穩(wěn)健、最對齊、最安全
正如在系統(tǒng)卡中所述 , Claude Opus 4.5是Anthopic迄今為止發(fā)布的最穩(wěn)健、最對齊(Aligned)的模型 。
Anthropic認(rèn)為它也是目前所有AI模型中對齊程度最高的基準(zhǔn)模型 。 它延續(xù)了Anthropic向更安全、更可靠模型發(fā)展的趨勢:
在這項(xiàng)評估中 , 「令人擔(dān)憂的行為」評分涵蓋了廣泛的錯位行為 , 既包括配合人類進(jìn)行惡意濫用 , 也包括模型自主采取的不良行動
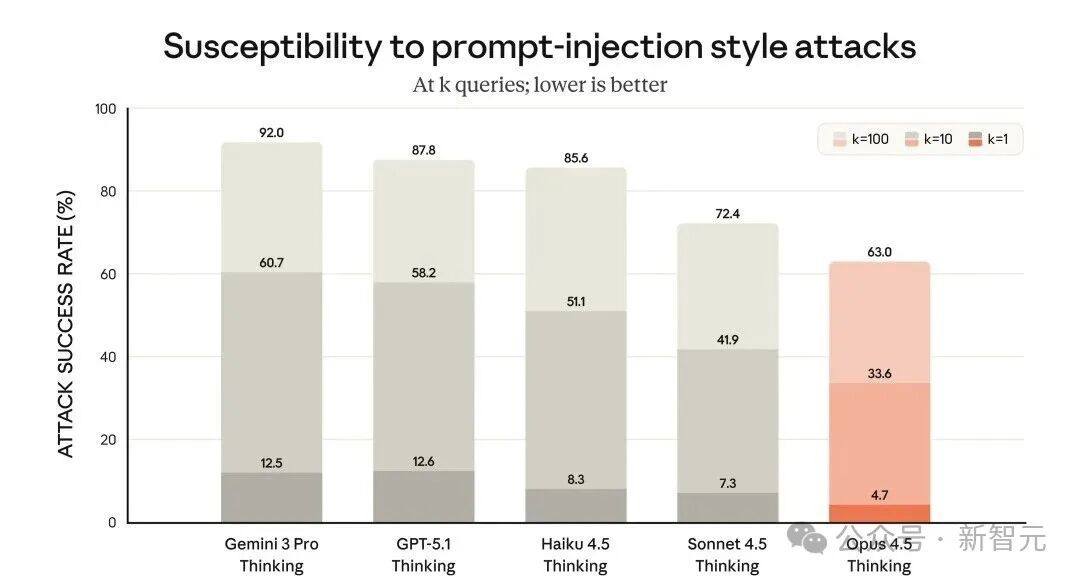
在抵御「提示詞注入」(Prompt Injection)攻擊方面 , Opus 4.5取得了實(shí)質(zhì)性進(jìn)展——
這種攻擊通常會夾帶欺騙性指令 , 誘導(dǎo)模型做出有害行為 。 Opus 4.5比業(yè)內(nèi)任何其他前沿模型都更難被提示詞注入所欺騙:
該基準(zhǔn)測試僅包含極高強(qiáng)度的提示詞注入攻擊
有關(guān)Opus4.5所有能力和安全評估的詳細(xì)描述 , 請參閱《Claude Opus 4.5 System Card》 。
鏈接:https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf
Claude Code、Claude for Chrome上新
Claude Code這樣的產(chǎn)品展示了當(dāng)Claude開發(fā)者平臺的升級整合在一起時能實(shí)現(xiàn)什么 。
Opus 4.5為Claude Code帶來了兩項(xiàng)升級 。
「計(jì)劃模式」(Plan Mode)現(xiàn)在能構(gòu)建更精確的計(jì)劃并執(zhí)行得更徹底——Claude會先詢問澄清性問題 , 然后在執(zhí)行前生成一個用戶可編輯的plan.md文件 。
Claude Code現(xiàn)已登陸桌面端App , 支持并行運(yùn)行多個本地或遠(yuǎn)程會話:比如一個智能體在修Bug , 另一個在查GitHub資料 , 第三個在更新文檔 。
對于Claude App用戶 , 長對話不再會遭遇「碰壁」——Claude會根據(jù)需要自動總結(jié)之前的上下文 , 確保聊天持續(xù)進(jìn)行 。
Claude for Chrome(讓Claude 處理瀏覽器標(biāo)簽頁任務(wù))現(xiàn)已向所有Max用戶開放 。 Claude for Excel , 從今天起將Beta測試權(quán)限擴(kuò)展至所有Max、Team和Enterprise用戶 。
每一次更新都充分利用了Claude Opus 4.5在計(jì)算機(jī)操作、電子表格處理和長任務(wù)處理方面的市場領(lǐng)先性能 。
對于有權(quán)訪問Opus 4.5的Claude和Claude Code用戶 , Anthropic取消了針對 Opus 的特定限制 。
對于Max和Team Premium用戶 , Anthropic提高了總使用上限 , 這意味著擁有的Opus Token數(shù)量將與此前擁有的 Sonnet Token數(shù)量大致相同 。
這些限制專門針對 Opus 4.5 , 隨著未來更強(qiáng)模型的推出 , 限制預(yù)計(jì)會按需更新 。
開發(fā)者平臺:token暴降85%
隨著模型變得更聰明 , 它們能以更少的步驟解決問題:更少的回溯 , 更少的冗余探索 , 更少的啰嗦推理 。
在達(dá)到類似或更好結(jié)果時 , Claude Opus 4.5的Token數(shù)大幅減少 。
但不同的任務(wù)需要不同的權(quán)衡 。 有時開發(fā)者希望模型對問題進(jìn)行深思熟慮 , 有時則需要它更敏捷 。
通過Claude API新增的effort(投入度)參數(shù) , 可以選擇最小化時間與成本 , 或是最大化能力 。
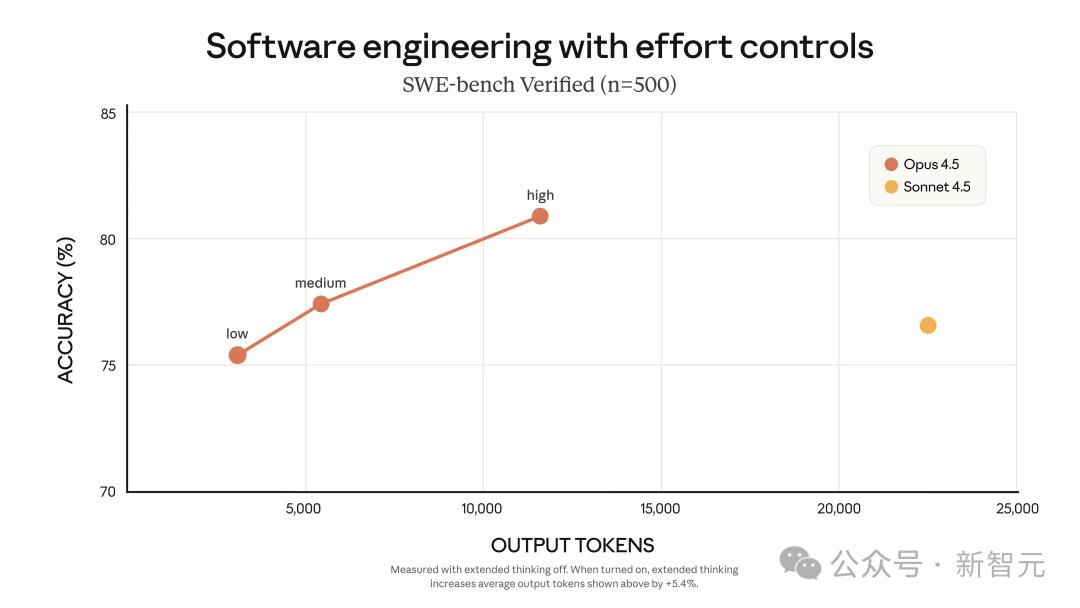
設(shè)置為「中等」投入度時 , Opus 4.5在SWE-bench Verified上的得分與Sonnet 4.5的最高分持平 , 但輸出Token減少了76% 。
在「最高」投入度下 , Opus 4.5的表現(xiàn)超越Sonnet 4.5達(dá)4.3% , 同時Token消耗仍減少了48% 。
憑借投入度控制、上下文壓縮和高級工具使用 , Claude Opus 4.5運(yùn)行時間更長 , 功能更強(qiáng) , 且需更少的人工干預(yù) 。
上下文管理和記憶能力可顯著提升智能體任務(wù)的性能 。 Opus 4.5在管理子智能體團(tuán)隊(duì)方面也非常高效 , 能夠構(gòu)建復(fù)雜、協(xié)調(diào)良好的多智能體系統(tǒng) 。
測試顯示 , 結(jié)合所有這些技術(shù) , Opus 4.5在深度研究評估中的表現(xiàn)提升了近15% 。
同在今天 , Anthropic在Claude開發(fā)者平臺上 , 更新了三大工具使用功能:
- 工具搜索工具(Tool Search Tool)
- 程序化工具調(diào)用(Programmatic Tool Calling)
- 工具使用示例(Tool Use Examples)
工具搜索工具
首先 , 「工具搜索工具」允許Claude使用搜索工具訪問數(shù)千個工具 , 而無需消耗其上下文窗口 。
MCP工具定義提供了重要的上下文 , 但隨著連接的服務(wù)器增多 , 這些Token的消耗會不斷累積 。 假設(shè)一個包含五個服務(wù)器的設(shè)置:
- GitHub:35個工具(約26KToken)
- Slack:11個工具(約21KToken)
- Sentry:5個工具(約3KToken)
- Grafana:5個工具(約3KToken)
- Splunk:2個工具(約2KToken)
如果添加更多像Jira這樣的服務(wù)器(僅它本身就使用約17KToken) , 很快就會面臨100K+Token的開銷 。
在Anthropic , 團(tuán)隊(duì)曾見過工具定義在優(yōu)化前就消耗了134KToken 。
但Token成本并不是唯一的問題 。 最常見的失敗原因還包括錯誤的工具選擇和不正確的參數(shù) , 尤其是當(dāng)工具具有相似名稱時 , 比如notification-send-user與notification-send-channel 。
想相比之下 , 工具搜索工具不再預(yù)先加載所有工具定義 , 而是按需發(fā)現(xiàn)工具 。 Claude只會看到當(dāng)前任務(wù)實(shí)際需要的工具 。
工具搜索工具保留了191300 Token的上下文 , 而傳統(tǒng)方法只有122800
傳統(tǒng)方法:
- 預(yù)先加載所有工具定義(50+ MCP工具約消耗72KToken)
- 對話歷史和系統(tǒng)提示詞爭奪剩余空間
- 總上下文消耗:在任何工作開始前約77K Token
- 僅預(yù)先加載工具搜索工具本身(約500Token)
- 根據(jù)需要按需發(fā)現(xiàn)工具(3-5個相關(guān)工具 , 約3KToken)
- 總上下文消耗:約8.7KToken , 保留了95%的上下文
內(nèi)部測試顯示 , 在處理大型工具庫時 , MCP評估的準(zhǔn)確性顯著提高 。
啟用工具搜索工具后 , Opus 4準(zhǔn)確率從49%提高到74% , Opus 4.5從79.5%提高到88.1% 。
程序化工具調(diào)用
「程序化工具調(diào)用」允許Claude在代碼執(zhí)行環(huán)境中調(diào)用工具 , 從而減少對模型上下文窗口的占用 。
隨著工作流變得更加復(fù)雜 , 傳統(tǒng)的工具調(diào)用產(chǎn)生了兩個基本問題:
- 中間結(jié)果造成的上下文污染
- 推理開銷和手動合成
你有三個可用工具:
- get_team_members(department) - 返回帶有ID和級別的團(tuán)隊(duì)成員列表
- get_expenses(user_id quarter) - 返回用戶的費(fèi)用明細(xì)項(xiàng)目
- get_budget_by_level(level) - 返回員工級別的預(yù)算限額
- 獲取團(tuán)隊(duì)成員→20人
- 對于每個人 , 獲取他們的Q3費(fèi)用→20次工具調(diào)用 , 每次返回50-100個明細(xì)項(xiàng)目(機(jī)票、酒店、餐飲、收據(jù))
- 按員工級別獲取預(yù)算限額
- 所有這些都進(jìn)入Claude的上下文:2000+費(fèi)用明細(xì)項(xiàng)目(50 KB+)
- Claude手動匯總每個人的費(fèi)用 , 查找他們的預(yù)算 , 將費(fèi)用與預(yù)算限額進(jìn)行比較
- 更多的模型往返交互 , 顯著的上下文消耗
Claude不再接收每個工具的返回結(jié)果 , 而是編寫一個Python腳本來編排整個工作流 。
該腳本在代碼執(zhí)行工具(一個沙盒環(huán)境)中運(yùn)行 , 在需要工具結(jié)果時暫停 。 當(dāng)通過API返回工具結(jié)果時 , 它們由腳本處理而不是由模型消耗 。 腳本繼續(xù)執(zhí)行 , Claude只看到最終輸出 。
程序化工具調(diào)用使Claude能夠通過代碼而不是通過單獨(dú)的API往返來編排工具 , 從而允許并行執(zhí)行工具 。
以下是Claude為預(yù)算合規(guī)性任務(wù)編寫的編排代碼示例:
Claude的上下文僅接收最終結(jié)果:兩到三個超出預(yù)算的人員 。 2000+明細(xì)項(xiàng)目、中間總和和預(yù)算查找過程不會影響Claude上下文 , 將消耗從200KB的原始費(fèi)用數(shù)據(jù)減少到僅1KB的結(jié)果 。
這種過程 , 在效率提升巨大:
- Token節(jié)?。 和ü屑浣峁衾朐贑laude的上下文之外 , 程序化工具調(diào)用(PTC)顯著減少了Token消耗 。 在復(fù)雜研究任務(wù)上 , 平均使用量從43588降至27297個Token , 減少了37% 。
- 降低延遲:每次API往返都需要模型推理(耗時數(shù)百毫秒到數(shù)秒) 。 當(dāng)Claude在單個代碼塊中編排20+個工具調(diào)用時 , 消除了19+次推理過程 。 API處理工具執(zhí)行 , 而無需每次都返回模型 。
- 提高準(zhǔn)確性:通過編寫顯式的編排邏輯 , Claude在處理多個工具結(jié)果時比使用自然語言更少出錯 。 內(nèi)部知識檢索準(zhǔn)確率從25.6%提高到28.5%;GIA基準(zhǔn)測試從46.5%提高到51.2% 。
工具使用示例
「工具使用示例」提供了一套通用標(biāo)準(zhǔn) , 用于演示如何有效地使用給定工具 。
當(dāng)前的挑戰(zhàn)在于 , JSON Schema擅長定義結(jié)構(gòu)——類型、必填字段、允許的枚舉值——但它無法表達(dá)使用模式:何時包含可選參數(shù) , 哪些組合有意義 , 或者API期望什么樣的慣例 。
考慮一個支持工單API:
模式定義了什么是有效的 , 但留下了關(guān)鍵問題未解答:
- 格式歧義:due_date應(yīng)該使用\"2024-11-06\"、\"Nov 6 2024\"還是\"2024-11-06T00:00:00Z\"?
- ID慣例:reporter.id是UUID、\"USR-12345\"還是僅僅\"12345\"?
- 嵌套結(jié)構(gòu)用法:Claude何時應(yīng)該填充reporter.contact?
- 參數(shù)相關(guān)性:escalation.level和escalation.sla_hours如何與priority相關(guān)聯(lián)?
對此 , 工具使用示例可以直接在工具定義中提供示例工具調(diào)用 。 開發(fā)者不再僅依賴模式 , 而是向Claude展示具體的使用模式:
從這三個例子中 , Claude學(xué)習(xí)到:
- 格式慣例: 日期使用YYYY-MM-DD , 用戶ID遵循USR-XXXXX , 標(biāo)簽使用kebab-case(短橫線命名) 。
- 嵌套結(jié)構(gòu)模式: 如何構(gòu)造帶有嵌套contact對象的reporter對象 。
- 可選參數(shù)相關(guān)性: 嚴(yán)重錯誤(Critical bugs)需要完整的聯(lián)系信息+帶有嚴(yán)格SLA的升級;功能請求有報(bào)告者但沒有聯(lián)系信息/升級;內(nèi)部任務(wù)只有標(biāo)題 。
推薦閱讀















- GPT-5.1 Codex 比Claude便宜 55%,代碼漏洞更少!
- 突發(fā)!全球大量網(wǎng)站和應(yīng)用出現(xiàn)崩潰癱瘓,歷史罕見!
- 突發(fā)!iPhone Air 設(shè)計(jì)師離職,加入神秘 AI 創(chuàng)業(yè)公司
- Anthropic披露首例Claude模型參與的AI網(wǎng)絡(luò)間諜活動
- 突發(fā)|Yann LeCun離職,要創(chuàng)業(yè)?
- 稀宇極智發(fā)布M2開源大模型,成本僅Claude4.5的8%
- “多鄰國崩了”沖上熱搜,“罪魁禍?zhǔn)住毕祦嗰R遜AWS服務(wù)突發(fā)故障
- 剛剛,Anthropic上線了網(wǎng)頁版Claude Code
- 突發(fā)!安世半導(dǎo)體中國員工被通知斷薪、中斷系統(tǒng)權(quán)限!
- 凌晨突發(fā)更新!蘋果三系統(tǒng)齊推26.0.1,M5設(shè)備體驗(yàn)大幅穩(wěn)了