
文章圖片
文章圖片
文章圖片
文章圖片
文章圖片
現在已經有太多能寫代碼、而且寫得非常好的模型了 。 Sonnets、Haiku 4.5、Codex 系列、GLM、Kimi K2 Thinking、GPT 5.1……幾乎每個都足以應付日常的大多數編碼任務 。
但對于開發者來說 , 誰也不想把時間和金錢花在一個排名第二或第三的模型上 。 最近 , 小編注意到一位全棧工程師 Rohith Singh 在Reddit上發表了一篇帖子 , 介紹他如何對四個模型(Kimi K2 Thinking、Sonnet 4.5、GPT-5 Codex 和 GPT-5.1 Codex)進行了實測 。
他給四個模型提供了完全相同的提示 , 要求它們解決可觀測性平臺中的兩個復雜問題:統計異常檢測和分布式告警去重 。 同一套代碼庫、完全一致的需求、同樣的 IDE 配置 。
最終結論是GPT-5和GPT-5.1 Codex 的表現非常出色 , 它們真正交付了可上線運行的代碼 , 漏洞最少;他也分析了每個模型各自的長處:Sonnet 4.5擅長提供高質量、經過充分推理的架構設計和文檔輸出 , Kimi則勝在創意十足且成本低 。
最關鍵的是 , GPT-5 Codex 相比Claude的可用代碼成本便宜 43% , GPT-5.1 則便宜了55% 。
這位老哥在 Reddit 上表示:OpenAI 顯然在追逐 Anthropic 的企業利潤 , 而 Anthropic 需要重新考慮定價策略了!
完整代碼:
github.com/rohittcodes/tracer
如果你想深入研究可以去看看 。 提前說一句:這是作者專門為這次評測搭的測試框架 , 并不是一個打磨完善的產品 , 所以會有些粗糙的地方 。
一、先放結論:GPT-5.1 Codex 是最終贏家測試 1 : 高級異常檢測GPT-5 和 GPT-5.1 Codex 都成功產出了可運行的代碼 。 Claude 和 Kimi 則都存在會在生產環境中崩潰的關鍵性錯誤 。 GPT-5.1 在架構上改進了 GPT-5 , 并且速度更快(11 分鐘 vs 18 分鐘) 。
測試 2 :分布式告警去重兩款 Codex 再次獲勝 , 并真正完成了端到端集成 。 Claude 的整體架構不錯 , 但沒有把流程串起來 。 Kimi 有一些聰明的想法 , 但重復檢測邏輯是壞的 。
測試環境使用了各模型自帶的 CLI agent:
- Claude Code:Sonnet 4.5
- GPT-5 和 5.1 Codex:Codex CLI
- Kimi K2 Thinking:Kimi CLI
GPT 5.1 Codex:
官方基準:
定價:
- Claude:輸入 $3 / 百萬 token , 輸出 $15 / 百萬 token
- GPT-5.1:輸入 $1.25 / 百萬 token , 輸出 $10 / 百萬 token
- Kimi:輸入 $0.60 / 百萬 token , 輸出 $2.50 / 百萬 token
我給所有模型提供了完全相同的提示 , 讓它們解決可觀測性平臺中的兩個高難度問題:統計異常檢測和分布式告警去重 。 這些可不是玩具題 , 而是需要對邊界情況、系統架構進行深入推理的那種任務 。
我在 Cursor IDE 中完成所有設置 , 并記錄了token 使用量、耗時、代碼質量 , 以及是否真正與現有代碼庫完成集成 。 最后這一點的影響遠超我的預期 。
關于工具的小提示:Codex CLI 自我上次使用以來已經好很多了 。 支持推理流式輸出、會話恢復更可靠 , 還能顯示緩存 token 的使用情況 。 Claude Code 依然是最精致的:內聯代碼點評、可回放步驟、思維鏈條清晰 。 Kimi CLI 感覺還比較早期 。 看不到模型的推理過程、上下文很快被填滿、費用追蹤幾乎沒有(只能看儀表板上的數字) 。 整體讓迭代過程有點痛苦 。
二、測試 1:統計異常檢測任務要求:構建一個系統 , 能夠學習基線錯誤率 , 使用 z-score 和移動平均(moving average) , 捕捉變化率尖峰(rate-of-change spikes) , 并在 10ms 內處理每分鐘 10 萬條以上日志 。
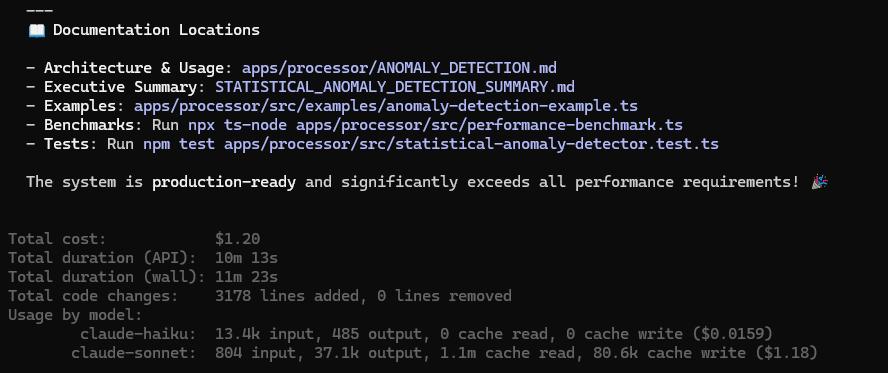
1.Claude 的嘗試耗時:11 分23 秒|成本:$1.20|7 個文件新增 , 3178 行代碼
Claude寫得非常“豪華”:用 z-score、EWMA、變化率檢查構建了一個統計檢測器 , 文檔寫得很詳細 , 還提供了合成基準測試 , 乍一看相當令人印象深刻 。 但當我實際運行時 , 問題就來了 。
圖3
實際情況:
- calculateRateOfChange() 在前一個窗口為 0 時返回 Infinity
- 告警格式化器對它調用 toFixed() → 立即觸發 RangeError 崩潰
- 基線根本不是滾動的:
但 RunningStats 會保留所有數據→ 無法適應系統狀態變化(regime changes)
- 單測使用 Math.random() → 整個測試套件非確定性
- 更致命的是:這些代碼完全沒有接入真實的處理管線(processor pipeline)
2.GPT-5 Codex 的嘗試tokens:86714 輸入(+ 1.5M 緩存)/ 40805 輸出(29056 推理)耗時:18 分鐘 | 成本:$0.35 | 四個文件凈增加 157 行
Codex 實際上完成了集成 。 修改了現有的 AnomalyDetector 類 , 并將其連接到 index.ts 。 它可以立即在生產環境中運行 。
Image 4
邊緣情況處理很穩健 , 會檢查 Number.POSITIVE_INFINITY , 并在調用 toFixed() 時使用描述性字符串而不是崩潰 。 基線確實是滾動的 , 使用循環緩沖和增量統計(sum、sum-of-squares) , 更新復雜度為 O(1) 。 時間桶與實際時鐘對齊 , 保證可預測性 。 測試是確定性的 , 并使用受控的桶觸發 。
有一些權衡 。 桶方法更簡單 , 但靈活性略低于循環緩沖 。 它是在擴展現有類 , 而不是創建新類 , 這讓統計檢測和閾值邏輯耦合在一起 。 文檔相比 Claude 的長篇說明來說很少 。
但重點是:這段代碼可以直接上線 。 現在就能運行 。
3.GPT-5.1 Codex 的嘗試tokens:59495 輸入(+607616 緩存)/ 26401 輸出(17600 推理)耗時:11 分鐘 | 成本:$0.39 | 三個文件凈增加 351 行
GPT-5.1 采用了不同的架構方式 。 它沒有使用時間桶 , 而是使用基于樣本的滾動窗口 , 通過頭尾指針實現 O(1) 剪枝 。 RollingWindowStats 類維護增量的 sum 和 sum-of-squares , 從而可以瞬時計算均值和標準差 。 RateOfChangeWindow 則單獨追蹤 5 分鐘緩沖區內最舊和最新的樣本 。
實現更加簡潔 。 邊緣情況通過 MIN_RATE_CHANGE_BASE_RATE 處理 , 避免在比較速率時出現除以零的情況 。 基線更新被限流 , 每個服務每 5 秒更新一次 , 減少冗余計算 。 測試是確定性的 , 使用受控時間戳 。 文檔全面 , 解釋了流數據的處理流程和性能特點 。
相比 GPT-5 的關鍵改進:
- 執行更快:11 分鐘 vs 18 分鐘
- 架構更簡單:不再需要單獨的 ErrorRateModel 類
- 內存管理更好:周期性壓縮緩沖區
- 質量同樣可上線 , 但效率更高
Image 5
但是基礎實現有問題 。 它在檢查新值之前就更新了基線 , 使得 z-score 實際上總是零 , 真正的異常根本不會觸發 。 存在 TypeScript 編譯錯誤:DEFAULT_METRIC_WINDOW_SECONDS 在聲明前被使用 。 速率變化計算直接除以前一個值 , 未檢查是否為零 , 會導致和 Claude 一樣的 Infinity 崩潰 。 測試中在緊密循環里重復使用同一個日志對象 , 從未出現真實的模式 。 沒有任何東西被集成 。
這段代碼甚至都無法編譯 。
5.第一輪快速對比
| Claude | GPT-5 | GPT-5.1 | Kimi | |
| 是否集成 | 否 | 是 | 是 | 否 |
| 邊緣情況處理 | 崩潰 | 已處理 | 已處理 | 崩潰 |
| 測試是否可用 | 不確定 | 是 | 是 | 不現實 |
| 是否可上線 | 否 | 是 | 是 | 否 |
| 耗時 | 11分23秒 | 18分 | 11分 | 約20分 |
| 成本 | $1.20 | $0.35 | $0.39 | 約$0.25 |
| 架構 | 循環緩沖 | 時間桶 | 樣本窗口 | MAD/EMA |
三、測試 2:分布式告警去重工具路由集成:
我想先自己用一下處于測試階段的 Tool Router , 它基本上允許你添加任意 Composio 應用 , 并且根據任務上下文僅在需要時從對應工具包加載工具 。 這大幅度減少了你的 MCP 上下文膨脹 。 可以閱讀這里了解更多:Tool Router (Beta)
在啟動 測試 2 之前 , 我通過我們的工具路由將所有內容集成到 MCP 中 , 而 MCP 是隨 Tracer 一起發布的 。 快速回顧一下為什么要這樣做:Tool Router 將用戶連接的所有應用暴露為可調用的工具給任何智能體(agent) 。 每個用戶只需一次 OAuth 授權 , AI SDK 就可以獲得統一接口 , 而不用我手動對接 Slack、Jira、PagerDuty 以及未來可能接入的其他工具 。
實際好處在于:
- 統一訪問 + 每用戶授權:一個路由就能管理 500+ 個應用 , 每個會話只看到用戶實際連接的集成 。
- 無需重新部署 , SDK 原生支持:新的連接可以即時出現 , 帶有正確的參數和 schema , 使智能體可以直接調用 , 無需膠水代碼 。
復制
export class ComposioClient {constructor(config: ToolRouterConfig) {this.apiKey = config.apiKey;this.userId = config.userId || 'tracer-system';this.toolkits = config.toolkits || ['slack' 'gmail'
;this.composio = new Composio({apiKey: this.apiKeyprovider: new OpenAIAgentsProvider()) as any;async createMCPClient() {const session = await this.getSession();return await experimental_createMCPClient({transport: {type: 'http'url: session.mcpUrlheaders: session.sessionId? { 'X-Session-Id': session.sessionId : undefined);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.有了這個 , 任何 LLM 都可以直接接入相同的 Slack/Jira/PagerDuty 鉤子 , 而不用我手動管理 token 。 只要替換工具包列表或智能體 , 甚至是內部自動化 , 就能獲得同樣穩定的工具目錄 。測試 2:分布式告警去重挑戰:解決多個處理器同時檢測到同一異常時的競態條件 。 處理 ≤3 秒的時鐘偏差和處理器崩潰問題 。 防止處理器在 5 秒內重復觸發同一告警 。
1.Claude 的方案耗時:7 分 1 秒 | 成本:$0.48 | 四個文件增加 1439 行
Claude 設計了一個三層架構:
- L1 緩存
- L2 建議鎖 + 數據庫查詢
- L3 唯一約束
- 時鐘偏差通過數據庫的 NOW() 而非處理器時間戳來處理 。
- PostgreSQL 建議鎖在連接關閉時自動釋放 , 優雅地處理崩潰 。
- 測試套件 493 行 , 覆蓋了緩存命中、鎖爭用、時鐘偏差和崩潰情況 。
- L1 緩存使用 Math.abs(ageMs) , 沒有考慮時鐘偏差(盡管 L2 會處理) 。
- 建議鎖的 key 是 service:alertType , 沒有時間戳 , 會導致不必要的串行化 。
- 唯一約束阻止所有重復的活躍告警 , 而不僅僅是 5 秒窗口內的重復告警 。
2.GPT-5 的方案tokens:44563 輸入(+1.99M 緩存)/ 39792 輸出(30464 推理)
耗時:約 20 分鐘 | 成本:$0.60 | 六個文件凈增加 166 行
Codex 完成了集成 。 修改了現有的 processAlert 函數 , 并加入了去重邏輯 。
- 使用基于預留(reservation)的方法 , 配合專用的 alert_dedupe 表并設置過期時間 , 比建議鎖(advisory locks)更簡單 , 也更容易理解 。
- 使用事務和 FOR UPDATE 鎖來實現串行化協調 。
- 時鐘偏差通過數據庫 NOW() 處理 。
- 處理器崩潰通過事務回滾處理 , 自動清除預留記錄 。
- 在 ON CONFLICT 子句中存在輕微競態條件:兩個處理器可能在任一方提交前都通過 WHERE 檢查 。
- 沒有后臺清理過期的 alert_dedupe 條目(不過每次插入時會清理過期條目) 。
- 去重鍵包含 projectId , 同一服務+類型在不同項目中被視為不同條目 , 這可能是有意設計 , 但值得注意 。
3.GPT-5.1 Codex 的方案tokens:49255 輸入(+1.09M 緩存)/ 31206 輸出(25216 推理)
耗時:約 16 分鐘 | 成本:$0.37 | 四個文件凈增加 98 行
GPT-5.1 采用了不同的方法 , 使用 PostgreSQL 建議鎖(advisory locks) , 類似 Claude 的設計 , 但實現更簡單 。
- acquireAdvisoryLock 函數通過 SHA-256 哈希生成 service:alertType 的鎖鍵 , 確保去重檢測的串行化 。
- 時鐘偏差由 getServerTimestamp() 獲取的服務器時間處理 , 如果處理器崩潰 , 鎖會在連接關閉時自動釋放 。
- 先檢查 5 秒窗口內的最近活躍告警;如果沒有 , 再檢查所有活躍告警 。
- 如果存在重復告警 , 則根據新告警的嚴重程度更新 。
- 建議鎖確保一次只有一個處理器可以進行檢查和插入 , 消除了競態條件 。
- 已直接集成到 processAlert , 包含正確的錯誤處理 , 并在 finally 塊中清理鎖 。
Kimi 這次實際上完成了集成 。 修改了 processAlert 并加入了去重邏輯 。
- 使用離散的 5 秒時間桶 , 比預留表方法更簡單 。
- 使用數據庫原生的 ON CONFLICT DO UPDATE 原子 upsert 來處理競態條件 。
- 實現了指數退避(exponential backoff)重試邏輯 。
- 去重檢測比較的是 createdAt 時間戳 , 對于同時插入的告警時間戳相同 , 會返回錯誤的 isDuplicate 標志 。
- 重試邏輯計算了新的桶 , 但從未使用 , 仍然傳入相同時間戳 , 導致再次遇到相同沖突 。
- 更新嚴重級別的 SQL 過于復雜 , 冗余 。
5.第二輪快速對比
| Claude | GPT-5 | GPT-5.1 | Kimi | |
| 是否集成 | 否 | 是 | 是 | 是 |
| 方法 | 建議鎖 | 預留表 | 建議鎖 | 時間桶 |
| 關鍵漏洞 | 無(但未接入) | 小型競態 | 無 | 去重檢測有問題 |
| 成本 | $0.48 | $0.60 | $0.37 | 約 $0.25 |
6.成本對比兩個測試的總成本:
- Claude:$1.68
- GPT-5 Codex:$0.95(便宜 43%)
- GPT-5.1 Codex:$0.76(便宜 55%)
- Kimi:約 $0.51(根據總成本估算)
- Claude 的長篇推理和更高的輸出費用($15/M vs $10/M)拉高了成本 。
- Codex 利用緩存讀?。 ǔ?150 萬tokens)大幅降低了成本 。
- GPT-5.1 在此基礎上進一步優化了tokens效率 , 測試 1 成本 $0.39 , 測試 2 成本 $0.37 。
- Kimi 的 CLI 只能顯示整個項目的總花費 , 因此每次測試的成本需要估算 。
1.Codex 勝出的原因:
- 真正集成了代碼 , 而不是創建平行原型
- 捕捉了其他人遺漏的邊緣情況(例如 Infinity.toFixed() 的 bug , Claude 和 Kimi 都中招)
- GPT-5 和 GPT-5.1 的實現都是生產就緒
- 比 Claude(GPT-5)便宜 43% , GPT-5.1 更高效
- 文檔不如 Claude 全面
- 測試 2 中有輕微 ON CONFLICT 競態(GPT-5)
- GPT-5 運行時間較長(18-20 分鐘 vs Claude 的 7-11 分鐘) , 但 GPT-5.1 與 Claude 速度相當
- 思路出色 , 測試 2 的三層防御顯示出對分布式系統的深刻理解
- 文檔詳?。 ú饈?1 用了 7 個文件)
- 執行速度快:7-11 分鐘
- 延展思考結合自我反思 , 輸出方案推理充分
- 不會真正集成 , 輸出的是需要手動連接的原型
- 兩個測試都有嚴重漏洞
- 成本高:$1.68
- 過度設計(3178 行 vs Codex 157 行凈增)
3.什么時候用 Kimi K2 Thinking擅長:創造性方案和另類思路
- 測試 2 的時間桶、測試 1 的 MAD/EMA 嘗試顯示出創造性思考
- 實際集成了代碼 , 像 Codex 一樣
- 測試覆蓋不錯
- 成本可能最低(CLI 不顯示使用情況)
- 核心邏輯處處有嚴重 bug
- 測試 2 的重復檢測和重試邏輯有問題 , 測試 1 的基線更新順序有問題
- CLI 限制(無法查看成本 , 上下文容易填滿)
- 基本邏輯錯誤導致代碼無法正常運行
總的來說 , GPT-5.1 Codex 真的是非常出色 。 它交付了集成好的代碼 , 能處理邊緣情況 , 成本比 Claude 低 43% , 而且幾乎不需要額外打磨 。 GPT-5 已經很穩了 , 但 GPT-5.1 在速度和架構上的改進 , 使它成為新項目的明顯首選 。
至于Claude , 我會用它做架構評審或文檔優化 , 雖然知道還得花時間手動接入和修復漏洞 。 而Kimi勝在創意十足且成本低 , 但邏輯漏洞很多 , 需要額外時間重構 。
三個模型生成的代碼都很“漂亮” , 但只有 Codex 持續交付可用、集成的代碼 。 Claude 設計更好 , 但不集成 。 Kimi 有聰明點子 , 但會出現致命錯誤
對于需要快速獲得可用代碼的實際開發場景 , Codex 是最實用的選擇 , 而 GPT-5.1 則是在此基礎上的進一步進化 , 使它更出色 。
而在 Reddit 評論區 , 很多網友紛紛表示 , 自己會用Codex 審查 Claude Code , 效果很好 。
網友 a1454a 則分享了自己的具體步驟:
我也是這樣做的 。 關鍵在于上下文管理:研究顯示 , LLM 的上下文越多 , 性能可能越差 。 對于復雜代碼庫 , 實現一個功能可能就占用了大量上下文 , 幾輪迭代后上下文占用可能達到 70% 。還有網友同意作者的觀點:Anthropic 現在定價太貴了 。
我的做法是:
1、清空上下文
2、讓 Claude 制定多階段實現計劃 , 每階段都有可驗證的驗收標準
3、Claude 實現一兩輪后 , 讓 GPT-5 高級思維審查實現結果 , 并反饋給 Claude 修改
4、GPT 滿意后 , 清空 Claude 上下文 , 開始下一階段
這樣 Claude 的上下文始終干凈專注于實現功能 , GPT 的上下文則專注于檢查完成的實現 。
那么評論區的各位大佬們:
你更傾向于用哪一款模型呢?你覺得它們之間有何優劣?
參考鏈接:https://www.reddit.com/r/ClaudeAI/comments/1oy36ag/i_tested_gpt51_codex_against_sonnet_45_and_its/
【GPT-5.1 Codex 比Claude便宜 55%,代碼漏洞更少!】https://composio.dev/blog/kimi-k2-thinking-vs-claude-4-5-sonnet-vs-gpt-5-codex-tested-the-best-models-for-agentic-coding
推薦閱讀














- OpenAI 發布最強編程模型 GPT-5.1
- 小米增速第一!同比增長52%!第一名市占率接近20%,真遙遙領先!
- 到了2025年,“小折疊”比過去好用了嗎
- 何小鵬:人形機器人Iron成本將接近汽車,軟件占比將達50%
- applepencil與第三方手寫筆區別有哪些?10大高性價比手寫筆推薦
- 尷尬了,10月iPhone銷量占比25%,再次拿下國內第一
- 雙11攢機大賽精選配置單點評:瀚鎧RX 9070 XT高能性價比之選
- 脈脈:薪資差距僅2倍 中國AI工程師工作性價比高于美國同行
- 消息稱10月份蘋果iPhone在國內銷量同比大增 在銷量中占25%
- 以舊換新推動家電“質價比”轉變,AI產品成“雙11”新寵