文章圖片
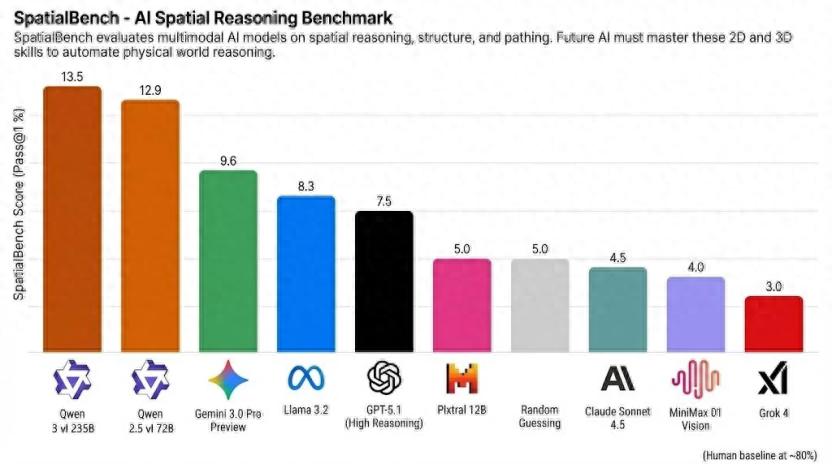
【超越Gemini3、GPT5.1,阿里千問登頂空間推理全球冠軍】11月26日 , 空間推理基準測試SpatialBench更新了最新一期榜單 , 阿里千問的視覺理解模型Qwen3-VL、Qwen2.5-VL位列頭兩名 , 超越Gemini 3、GPT-5.1、Claude Sonnet4.5等國際頂尖模型 。
據(jù)了解 , SpatialBench是一項近年來興起的第三方空間推理基準測試榜單 , 主要聚焦多模態(tài)模型在空間、結(jié)構(gòu)、路徑等方面的綜合推理能力 , 被AI社區(qū)視為是衡量“具身智能”進展的新興測試標準之一 。
SpatialBench不僅測試模型已知的知識 , 還測試模型在二維和三維空間中“感知”和操控抽象概念的能力 , 這對具身智能的落地尤為關鍵 。
SpatialBench榜單顯示 , Qwen3-VL-235B和Qwen2.5-VL-72B分別斬獲13.5和12.9分 , 領先于Gemini 3.0 Pro Preview(9.6) 、GPT-5.1(7.5)、Claude Sonnet 4.5等海外頂尖模型 。
然而 , AI大模型的整體表現(xiàn)距離人類仍有差距 , 人類基準線約為80分左右 , 可專業(yè)處理電路分析、CAD 工程和分子生物學等復雜空間推理任務 , 目前大模型還無法完全自動化完成此類工作 。
據(jù)悉 , Qwen2.5-VL于2024年開源 , Qwen3-VL是阿里在2025年開源的新一代視覺理解模型 。
Qwen3-VL在視覺感知和多模態(tài)推理方面實現(xiàn)重大突破 , 在32項核心能力測評中超過Gemini2.5-Pro和GPT-5 , 不但可調(diào)用摳圖、搜索等工具完成“帶圖推理” , 也可以憑借一張設計草圖或一段小游戲視頻直接“視覺編程” 。
同時 , Qwen3-VL專門增強了3D檢測能力 , 可以更好地感知空間 , 基于Qwen3-VL , 機器人更好地判斷物體方位、視角變化和遮擋關系 , 實現(xiàn)遠處蘋果的精準抓取 。
目前 , Qwen3-VL已開源不同版本 , 包括2B、4B、8B、32B等密集模型以及30B-A3B、235B-A22B等MoE模型 , 每個模型都有指令版和推理版兩款 , 是當下最受企業(yè)和開發(fā)者歡迎的開源視覺理解模型 。
同時 , Qwen3-VL模型也已上線千問APP , 用戶可免費體驗 。
榜單鏈接:https://spicylemonade.github.io/spatialbench/
— 完 —
量子位 QbitAI · 頭條號
關注我們 , 第一時間獲知前沿科技動態(tài)
推薦閱讀
















- 日本1.4納米:明年研發(fā)、后年建廠!1納米也在考慮中!
- 這就尷尬了,小米被黑的這么慘,手機、汽車銷量卻創(chuàng)新高
- 說實話,芯片、內(nèi)存大漲價,手機銷量下跌,對小米的影響不大
- 華為麒麟9030參數(shù)出爐:9核心、Mate 80系列首發(fā)
- 4699 元起!華為發(fā)布 Mate 80 系列:全能、直屏,還有性價比
- 天網(wǎng)、地網(wǎng)、無網(wǎng)通吃!余承東:華為Mate 80系列通信地表最強
- 三星電子在年度高管調(diào)整中晉升161人 AI、半導體高管也有調(diào)整
- 千問、靈光、夸克,阿里AI瘋狂“補課”
- 微軟Win11菜單瘦身:界面更清爽、性能仍待優(yōu)化
- 今年手機市場的懸念:小米、VIVO、蘋果,誰會成中國的第一