
文章圖片
【SIGGRAPH Asia 2025 | 只用一部手機創建和渲染高質量3D數字人】
文章圖片
文章圖片
文章圖片
文章圖片
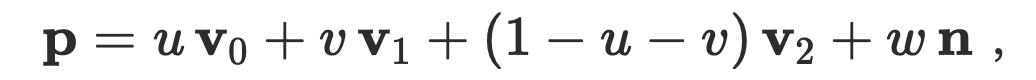
文章圖片

文章圖片
文章圖片
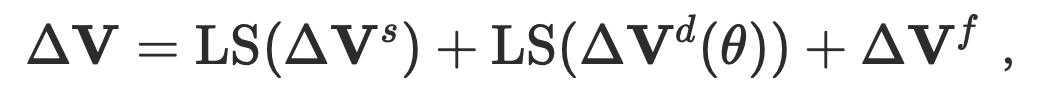
文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片
在計算機圖形學、三維視覺、虛擬人、XR 領域 , SIGGRAPH 是毫無爭議的 “天花板級會議” 。SIGGRAPH Asia 作為 SIGGRAPH 系列兩大主會之一 , 每年只接收全球最頂尖研究團隊的成果稿件 , 代表著學術與工業界的最高研究水平與最前沿技術趨勢 。
我們是淘寶技術 - Meta 技術團隊 , 在 3D、XR、3D 真人數字人和三維重建等方向擁有深厚的技術積累和業務沉淀 , 我們自研了專業的多視角拍攝影棚 , 在今年 CVPR 2025 會議上作為 Highlight Paper 發表了 TaoAvatar, 并在淘寶未來旗艦店中實現了業內首個 3D 真人導購體驗 , 下面視頻展示了杭州西溪園區 C 區淘寶未來旗艦店的精彩瞬間 , 歡迎大家到來訪園區進行體驗 。
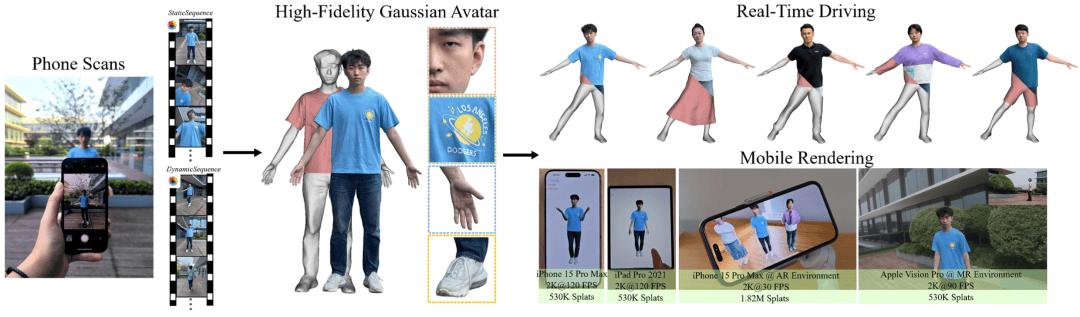
今年我們團隊迎來另一個重要里程碑:我們撰寫的針對移動端的高保真實時 3D 數字人重建與渲染系統論文首次登錄了國際頂級計算機圖形學會議 SIGGRAPH Asia!這是我們技術實力的一次正式 “官宣” , 也是我們在 3D/XR 方向長期投入的階段性成果展示 。
我們研發的基于手機單目視頻生成高保真且可實時驅動的 3D 數字人的系統名叫 HRM2Avatar, 不同于依賴多相機陣列或深度硬件的方案 , 其在普通手機拍攝條件下重建人物形體、服飾結構以及細節級外觀表達 , 并支持在移動設備上實時渲染與動畫驅動 。 系統采用顯式服裝網格與高斯表示相結合的建模方式:網格提供穩定的結構與可控性 , 高斯則用于呈現褶皺、材質和光照變化等細節 , 使虛擬人在不同姿態下依舊保持連續、自然的外觀表現 。 此外 , 基于輕量化推理設計與移動端渲染優化策略 , 生成的數字人可在手機、頭顯等移動設備上流暢運行 。 實驗結果表明 , 我們的系統在視覺真實感、跨姿態一致性以及移動端實時渲染之間取得了良好平衡 。
論文主頁:https://acennr-engine.github.io/HRM2Avatar/ TaoAvatar 主頁:https://pixelai-team.github.io/TaoAvatar/ Taobao3D GitHub 倉庫:https://github.com/alibaba/Taobao3D MNN GitHub 倉庫:https://github.com/alibaba/MNN問題定義
HRM2Avatar整體框架
想生成一個真實又能動的 3D 數字人 , 聽起來很酷 , 但門檻非常高 , 現在高精度建模方式如 TaoAvatar、CodecAvatar 等 , 通常需要使用昂貴的三維重建設備 。 這些系統確實效果好 , 但搭建復雜、調試困難 , 還很難攜帶出實驗室 , 普通人幾乎無法自己操作 。 而我們正是從 “普通人也能用” 的角度出發 , 重新思考:如何只用一部手機 , 就能創建和渲染高質量 3D 數字人?
但是僅使用手機條件下 , 會存在多個關鍵難題:
幾何與局部細節缺失:由于手機拍攝距離遠、視角有限 , 衣物褶皺、材質結構、頭發等高頻細節難以穩定恢復; 外觀-動作耦合:外觀變化、布料形變、光照變化與姿態變化混雜 , 導致姿勢相關的形變與光照難以獨立建模; 實時推理受限:盡管神經渲染與 3DGS 表示提升了表達能力 , 但許多方法仍依賴高性能桌面級 GPU 實現實時驅動 , 在移動端設備上運行仍具有挑戰 。因此 , 如何在僅依賴手機單目輸入的條件下 , 重建高保真、可動畫的數字人 , 并實現移動端實時渲染 , 仍是一個尚未充分解決的問題 。
方法概覽
基于上述挑戰 , 我們提出了針對移動端的高保真實時 3D 數字人重建與渲染系統 HRM2Avatar , 核心采用兩階段采集方式、顯式衣物網格表示與基于高斯的動態細節建模 , 并結合面向移動端設備的高效渲染優化策略 , 在保證外觀質量與動態表現的同時 , 實現從掃描到實時驅動的完整重建流程 。
HRM2Avatar 流程概覽
核心模塊包括:
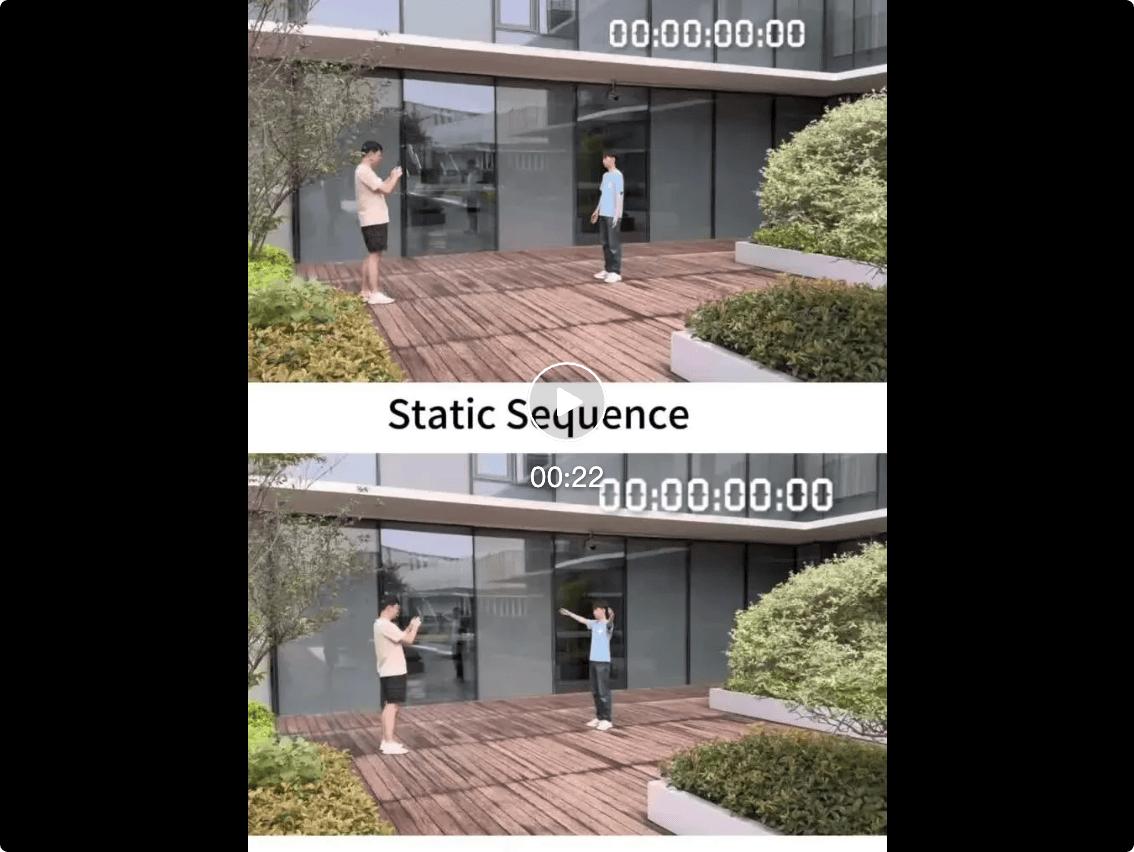
手機掃描采集 , 采用靜態與動態結合的手機掃描方式 , 同時獲取全身結構與局部細節變化 , 為后續動態建模提供可靠外觀與姿態變化信號 。 表征與重建 , 系統構建可動畫的穿衣人體模型 , 并采用顯式網格與高斯的混合表達方式:網格提供穩定的結構與動畫一致性 , 而高斯用于建模隨姿態變化的細節與光照(姿態相關的形變和陰影建模) , 從而在運動過程中保持材質、細節與視覺一致性 。 移動端渲染 , 結合輕量化推理模型和面向移動設備的渲染優化策略 , 生成的數字人可在手機等設備上實現實時驅動與高質量顯示 。采集與預處理
系統在進入重建階段前 , 需要將手機掃描得到的視頻轉換為結構一致、可用于建模的輸入數據 , 過程包括拍攝協議、相機與人體參數初始化 , 以及服飾網格提取 。
拍攝協議
采集采用雙序列拍攝方式 , 包括靜態掃描和動態掃描 。 靜態掃描階段 , 用戶保持相對固定姿態 , 手機圍繞身體移動拍攝 , 覆蓋全身結構和局部紋理細節 。 動態掃描階段 , 用戶執行自然動作 , 用于捕捉衣物褶皺、遮擋變化和光照響應 。 該流程無需額外硬件或標記 , 可在單目條件下提供重建與動態建模所需的信號 。
初始相機參數和姿態估計
系統對采集到的靜態序列和動態序列進行處理 , 以獲得后續重建所需的相機參數和初始人體姿態估計 , 其中靜態序列是核心階段 。
靜態序列
靜態序列由近景(Close-up)與全身(Full-body)兩類圖像組成 , 它們承擔不同但互補的作用:
全身幀全身視角提供穩定的人體輪廓與結構 , 使系統能夠估計初始人體姿態參數 。 該姿態不僅用于靜態階段的重建 , 還作為動態序列處理時的參考姿態來源 。
近景幀此類幀主要覆蓋局部區域 , 如頭部、胸部或衣物細節 , 視野中人體結構比例有限 , 因此通常無法檢測到可靠的人體關鍵點 , 也無法直接推斷出合理姿態 。 然而 , 這些圖像對于恢復高頻紋理和幾何區域至關重要 。 為了使這些幀參與建模 , 我們對近景與全身幀聯合運行SfM , 并利用跨尺度視角一致性來穩定近景幀的相機軌跡 。
通過聯合利用近景與全身幀 , 系統既獲得了穩定的相機軌跡 , 也為后續網格重建與動態建模奠定了可靠的初始化條件 。
動態序列
在動態序列中 , 系統不再更新形體參數 , 而是直接使用靜態階段得到的 SMPL-X 身體參數作為固定模板 。 在此基礎上 , 僅對每一幀估計姿態變化 , 用于捕獲隨動作產生的衣物變形、遮擋變化和光照響應 。
服飾網格提取
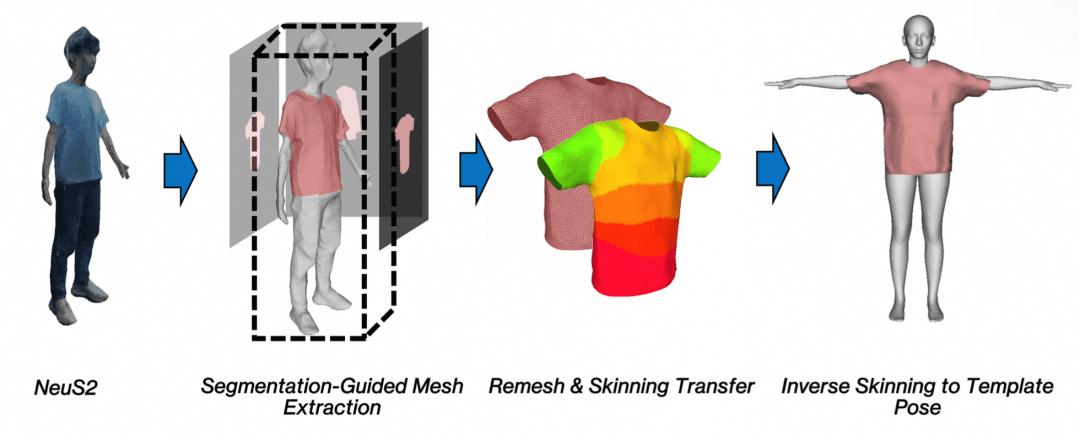
HRM2Avatar 服飾網格提取流程
在獲得相機與姿態初始化后 , 系統從靜態序列中構建可動畫的穿衣人體網格 。 這一過程包括以下步驟:
1. 幾何重建 , 使用靜態序列圖像運行 NeuS2 , 生成服飾表面的幾何代理 , 用于提供連續且高質量的體表結構 。
2. 服裝區域提取 , 通過語義分割引導從代理幾何中提取衣物區域 , 確保服飾邊界清晰 , 避免身體與衣物表面混合 。
3. 重拓撲與蒙皮綁定 , 對提取的服飾網格進行重網格化 , 并將其轉移至與身體一致的蒙皮權重體系 , 使其具備一致的動畫控制結構 。
4. 綁定對齊 , 將綁定后的網格逆皮膚回歸到綁定模板姿態 , 得到拓撲干凈、結構一致、可綁定動畫的最終服飾網格 。
生成的穿衣人體網格作為幾何基底參與后續混合表示學習 , 并用于支持姿態變化下的外觀建模與實時動畫驅動 。
實時可驅動的數字人重建
為了重建實時可驅動的數字人 , 我們著重從混合表示 , 幾何生成 , 動態光照建模 , 訓練流程 , 輕量網絡蒸餾五個方面進行了細致的考慮和設計 。
混合表示
HRM2Avatar 混合表達
在穿衣人體網格上 , 我們為每個三角形附著高斯點 , 構建混合數字人表征:
1. 高斯位置與綁定
每個高斯用重心坐標和法向在三角形上定位:
2. 協方差構造
高斯的尺度由三角形雅可比矩陣、旋轉和縮放組合得到:
3. 可見性與語義分區
每個高斯關聯可見性標記 , 僅在三角形朝向視點時參與渲染 。 基于語義分割 , 將高斯分為兩個區域:
頭發區域 , 使用 3DGS 建模軟性過渡 , 非頭發區域 , 使用 2DGS 貼合網格表面 。該混合表示在保持結構約束的同時 , 為后續姿態相關的形變與光照建模提供了可控的高斯參數空間 。
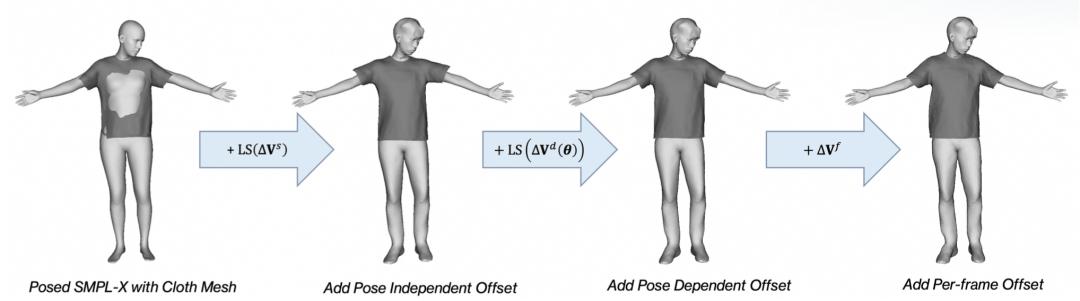
幾何生成
HRM2Avatar 幾何生成模塊
其中偏移量定義為:
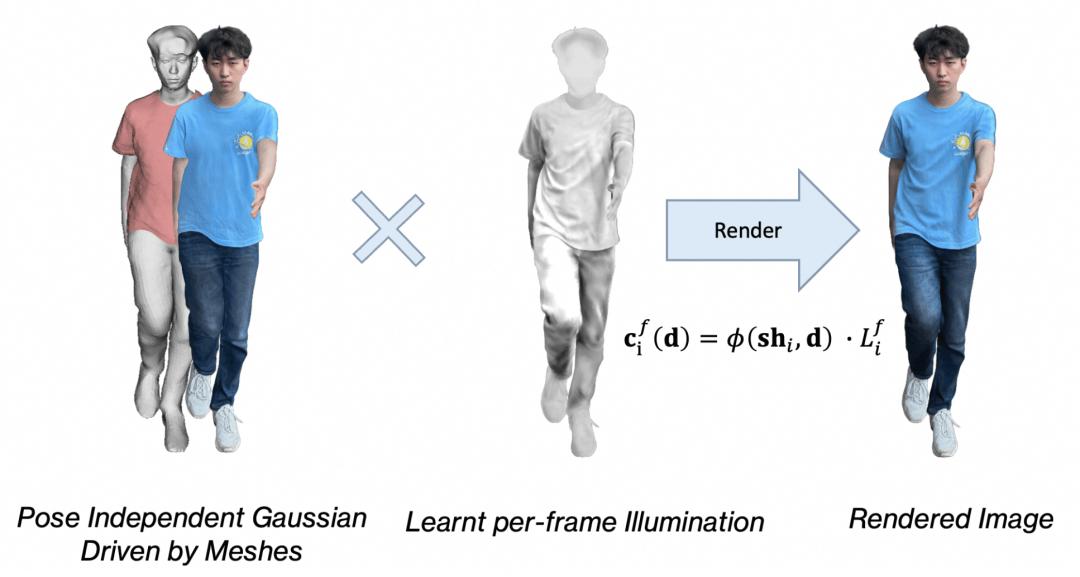
動態光照建模
HRM2Avatar動態光照建模
人體姿態變化會導致光照分布發生變化 , 例如陰影位置偏移、局部亮度變化等 。 為建模這種隨動作變化的光照效應 , 我們引入一個輕量化的單通道姿態相關光照項 , 用于描述運動驅動的光照變化特征 。
渲染過程中 , 高斯的外觀屬性會與該光照項進行調制 , 最終顏色計算如下:
訓練流程
HRM2Avatar訓練流程
系統的完整優化過程如圖所示 。 訓練階段同時使用近景與全身圖像作為監督信號 , 其中近景提供更強的外觀約束 , 全身圖像用于保持整體一致性 。 模型渲染結果與輸入圖像通過多種監督方式進行對齊 , 包括:
顏色一致性監督 , 語義掩碼約束 , 身體與服飾區域的碰撞約束 , 幾何與參數平滑正則化 。在優化策略上 , 高斯屬性、幾何偏移與光照參數從零開始訓練 , 而相機姿態與人體姿勢只進行輕量微調 , 用于消除殘余配準誤差 , 而非重新估計結構 。 經過訓練 , 系統得到姿態無關的高斯表示 , 以及針對每一幀的幾何形變與光照變化 , 從而支持后續實時驅動與渲染 。
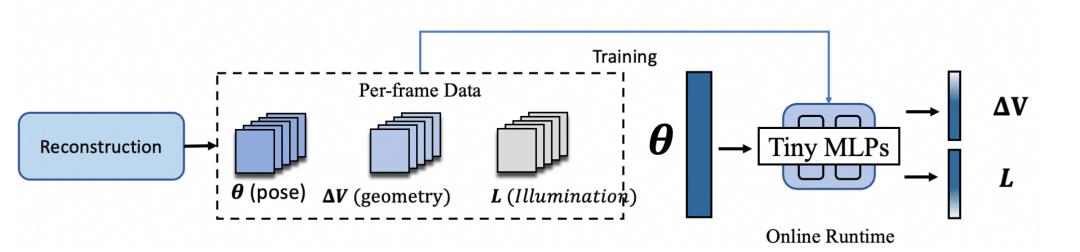
輕量網絡蒸餾
HRM2Avatar網絡蒸餾模塊
在重建階段 , 我們已經獲得了逐幀的姿態、幾何偏移和光照參數 。 基于這些結果 , 我們采用蒸餾方式訓練一個輕量級的預測網絡 , 使其學習姿態到幾何形變與光照變化的映射關系 。 訓練完成后 , 系統不再依賴逐幀重建數據 , 僅輸入姿態即可實時預測對應的幾何偏移與光照參數 , 從而支持移動端的實時驅動與渲染 。
高性能移動端實時渲染
為了實現移動端實時運行 , 我們對渲染階段進行了系統性優化 , 包括層級裁剪、高效投影、量化排序和基于顯卡硬件的加速渲染 。 該設計避免了傳統 3DGS 渲染中高帶寬、高冗余計算的瓶頸 , 使最終數字人能夠在手機上穩定運行 。
HRM2Avatar實時渲染模塊
層級裁剪
為了盡量減少無效高斯的冗余計算 , 系統采用多級裁剪策略:
網格級視錐裁剪(CPU 側):剔除完全不在視野范圍內的身體部件; 三角片級背面裁剪(GPU 側):丟棄背對攝像機的三角面; 高斯級視錐裁剪(GPU 側):進一步剔除不可見的高斯實例 。這種多級裁剪方式顯著減少了需要參與排序與渲染的高斯數量 , 極大地提升了渲染效率 。
投影
對于參與渲染的高斯點 , 我們采用基于需求的精簡投影流程:
按需解碼存儲塊 , 避免一次性展開全部數據; 優先提取空間位置和索引用于可見性判斷; 僅對可見高斯點進行完整屬性解碼(旋轉、尺度、不透明度、球諧系數等) 。這種按需處理方式有效降低了解碼帶寬開銷 。
排序
渲染高斯需要按深度順序合成 。 我們采用量化排序以提升效率:
將連續深度范圍映射至緊湊區間; 使用 16 Bit 或 12 Bit 深度存儲替代 32Bit 浮點; 結合 GPU 并行 Radix Sort 與硬件 Wave 操作加速排序 。 該方法在保持排序精度的同時 , 大幅減少排序負擔和顯存帶寬使用 。渲染
最終渲染階段使用 GPU 的硬件柵格化 , 對每個高斯生成面元并進行屏幕合成 。 為進一步提升性能和視覺質量 , 我們采用:
自適應面元縮放:在保證外觀一致的前提下縮小面元面積; 基于透明度修剪:剔除貢獻極小的邊界像素; 反向透明度估計:根據高斯分布推斷最小必要面元尺寸 。這些策略使系統在有限算力環境下仍能保持高質量渲染 。
通過上述優化 , 數字人渲染不依賴實時體渲染混合或高開銷著色器 , 而采用緊湊、高度可并行、緩存友好的繪制方式 , 最終達成在移動端平臺上的實時表現 。
結果展示
AR|MR效果
與現有方法對比
我們在自構的服飾人體數據上對 HRM2Avatar 進行了系統評測 , 并與現有單目輸入條件下的可動畫數字人方法進行了對比 , 包括基于隱式場、可動畫神經表示以及基于高斯表示的方案 。 對比實驗主要關注兩個方面:靜態重建質量與姿態驅動下的外觀一致性 。
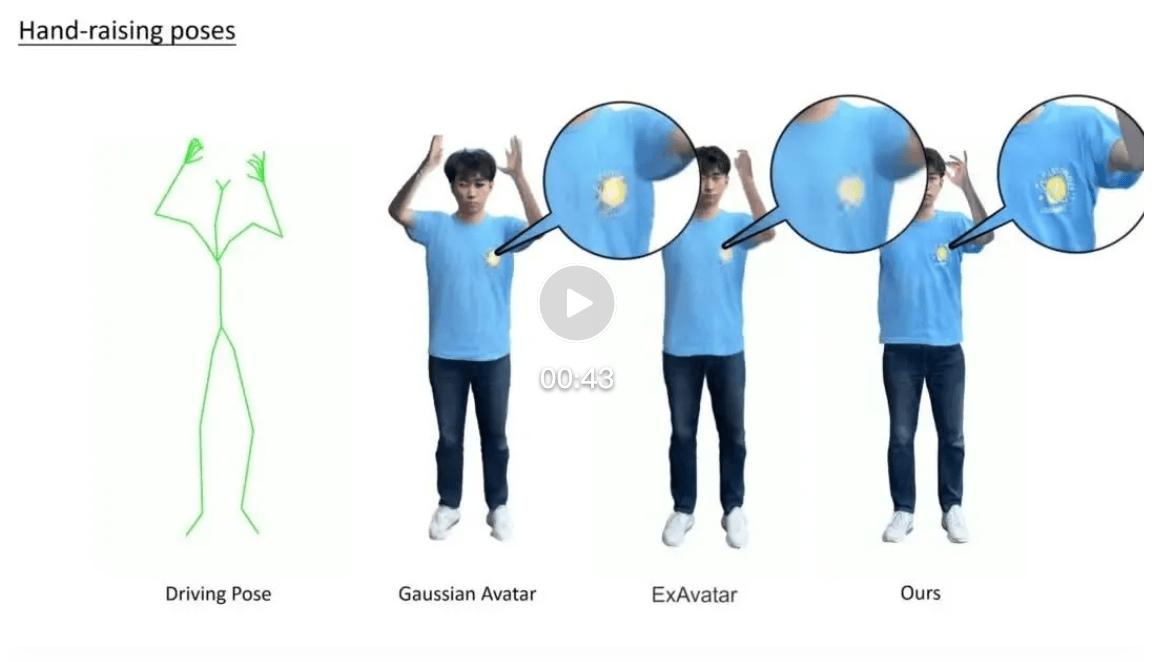
從定性結果可以觀察到 , 在僅使用單目輸入的條件下 , 現有方法在衣物邊界、高頻紋理和細節區域(如褶皺、印花、層次結構等)往往表現較弱 , 容易出現模糊化或紋理漂移 , 而 HRM2Avatar 依托顯式衣物網格與高斯表示相結合的結構 , 能夠保持更穩定的視覺細節和結構表達 。 尤其在跨視角與跨姿態驅動條件下 , 我們的方法在外觀一致性上表現更穩定 , 未出現明顯的拉伸或表面扭曲偽影 。
在客觀指標上 , 我們使用 PSNR、SSIM 和 LPIPS 對方法進行量化比較 。 結果表明 , HRM2Avatar 在所有指標上均取得更優表現:在 LPIPS 上分數更低 , 而在 PSNR 和 SSIM 上更高 , 顯示出更清晰的紋理保留和更穩定的結構一致性 。 值得注意的是 , 即使在新的姿態條件下 , 這一優勢仍然保持 , 說明所建模的姿態相關的外表建模能夠有效避免紋理漂移并提升跨姿態一致性 。
我們進一步在 Neuman 數據集上評估了 HRM2Avatar 的泛化性能 。 該數據集包含更復雜的服飾結構與動態動作模式 , 可用于驗證方法在非自采場景下的適應能力 。
在 Neuman 數據集上 , 我們進一步評估了模型的泛化表現 。 該數據集包含更豐富的動態動作與服飾外觀變化 , 可用于檢驗模型在非自采場景下的穩定性 。 從定性結果來看 , 現有方法在快速動作或較大姿態變化條件下 , 容易出現紋理模糊、漂移或表面結構不穩定等現象 , 而HRM2Avatar 能保持較為穩定的外觀呈現 , 服飾細節在動作驅動過程中仍具備可辨識度 。 同時 , 在袖口、褶皺等高頻區域 , 模型能夠維持視覺上連續且合理的外觀變化 。 值得注意的是 , 即使目標姿態未在掃描序列中出現 , 基于兩階段采集策略學習的姿態相關的外表建模仍能生成與動作一致的外觀響應 , 沒有出現明顯視覺斷層或重建不連續情況 。
總體而言 , Neuman 數據集實驗表明 , 在具有動作變化和服飾結構復雜性的場景中 , 模型能夠保持重建外觀與姿態一致性 , 并具備跨姿態條件下的穩定表現 。
消融實驗
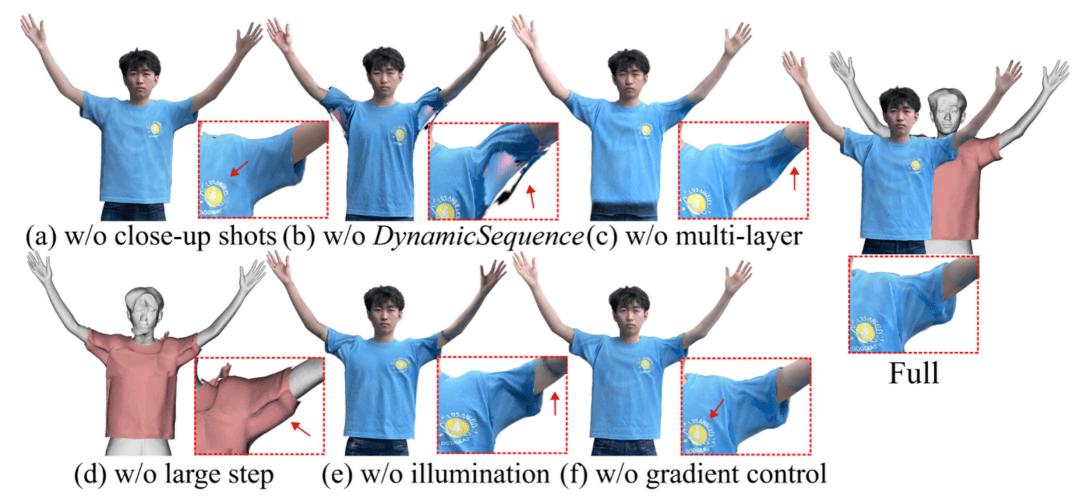
我們進一步進行了消融實驗 , 以驗證系統中各個組成模塊對最終效果的影響 。 實驗依次移除關鍵設計 , 包括顯式服裝網格、姿態相關的外表建模以及兩階段掃描協議 , 并在相同條件下比較生成結果 。
從定性結果可以看到 , 當移除顯式服裝網格時 , 重建表面在服飾邊界區域出現不連續或拓撲模糊的情況 , 且局部細節難以保持一致 。 進一步移除姿態相關的外表建模后 , 模型在動作變化過程中易產生紋理漂移或不穩定現象 , 尤其在手臂抬起等較大姿態變化階段更為明顯 。 此外 , 若不采用兩階段掃描采集策略 , 僅依賴單序列輸入 , 模型在訓練階段難以獲得可靠的靜態參考 , 表現為紋理分辨率下降以及動作驅動時局部外觀變化不合理 。
總體來看 , 消融實驗表明 , 各設計模塊在系統中均發揮必要作用:顯式服裝網格用于提供穩定的拓撲結構 , 姿態相關的外表建模對于跨姿態一致性至關重要 , 而兩階段掃描策略為重建細節和外觀穩定性提供有效約束 。
性能表現
我們評估了 HRM2Avatar 在移動端設備上的運行表現 , 并在 iPhone 15 Pro Max 與 Apple Vision Pro 上進行了實時驅動測試 。 實驗使用相同渲染配置 , 并控制高斯數量以驗證模型在不同數字人規模下的運行穩定性 。
在單個數字人配置下(約 53 萬高斯點) , 系統能夠在 iPhone 15 Pro Max 上以 2K 分辨率、120 FPS 穩定運行;多數字人場景下仍可保持實時表現 , 例如同時渲染三個數字人時 , 可達到 2K@30 FPS 。 在 Apple Vision Pro 上 , 系統同樣實現了 2K@90 FPS 的實時渲染效果 。
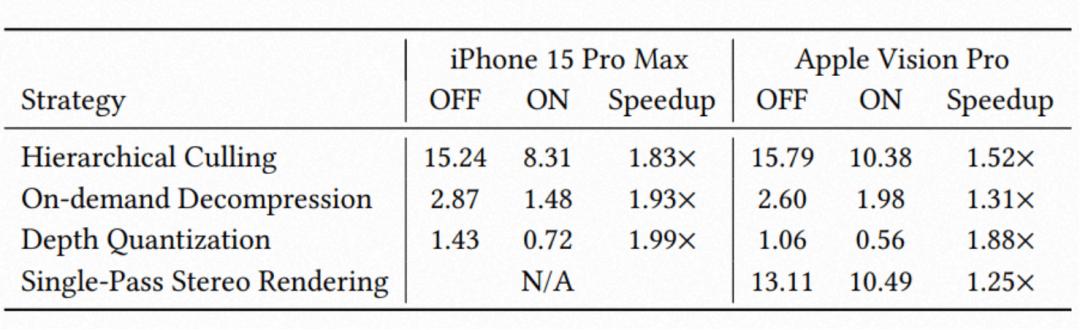
我們進一步分析了各渲染優化策略對系統性能的影響 , 包括分級裁剪(Hierarchical Culling)、按需屬性解碼(On-demand Decoding)、深度量化排序(Depth Quantization)以及單通道視圖渲染等策略 。 實驗結果表明 , 這些設計能夠有效降低計算與內存開銷 , 使混合的高斯和網格表示能夠在移動硬件上實現實時驅動 。
整體來看 , 性能測試表明 HRM2Avatar 能夠在移動設備上維持穩定的實時運行表現 , 同時兼顧高分辨率渲染質量與系統響應延遲 , 為實際交互場景部署提供可行性基礎 。
總結與展望
圍繞 “讓普通人也能擁有高質量數字人” 這一目標 , 我們提出了 HRM2Avatar , 一種基于手機單目掃描 , 即可生成可動畫、高保真數字人的系統方案 。 在真實應用場景中 , HRM2Avatar 能夠應對不同服飾結構、姿態變化與光照條件 , 在穩定性和一致性方面表現良好 , 為移動端數字人應用提供了可行技術路徑 。
我們也客觀看待當前技術階段 , 作為一項前沿探索 , HRM2Avatar 仍然存在進一步優化空間 。 例如對于結構復雜或非固定拓撲的服飾(如飄帶、寬松衣物等) , 重建精度仍有改善余地 , 此外在極端光照或動態遮擋場景下 , 效果仍有提升空間 。 這些也正是我們下一階段持續投入攻關的方向 。
HRM2Avatar 并不是 “終點” , 而是我們推動:數字人從專業設備走向普通用戶 , 從實驗室能力走向真實應用場景過程中的一個重要里程碑 。 我們相信 , 隨著算法、模型工程與硬件能力的共同進化 , 高質量、實時、可普及的數字人體驗 , 將不再遙遠 。
團隊介紹
我們是大淘寶技術 Meta Team , 負責面向消費場景的 3D/XR 基礎技術建設和創新應用探索 , 通過技術和應用創新找到以手機及 XR 新設備為載體的消費購物 3D/XR 新體驗 。 團隊在端智能、商品三維重建、3D 引擎、XR 引擎等方面有深厚的技術積累 , 同時在 OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI、SIGGRAPH 等頂級學術會議和期刊上發表了多篇論文 。
推薦閱讀












- 16GB+512GB能用五年,2025“降價很猛”的3款手機,幾乎沒有差評
- 谷歌微軟蘋果瓜分前三!2025年世界500強發布:華為第50、小米第354
- L4級自動駕駛企業白犀牛宣布2025年融資破1億美元
- ?華為海思芯片排第六,2025年第三季度手機處理器市場份額出爐
- 2025我國AI核心產業將破萬億,現存相關企業超491萬家
- 這不是你常見的手機:這是2025年最大膽的智能手機創意
- 換性能手機無需太貴,2025“最值得撿漏”的高配手機,2000內能入
- 佰維存儲:2025年AI眼鏡收入增長超過500%
- 中國領跑開源AI:2025大模型發展新格局
- 2025年電腦外設年終盤點:性價比與產品力的雙重競技