
文章圖片
文章圖片
文章圖片

文章圖片
智東西
編譯 | 王欣逸
編輯 | 程茜
智東西12月19日消息 , 12月11日 , 蘋果發表論文介紹了3D生成模型SHARP , 宣稱在標準GPU上 , 該模型能夠以不到1秒的時間將單張圖像重建為逼真的3D場景 。 目前 , 該模型已開源 。
用戶僅需輸入一張普通照片 , 該模型即可通過神經網絡一次性預測出整個場景的3D高斯表示參數 , 整個生成過程在標準GPU上完成僅需不足一秒 , 隨后還能實時渲染出高分辨率、照片級真實感的相鄰視角圖像 。 此外 , SHARP生成的3D場景具有絕對尺度的度量特性 , 能夠支持精確的相機位移操作 。
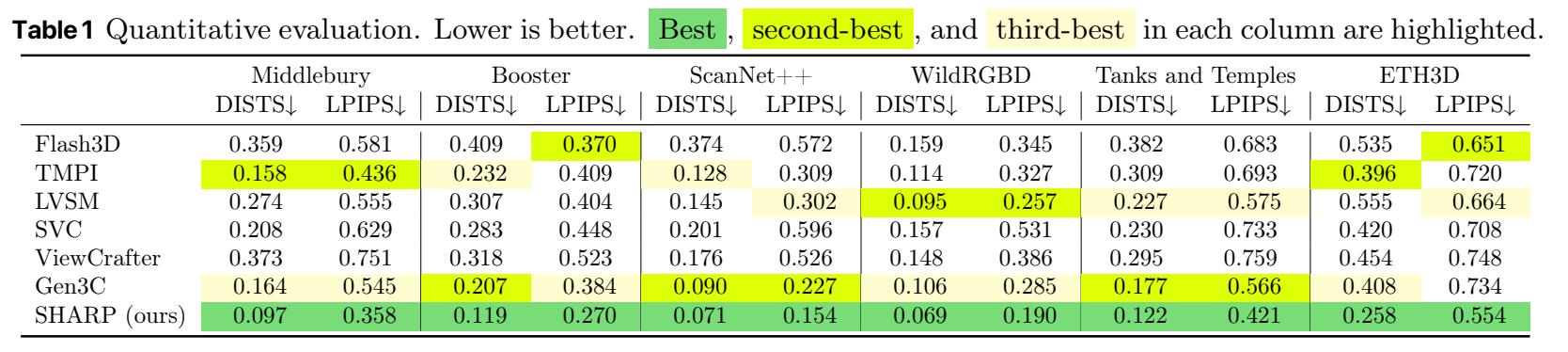
定量評估顯示 , SHARP在不同數據集上展現出強大的零樣本泛化能力 , 在多個數據集上實現了新的技術突破 , 與現有最佳模型相比 , LPIPS指標(感知相似性)降低了25-34% , DISTS指標(結構相似性)降低了21-43% , 還將合成時間縮短了三個數量級 , 并支持以每秒100幀高分辨率渲染鄰近視圖的3D表征 。
不少開發者對該模型進行了體驗 。 其中 , 有網友將其置于Vision Pro內使用 , 僅需單張圖片就實現了身臨其境的效果 , 生成畫面的精細度也比較高 。
還有網友上傳了一張油畫 , 該模型最終生成了一個位置關系準確、畫面完整的3D場景 。
其他網友評價稱 , 該模型無法生成場景中不可見的部分 , 不過它的最大優勢在于生成速度 , “MacBook Pro 只需幾秒鐘(就能完成生成)……” 。
該模型的詳細信息已發布在arXiv上 , 題為《SHARP:不到一秒的單圖像視角合成(Sharp Monocular View Synthesis in Less Than a Second)》 。
論文地址:https://arxiv.org/abs/2512.10685
開源地址:
GitHub:https://github.com/apple/ml-sharp
【蘋果開源新模型!一秒鐘讓照片變3D世界】Hugging Face:https://huggingface.co/apple/Sharp
一、保真度提高約20%-40% , 合成時間縮短三個數量級研究人員用多個數據集對SHARP模型進行評估 , 主要關注模型的兩個指標:LPIPS和DISTS , 以考察模型的合成圖像與真實圖像之間的結構相似性 , 符合人主觀感受的程度 。 這兩個數據越小 , 性能越優 。
在基線模型上 , 研究人員選取了一些現有的前沿模型 , 分別為:基于3D高斯分布的Flash 3D模型;使用多平面圖像的TMPI模型;基于圖像回歸的LVSM模型;采用擴散模型的穩定虛擬相機(SVC)、ViewCrafter和Gen3C 。
定量評估顯示 , SHARP在所有數據集中的表現均為最佳 , 打敗所有模型 。 相較現有最佳模型 , SHARP的LPIPS指標降低了25-34% , DISTS指標降低了21-43% 。
研究人員對該模型的單圖像合成任務性能進行了評估 , 結果顯示 , 在單個GPU上 , SHARP在保持高圖像保真度的同時 , 合成時間也位列第一梯隊 。 相較于同等質量的模型 , SHARP模型的合成時間縮短了三個數量級 , 這體現了其在效率和效果上的優勢 。
在不到1秒的時間里 , 該模型不僅能生成3D內容 , 還能以每秒100幀以上的速度渲染高分辨率的局部視圖 。 從結果來看 , SHARP細節處理清晰 , 結構精細 , 第一張圖的主體和背景分離處理得很干凈 , 第二張圖顏色和形狀穩定性比較出色 , 第三張圖動物的毛發根根分明 。
二、能實時渲染、預測高分辨3D表征 , 無法生成不可見部分視角合成研究經歷了從早期基于多圖像幾何建模的經典方法 , 到深度學習時代以神經輻射場為代表的隱式表示突破 , 再到近年來顯式高效渲染技術(如3D高斯潑濺)的發展歷程 。
此前 , 大多數高斯潑濺方法需要從不同視角拍攝同一場景的數十甚至數百張圖像 , SHARP模型則專注于單張圖片的3D場景生成 , 它僅通過神經網絡的一次前向傳播 , 就能從單張照片預測出完整的3D高斯場景表征 。
SHARP模型的訓練過程包括合成數據訓練和自監督微調兩個階段:在第一階段 , 研究人員使用具有完美圖像和深度真實標簽的合成數據對模型進行訓練 , 學習3D重建的基本原理 。 在第二階段 , 研究人員讓該模型在沒有視差合成真實標簽的真實圖像上進行自監督微調 , 通過生成偽真實標簽來適應真實圖像 , 提高模型在真實世界圖像上的性能 。
研究團隊對SHARP模型做出了三點創新:第一點是一種可進行端到端訓練的架構 , 這一架構可預測高分辨率3D表征;第二是推出了魯棒高效的損失函數配置 , 研究人員精心選取了一系列損失函數 , 在保障訓練穩定性、抑制常見視覺偽影的同時 , 將視角合成質量作為優化重點;第三是引入一個簡潔的深度對齊模塊 , 這一模塊能夠有效解決訓練過程中的深度歧義問題 。
SHARP模型包含四個可學習模塊:一個用于特征提取的預訓練編碼器、一個生成兩個獨立深度層的深度解碼器、一個深度調整模塊以及一個優化所有高斯屬性的高斯解碼器 。 可微分高斯初始化器和組合器為最終的3D表示組裝高斯元素 , 預測出的高斯被渲染至輸入視圖和新穎視圖 , 以進行損失計算 。
在優化和評估過程中 , SHARP模型使用了多種損失函數來優化合成視圖的質量 , 包括渲染損失、深度損失和正則化損失等 。 通過這些損失函數的組合 , 模型能夠生成高質量的3D表示 , 并支持實時渲染 。
基于以上技術 , SHARP模型實現了無需依賴多張圖像或耗時的逐場景優化過程 , 即可重建出可信的3D場景 。 不過該方法存在一定的權衡:SHARP能精確渲染鄰近視角 , 但無法合成場景中完全不可見的部分 。 這意味著用戶不能過度偏離原照片的拍攝機位 。
結語:3D場景生成門檻再降SHARP模型在單圖像視點合成領域取得了顯著進展 , 該模型在單次前向傳播的同時 , 完成了從2D圖片理解、3D幾何重建到細節優化的全過程 , 最終輸出一個能實時渲染的3D場景模型 。
在應用上 , 通過實時渲染高保真的3D場景 , SHARP模型或將為VR/AR應用提供更加沉浸式的體驗 , 為游戲、電影、建筑等行業提供更多可能性 。 研究團隊稱 , 他們還將拓展現有方法論 , 通過結合擴散模型等方法 , 支持更遠距離視點的合成 。
推薦閱讀












- 蘋果新iMac曝光,首次采用OLED屏
- 至少7款新iPhone!蘋果2027秋季前調整發布節奏
- 在這個開源「從夯到拉」榜單,我終于明白中國 AI 為什么能逆襲
- 基于真實數據和物理仿真,國防科大開源具身在線裝箱基準RoboBPP
- 日本iPhone已開放第三方應用商店 中國網友:30%蘋果稅還要交多久
- 消息稱蘋果首款可折疊iPhone初期將面臨供應問題 2027年才會緩解
- 臺積電2nm芯片時代來臨:蘋果A系列領銜,GAA架構引領性能革命
- 蘋果官宣:明年對 iOS 系統增加多個廣告位
- 豆包的新模型,想給“豆包電腦”打個樣?
- 曝蘋果放棄VR頭顯,轉向AI眼鏡!附未來兩年最全產品圖