
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片
文章圖片

文章圖片
文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片

文章圖片
文章圖片

文章圖片

【導語:摩爾線程的報告 也是預告】
在高科技領域 , 中國唯二還與世界最高水平有較大差距的 , 一個是光刻機 , 另一個就是GPU芯片 , 而這兩者正是AI之爭的關鍵基石 。
幸運的是 , 在“算力即國力”的號召下 , 國產GPU芯片近年來呈現出井噴之勢 , 眾多品牌紛紛拿出豐富、強大的產品矩陣 , 展現了不俗的實力 。
在這其中 , 成立僅僅5年的摩爾線程 , 無疑是關注度最高的品牌 。
一方面 , 摩爾線程創始人張建中曾擔任NVIDIA全球副總裁、中國區總經理 , 自帶光環 。
另一方面 , 摩爾線程的MTT S80 , 至今仍是唯一能夠在公開渠道買到的國產游戲顯卡 , 而且每月都在更新驅動 。
5年來 , 摩爾線程基于自研的全功能GPU芯片 , 發展出了軟硬兼備的全線產品堆棧 , 覆蓋幾乎所有GPU相關領域 。
從大家最熟悉的游戲顯卡(S80/S70)到專業視覺加速顯卡(X300/S50)、數字辦公顯卡(S30/S10);
從算力本(AIBOOK)到臺式機(智娛摩方);
從算力加速卡(S5000/S4000)到服務器(MCCX D800 X1/X2)、智算中心(夸娥集群);
從基礎軟件、AI套件到云原生軟件、圖形與多媒體軟件;
從AI模型(MUSAChat)到AI應用(魔筆馬良/魔筆天書)……
所有這些 , 摩爾線程都已涉足 , 而且都干得有聲有色 , 在眾多傳統與新興領域都可以看到摩爾線程活躍的身影!
隨著IPO上市成功 , 關注摩爾線程的已經不僅僅是科技行業 , 而是得到了全民矚目 。
所以 , 摩爾線程是時候做一次總體匯報 , 也是時候展望一下未來了!
這就是摩爾線程的第一屆MUSA開發者大會 , 可以說這次大會干貨之豐富 , 恐怕超出了每一位與會者的意料與期待!
大會上 , 我們看到了一個新的GPU架構、三個新的GPU芯片、一個新的算力集群、兩個新的整機 , 還有眾多開發工具和生態上的升級 , 讓人應接不暇 。
進入正題之前 , 先解釋兩個關鍵名詞 。
一是“全功能GPU”(Universal GPU) , 指具備功能完備性與精度完整性的GPU , 通俗地講就是一個GPU架構可以干幾乎所有的活兒 。
其中 , 功能完備性體現在單一GPU芯片中集成AI計算加速、圖形渲染、物理仿真和科學計算、超高清視頻編解碼等多種引擎 , 可以滿足不同的圖形與計算需求 。
精度完整性體現在單一芯片支持FP64、FP32、TF32、FP16、BF16、FP8、INT8、FP6、INT4、FP4等不同計算精度 , 可以滿足不同的GPU加速計算需求 。
相比于TPU、VPU、GPGPU、NPU、ASIC等功能相對單一的圖形或計算芯片 , 全功能GPU自然更加能打 , 來什么活兒都能干 。
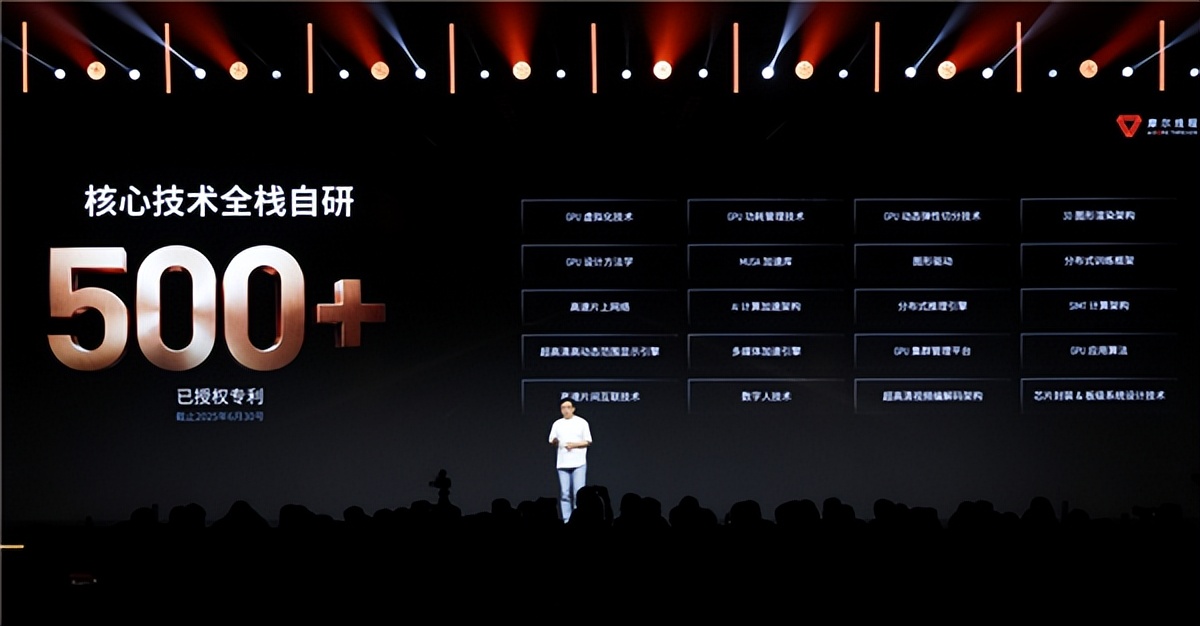
二是“MUSA” , 英文全稱Meta-computing Unified System Architecture , 中文名“元計算統一系統架構” , 摩爾線程自主研發 , 是覆蓋芯片硬件架構、指令集、編程模型、軟件運行庫、驅動程序框架等的全棧技術體系 。
MUSA架構可以說是全功能GPU的基礎 , 使之具備更強的計算通用性、更優的技術演進能力、更佳的生態兼容性、更廣泛的市場適應性 。
這一次 , MUSA不僅帶來了硬件架構迭代 , 也迎來了全棧軟件升級 , 包括支持新的MUSA C、TilLang、FlagOS & Triton編程模型 , 深度優化了性能 , 比如計算效率可達98%、通信效率可達97%、編譯器性能提升3倍、高性能算子庫等 , 以及更廣泛的計算加速庫、通信、管理開源 。
】
【主權AI的三大支柱:成敗就看它了】
大會伊始 , 中國工程院院士、清華大學計算機系教授鄭緯民發表了一番發人深思的演講 。
鄭緯民院士首先提出了主權AI的三大支柱:算力自主、算法自強、生態自立 , 三者互為前提 , 互相約束 , 共同構成主權AI的系統工程框架 。
其中 , 真正決定主權AI成敗的 , 在于是否有足夠多的開發者 , 愿意長期在一套堆棧上為一款GPU寫代碼 , 因為開發者才是生態的核心 , 并不是廠家 。
所以 , 國產平臺最需要解決的問題 , 就是降低遷移成本、提高工具鏈成熟度、做好社區尤其是開源社區 , 這樣才能從實現“能用”到“好用”再到“愿意用”的逐步跨越 。
鄭院士對摩爾線程可以說是贊不絕口 。
一是摩爾線程的國產全功能GPU , 一顆芯片就能同時做好3D圖形渲染、HPC高性能計算、AI加速 , 這是非常不容易的 。
二是摩爾線程MUSA就是類似于CUDA生態的國產實踐 , 也非常重視開源 。
鄭院士所在的清華大學團隊做了兩件事 , 一個是做了Mooncake , 是在推理中以KVCache為中心的大模型推理架構 , 能節省很多硬件資源 , 而且是開源的 。
第二個例子是KTransformers , 通過基于計算強度的Offload策略 , 可以混合使用多個CPU、GPU , 將大模型中的不同負載分配給不同設備 , 首次將千億模型本地化的成本降到了十萬元級別 。
鄭院士最后提出 , 國內GPU行業目前面臨嚴重的內卷、碎片化問題 , 形成了巨大的阻礙 。
所以產業聯盟與軟硬件協同設計非常重要 , 產業界要團結起來 , 應用也要團結起來 , 一起努力解決這個問題 。
只有當國產AI加速卡在真實業務中大規模使用 , 生態才會具備自我強化的正反饋 , 形成正向閉環 。
【新一代GPU架構:花港】
摩爾線程創始人、董事長兼CEO張建中做主題演講 , 在三個小時的時間里帶來了一個又一個驚喜!
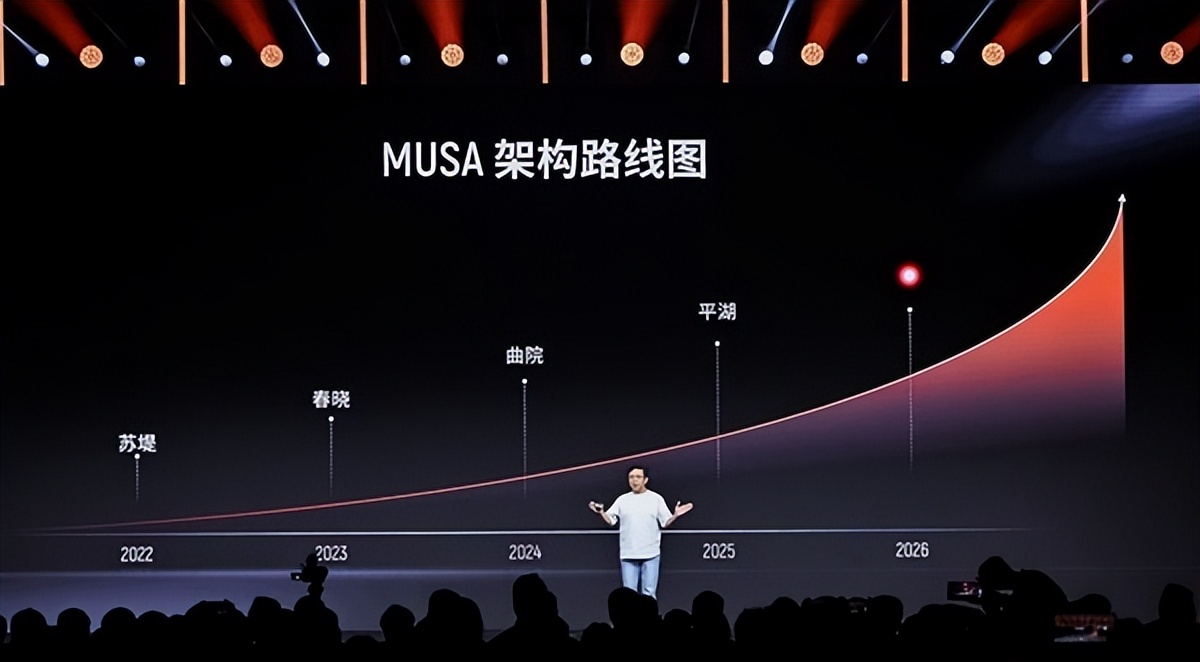
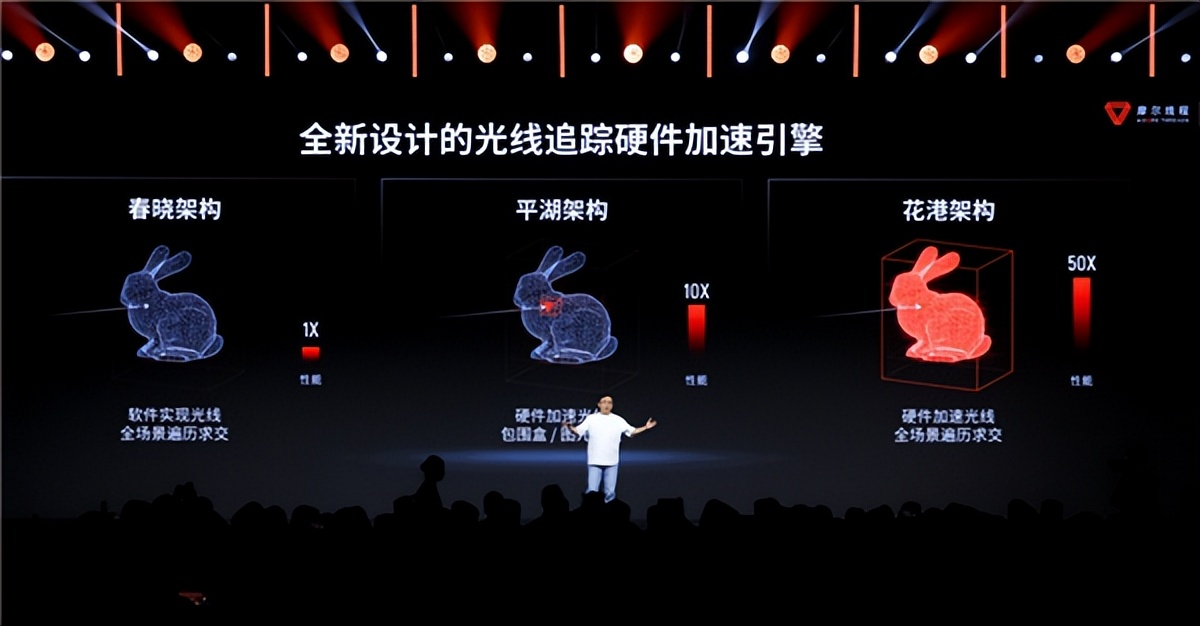
2022年以來 , 摩爾線程MUSA GPU架構每年迭代一次 , 已經先后誕生了蘇堤、春曉、曲院、平湖——是的 , 摩爾線程的架構代號都來自“西湖十景” 。
本次公布的新架構 , 代號為“花港” 。
“花港”架構支持新一代指令集 , 算力密度提升50% , 能效更是提升多達10倍 。
它支持FP4到FP64的全精度端到端加速計算 , 包括新增支持MTFP6、MTFP4 , 以及專門優化了FP8、FP6、FP4三種低精度計算 , 支持混合計算 , 能效更高 。
它具備第一代AI生成式渲染架構(AGR) , 利用AI能力改造傳統流水線 , 渲染效率更高 , 第二代光追硬件加速引擎 , 生成速度比上代提升5-6倍 , 可以完美支持最新的DX12 Ultimate的所有功能 。
另外 , 它還支持新一代異步編程技術 , 優化任務調度與并行機制 , 再結合自研MTLink高速互聯技術 , 可以支持10萬卡及以上的超大規模智算集群 。
未來 , 摩爾線程將基于“花港”架構 , 推出高性能AI訓推一體的“華山”芯片 , 以及專攻高性能圖形渲染的“廬山”芯片 。
作為國產GPU架構 , 除了良好的性能 , 安全上自主可控更是至關重要 。
“花港”架構具備全棧自研與自主可控的核心能力 , 通過安全域、信任域、保護域、功能域四層硬件安全架構 , 提供從芯片到系統的可驗證安全守護 。
具體包括:硬件信任根HRoT、安全啟動、固件安全更新與保護、可信執行環境、硬件加解密加速引擎、國密算法、機密計算、DRM數字版權保護、生命周期管理 , 等等 。
摩爾線程的GPU架構基于全棧自主研發 , 擁有扎實的專利壁壘 , 截至2025年6月30日 , 累計已申請專利1000多項 , 獲得授權專利514項 , 其中發明專利468項 。
這 , 正是摩爾線程最大的底氣 。
【十萬卡集群的基?。 篈I訓推一體芯片“華山”】
“華山”芯片基于花港架構而來 , 是一款專門面向AI訓練與推理一體化的加速計算產品 , 可以支撐萬卡級智算集群 , 構建下一代“AI工廠” 。
按照官方說法 , 它的性能上已經全面超越NVIDIA上一代Hopper架構(圖中Hxxx) , 并且能與NVIDIA新一代Blackwell架構(圖中Bxxx)打得有來有回 。
“華山”最突出的特性就是支持新一代異步編程技術 , 可以充分發揮每一個核心的算力 。
該技術可以利用各種不同線程的同步效應 , 將負載任務自動、平衡地分配到每一個計算單元 , 確保它們都能始終高效率工作 , 不至于部分單元累死、部分單元空閑 。
為此摩爾線程做了大量的工作 , 包括設計各種不同的調度機制等 , 從而讓開發者可以無感去操作芯片 , 不用操心具體的負載分配細節 。
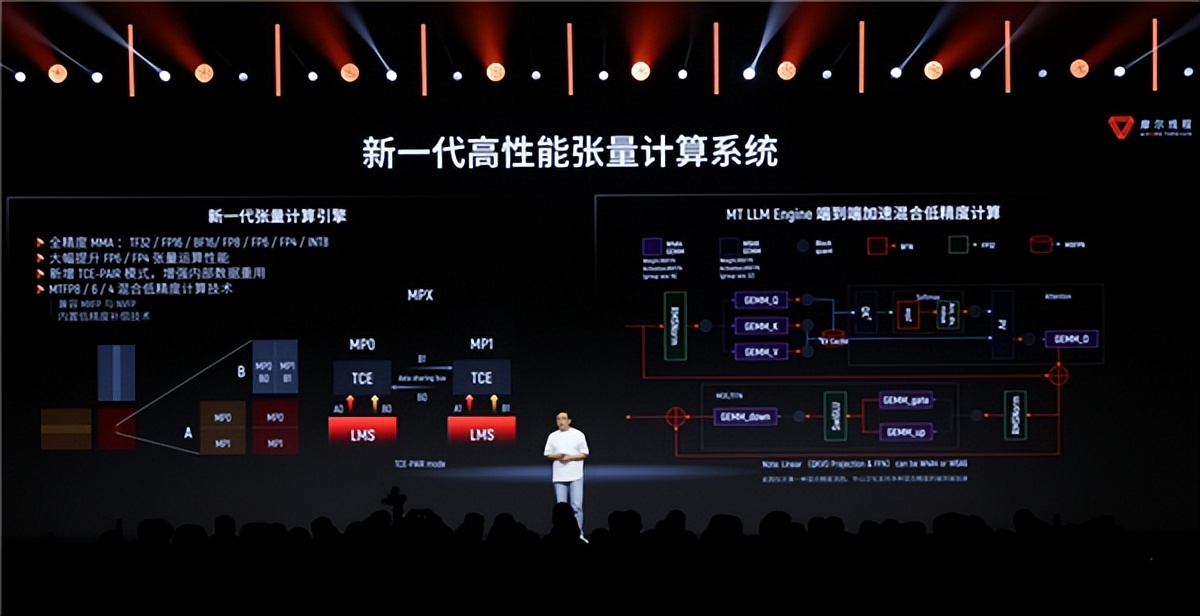
“華山”還集成了新一代高性能Tensor張量計算系統 。
首先是支持全精度 , 從32位到4位各種整數、浮點、張量數據格式都支持 , 尤其是大幅提升了FP6、FP4張量運算的性能 , 支持MTFP8/6/4混合精度計算 。
新增TCE-PAIR模式 , 可以讓兩個TCE單元彼此共享同樣的數據 , 增強內部數據重用 , 提升算子效率 。
基于“華山”芯片進行橫向、縱向的擴展 , 可以輕松打造十萬卡級別的智算集群 , 每個節點的加速卡就有最多1024塊 。
為此 , “華山”不僅支持摩爾線程自研的MTLink 4.0互連技術 , 還支持更多類型的開發互聯協議 , 兼容不同硬件生態 。
內置RAS 2.0以增強集群可靠性 , 包括支持SRAM奇偶校驗、ECC、強化錯誤檢測上報與隔離、全面升級調試能力等等 。
新一代異步通信引擎ACE 2.0 , 則在每一個計算單元里面設計一個小的ACE , 讓更多的通信和計算可以并行執行 , 極大提升整體效率 。
【新一代游戲卡就看它了!圖形渲染芯片“廬山”】
【新架構×1、新芯片×3、新整機×2、新集群×1:5歲摩爾線程徹底爆發】當然 , 對于普通用戶和游戲玩家來說 , 更值得關注的當然是消費級游戲卡 。
MTT S80/S70是目前市面上唯一能夠買到的國產游戲卡 , 其硬件性能基本達到RTX 3060級別 , 而價格只要1499元、999元 , 非常實惠 。
3年前誕生以來 , 摩爾線程一直在堅持不懈地優化 , 每月都有新驅動 , 已累計升級36個版本 , 追蹤超過550款游戲的運行情況 , 完成了超過220款的優化 , 國內最熱門50大游戲已全部兼容 , 其中44款進行了針對性優化 , 包括《黑神話:悟空》 。
累積下來 , MTT S80的跑分性能已經比發布時高出足足3.4倍 。
同時 , 摩爾線程專業圖形顯卡已經全面支持國內外的主流圖形軟件 , 包括國產的中望CAD/3D、天工CAD、剪映等等 , 都可以正常高效運行 。
新一代圖形渲染芯片代號“廬山” , 同樣基于全功能的花港架構 。
性能提升方面 , 摩爾線程給了個十足的驚喜:3A游戲性能提升15倍、光追性能提升50倍、AI性能提升64倍、幾何處理性能提升16倍、紋理填充性能提升4倍、原子訪存性能提升8倍、顯存容量增大4倍(那就是最大64GB)!
當然 , 這些都是理論上的最好情況 , 也需要驅動的深度優化適配 , 但有了MTT S80的豐富經驗 , 進展無疑會大大加快 。
從以上指標可以看出 , 除了3A游戲 , “廬山”的專業圖形能力也得到了極大的提升 , 運行CAD、CAE之類的更輕松 。
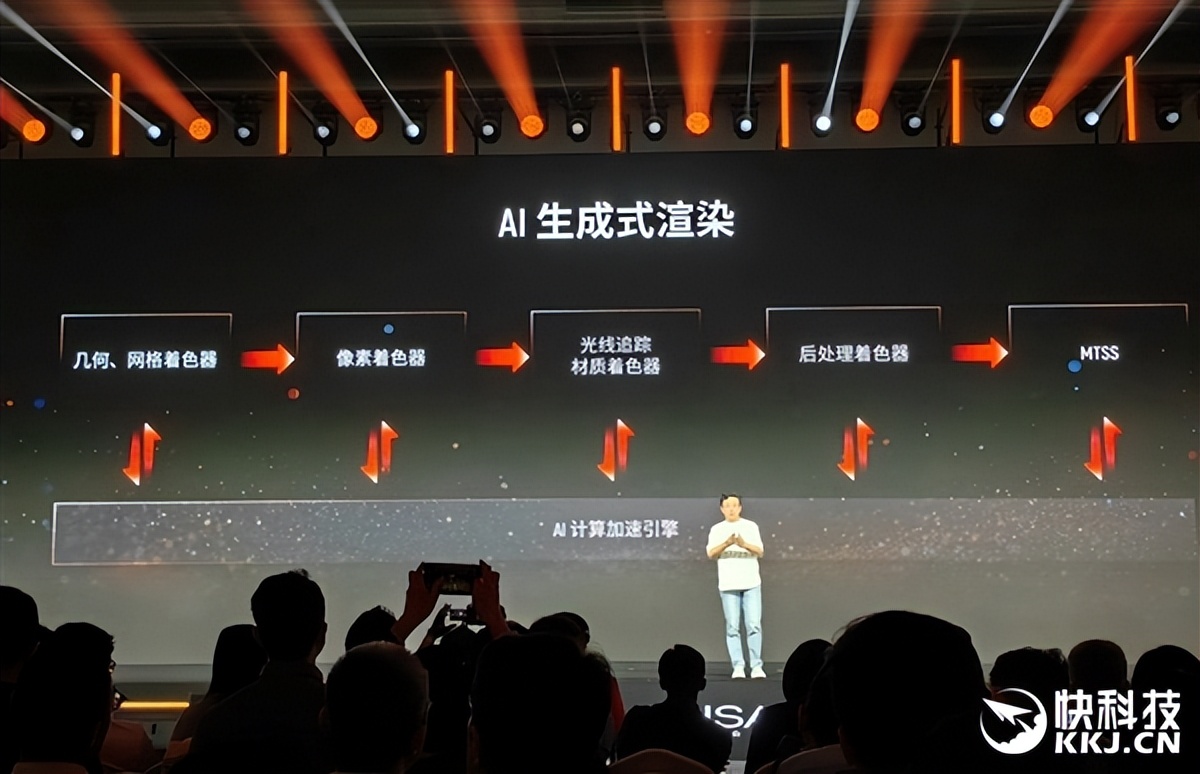
“廬山”一個很重要的特性就是AI生成式渲染MTAGR 。
整個渲染流水線的每一步都有AI賦能升級 , 包括幾何著色器、網格著色器、像素著色器、光追材質著色器、后處理著色器、MTSS等等 , 可以說AI計算加速引擎無處不在 。
MTSS其實就是MTAGR , 也可以視為摩爾線程版本的DLSS、FSR , 包括AI超分、AI多幀生成、光流、降噪等等 。
MTAGR還支持多渲染后端 , 行業標準的DirectX、Vulkan和自研的MUSA兼容 , 同時支持Windows、Linux系統和主流的CPU計算架構 。
“廬山”還創造了一個新的任務引擎管理框架叫“統一任務引擎架構”(United Task Engine) 。
它可以讓每一個GPU中的計算部分充分并行 , 所有核心、單元全部調動起來 , 不至于出現任務分配不均 , 澇的澇死旱的旱死 。
光追方面 , 花港架構內置專用光追計算模塊(RTU) , 可以適用硬件加速全場景遍歷求交 , 而不僅僅是包圍盒等少數情景 , 所以性能有了極大的飛躍 。
同時 , 摩爾線程自主設計了BVH加速結構算法 , 可以高效生成 , 并節省顯存占用 。
它還支持微軟DXR 1.1標準 , 實現更廣泛的兼容性 。
幾年來 , 摩爾線程一步一個臺階 , 不斷升級支持行業標準和自研的圖形技術 , 2023年實現了DX11、虛擬化 , 2024年底率先支持DX12 , 如今已支持OpenGL 4.6、Vulkan 1.3 。
2026年 , 摩爾線程GPU不但將升級支持DX12 Ultimate , 還會支持Vulkan光追以實現完整的光追生態 , 支持神經網絡渲染、MT Photon光子渲染引擎 , 以及下一代AI生成式渲染架構MTAGR 2.0 。
其中 , MT Photon光子引擎是一套硬件級光追和混合渲染平臺 , 為開發者提供更強大的光追開發接口 , 將其用于專業生產力領域 。
它支持原生硬件加速 , 可直接調用多個GPU核心 , 而且全鏈路使用標準開發語言MUSA C++ , 降低開發復雜度 , 讓虛擬環境更接近物理現實 。
至于基于“廬山”芯片的MTT S游戲顯卡何時發布上市 , 靜靜期待吧!
【大一統SoC芯片長江和兩臺整機】
本次發布的第三顆芯片有些特殊 , 是一個完整的SoC片上系統 , 代號“長江” 。
它匯聚了幾乎所有計算單元 , 具體包括:
CPU:8個全大核 , 主頻最高2.65GHz , 主打高性能低功耗 , 自然是Arm架構 。
GPU:來自摩爾線程自研的全功能GPU , 主打高性能3D渲染、大模型端側推理 。
NPU:可編程雙核心 , 支持語音、圖像的多模態加速處理 。
VPU:視頻處理單元 , 支持H.264、H.264、AV1等格式的編解碼 , 支持8K30、4K60 。
DPU:顯示處理單元 , 支持高清多屏 , 包括雙屏8K60、八屏4K60 。
DSP:數字信號處理單元 , 高性能雙核設計 , 支持AI降噪、Hi-Fi音效等 。
ISP:圖像處理單元 , 最高支持3200萬像素攝像頭 , 也支持HDR 。
內存支持32/64GB LPDDR5X , 帶寬超過100GB/s , 不過沒說通道數量、具體頻率 。
“長江”的異構AI總算力超過50 TOPS , 同時支持FP64、FP32、FP16等多精度計算 , 但似乎低精度方面還有所欠缺 。
“長江”芯片首批有三款產品 , 一是筆記本 , 二是臺式迷你機 , 三是迷你開發模塊 。
筆記本 , 或者嚴格來說是AI算力本 , 叫做“AIBOOK” 。
它是專為AI學習與開發者打造的個人智算平臺 , 或者說其實就是個算力本、開發本 , 也兼具日常使用 。
AIBOOK默認運行基于Linux內核的MT AIOS操作系統 , 并具備多系統兼容能力 , 支持Windows虛擬機、Android容器 , 也兼容主流的國產操作系統 。
預置完整的AI開發環境、工具鏈、包管理工具、常用庫、框架等等 , VS Code、Jupyter Notebook、Pyhton、PyTorch、vLLM、Pandas等都在 , 還提供GPU驅動支持和配套工具包 , 開發部署也進行了簡化 。
此外 , AIBOOK端側最高可運行30B參數大模型 , 預裝了阿里的Qwen3-8B大模型、智源悟界的Emu 3.5多模態世界模型 , 支持視覺指導、視覺故事、圖片編輯、文本生圖等能力 。
利用它 , 開發者可以輕松打造各種AI應用和智能體 。
它也內置了數字人智能體“小麥”以及豐富的AI應用 , 預置MUSAChat-72B大模型具備出色的理解與推理能力 , 還支持靈活調用各種模型的API , 提供開箱即用的一站式AI體驗 。
“小麥”現已開放核心能力 , 開發者可通過官方文檔中心獲取云端API、本地SDK 。
配置方面 , AIBOOK采用極簡設計 , 航空級鋁合金材質一體成型 , 薄至12.4毫米 , 輕至1.35千克 。
14寸OLED屏幕屏占比達91% , 支持2.8K高分辨率、120Hz高刷新率 , 配備4揚聲器、4麥克風陣列、1080p攝像頭、1.5毫米鍵程鍵盤、12×7.5毫米觸摸板 。
內置1TB SSD、70Whr電池 , 提供三個USB-C接口、Wi-Fi 6、藍牙5.2 。
價格9999元 , 現已開放預售 。
另一款整機則是迷你型的“MTT AICube” , 進一步豐富端側計算產品形態 , 同樣基于“長江”SoC , 同樣支持多系統、端云大模型 。
很顯然 , 它的設計思路和用途就類似AMD 395、NVIDIA DGX Spark這樣的個人開發用迷你機 。
具體細節沒有展開講 , 不過官方已經向開發者發出了征集令 , 歡迎體驗 。
另外就是“MTT E300 AI模組” , 極致小巧 , 被動散熱 。
憑借高算力、全棧AI工具鏈、端云協同架構 , 它可提供高性能、低延遲、強可靠的國產邊緣AI解決方案 , 廣泛應用于工業、能源、教育、交通、醫療等行業 。
【十萬卡夸娥智算集群】
接下來講講剛才提到過的“夸娥”萬卡智算集群(KUAE 2.0) , 也是本次大會的一個重磅亮點 。
這東西看似和普通人距離很遠 , 但卻是國家AI算力的關鍵基礎設施 , 我們日常使用的大量AI服務也都是它們在幕后默默提供支持 。
從千卡集群起步 , 做到萬卡集群 , 摩爾線程接下來還要沖擊10萬卡、100萬卡、1000萬卡……
摩爾線程夸娥萬卡集群成功攻克了萬卡級硬件篩選、高速互聯、系統級容錯等高難度工程級難題 , 可支撐萬億參數大模型的訓練與部署 。
該集群具備全精度、全功能通用計算能力 , 在萬卡規模下實現高效穩定的AI訓練與推理 。
訓練算力利用率(MFU)在Dense稠密大模型上達60% , MoE專家大模型上達40% , 有效訓練時間占比超過90% , 訓練線性擴展效率達95% , 訓練容錯系統目標ETTR達到99% , 并與國內、國際主流生態高度兼容 , 在多項指標上具備顯著能效優勢 。
軟件方面有KUAE RAS System Daemon , 可以守護萬卡集群的穩定性、性能、正確性 , 目標是提升客戶萬卡訓練成功率30% 。
在客戶系統無感情況下 , 它可以快速定位并替換集群故障節點、慢節點、SDC 節點 , 有效保障客戶萬卡訓練穩定性、高性能、正確性 。
摩爾線程聯合硅基流動 , 實現國產GPU與軟件棧的全棧優化 , 大幅提升了AI推理性能 。
基于摩爾線程最新AI加速卡MTT S5000 , 運行DeepSeek R1 671B全量模型 , 單卡Prefill吞吐突破了4000 tokens/s , Decode吞吐也突破了1000 tokens/s , 可支持高并發、低延遲的大模型服務 。
摩爾線程還計劃推出第一代超級節點產品MTT C256 , 著眼高密硬件架構 。
它以一層scale-up網絡 , 實現兩臺機柜256塊加速卡的全互聯 , 從而規避兩層以上網絡帶來的帶寬損失和額外延遲 , 大幅提高智算集群的GPU部署密度 。
此外 , 本次MUSA開發者大會 , 摩爾線程還介紹了全功能GPU在生命科學計算、量子科技、6G、具身智能與仿真、物理引擎、仿真環境訓練、智能駕駛物理AI仿真等各領域的應用與發展 , “摩爾學院”開發者扶持項目等等 , 不再一一展開 。
【應用展示】
大會現場 , 摩爾線程聯合眾多行業生態伙伴 , 設置了超過1000平方米的主題展區 , 內容覆蓋AI大模型與智能體、具身智能機器人、科學計算、空間智能等前沿技術領域 , 以及工業智造、數字孿生、數字文娛、智慧醫療等熱門應用場景 , 還有眾多基于摩爾線程GPU的產品 。
接下來挑一部分摩爾線程與生態伙伴的合作產品以及案例 , 和大家分享 。
B700 AI BOX:
聯達興推出的國產高性能智能終端設備 , 支持4K60Hz超清雙顯 , 集成雙千兆網口、Wi-Fi 6及藍牙5.3無線模塊 , 配備專業音頻接口和DC供電 , 完美適配智能會議、數字標牌等AIoT應用場景 。
ME10工業級智算BOX:
天思智慧的國產高性能計算設備 , 基于“長江”SoC , 最多32GB LDDR5/5X內存 , 具備寬溫適應性和豐富接口 , 適用于智能制造、智慧城市、智慧醫療及教育等領域 。
ME21 AI迷你機:
高性能國產AI計算終端 , 同樣基于“長江”SoC , 專為本地大模型部署設計 , 完美適用于智能辦公、邊緣計算及AI教育等領域 。
SD5600MX100:
國儀海聚打造 , 為智能系統與平臺提供高算力核心 , 滿足車規、工業自動化、醫療等行業需求 , 擁有出色的成本控制以及靈活的I/O設計 。
后羿智盒HOUYI-1000B:
全愛科技的GPU大模型AI端側部署工控機 , 3.5寸標準工業主板形態 , 無風扇散熱 , 可適應更嚴苛場景 , 可支持32B大模型的端側部署 , 滿足深度學習、機器視覺推理、無人機、智能車等復雜AI任務的需求 , 廣泛應用于安防、交通、科研、教育等眾多領域 。
后羿智盒HOUYI-Pi-B:
全愛科技打造 , 超小體積 , 可實現端側大模型的廣泛應用 , 支持i32B大模型的端側部署 , 能夠滿足深度學習機器視覺推理等復雜AI任務的需求 , 廣泛用于機器人、無人機、視頻服務器等場景 。
物流無人機:
紫光計算機的小載重四旋翼末端配送設備 , 專為1千克小型包裹運輸資料設計 , 支持4G/5G/專網通信 , 采用RTK+視覺融合精準降落 , 搭配訂單APP、飛行管理平臺及機庫 , 可自主完成航線飛行與投遞任務 。
柳工CLG922E挖掘機(圖為示意模型):
基于MindEdge L100邊緣計算平臺 , 有效實現工程機械的智能化升級 , 整合設備運行數據與音視頻信息 , 在邊緣側持續優化故障診斷、壽命預測、能效管理及自動駕駛等AI模型 , 有效解決了大型挖掘機在復雜工況下的安全、節能與穩定性挑戰 。
甚至就連盾構機 , 都用上了摩爾線程GPU!
基于雪浪云研發的“盾構大腦” , 打通內部七大主要控制系統、外部多個施工環境感知和遠程運維系統 , 打造了一體化集成控制的盾構機復雜工況自適應控制中樞 , 精準解決了隧道施工過程掘不快、掘不準、掘不穩的難題 。
羅拉超算體LoLR CUBE(法律版):
搭載摩爾線程MTT E300 64GB模組 , 聯手打造端側全棧(CPU+GPU/NPU+FPGA) , 最高可驅動300億大模型推理 , 閱卷解析處理快至10秒/頁 , 相比傳統人工閱卷效率提升約100倍 , 支持法律文書批量生成與AI輔助優化 。
羅拉超算體LoLR CUBE(財稅版):
同樣搭載摩爾線程MTT E300 64GB模組 , 配置2000+專業指標、300億AI風控大模型 , 集結多領域Agent數字專家 , 提供7X24小時實時監控、100%稅收政策同步與超99%任務準確率 。
紫光計算機UltiStation 800H工作站:
旗艦級國產化單路工作站 , 搭載海光C86-4G處理器 , 最高支持128GB DDR5內存及PCIe 5.0高速存儲與顯卡 , 搭載摩爾線程高性能專業顯卡 , 廣泛應用在政府、教育及行業領域的專業圖形處理、仿真與AI計算任務 。
現場還有一套紫光計算機100P智算集群 , 基于摩爾線程MTT S4000 。
保障特種作業人員安全、實現“無人化”操作 , 是核電等高風險行業轉型的核心要務 。
景業智能打造的VR遙操作機器人系統 , 已與摩爾線程AI模組MTT E300、高性能顯卡MTT S80完成適配 。
操作人員通過佩戴VR眼鏡 , 即可遠程精準控制特種機器人 , 在實際輻射等高風險環境中完成精細任務 , 實現“人以遙操 , 機器代勞” 。
該方案以MTT E300確保機器人控制與視頻轉發的精準穩定 , 以MTT S80保障駕駛艙視頻的流暢串流 , 構建超低延遲、高可靠的操控閉環 。
景業智能打造的智能巡檢機器狗 , 具備自主理解與泛化推理能力 , 通過全景攝像頭與雙光譜云臺 , 能在復雜園區環境中自主完成人員識別、安全隱患排查、設備狀態監測等多元任務 。
該方案已與摩爾線程MTT S4000完成適配 , 通過全功能GPU的強大算力部署并加速Qwen大模型 , 可為巡檢機器狗賦予關鍵的場景理解與實時推理能力 。
中望軟件的全棧國產化三維CAD一體化解決方案 , 基于摩爾線程MTT X300專業顯卡 , 適配多種國產CPU與操作系統 , 可流暢渲染復雜三維模型 。
ADAI自研的ADXL Pro Max生圖模型、AD Edit編輯模型 , 已服務數十萬C端用戶、500多家行業用戶 , 累計生成圖像數量突破8000萬張 , 現已深度適配摩爾線程GPU 。
北太天元科學計算軟件 , 面向科學計算與工程計算 , 是國內首款通用型科學計算與系統仿真軟件 , 自主構建非開源技術路線 , 全鏈條自主可控 , 已集成MUSA加速計算能力 , 成為全球首款原生集成AI能力的科學計算工具 , 可全面替代MATLAB、Simulink 。
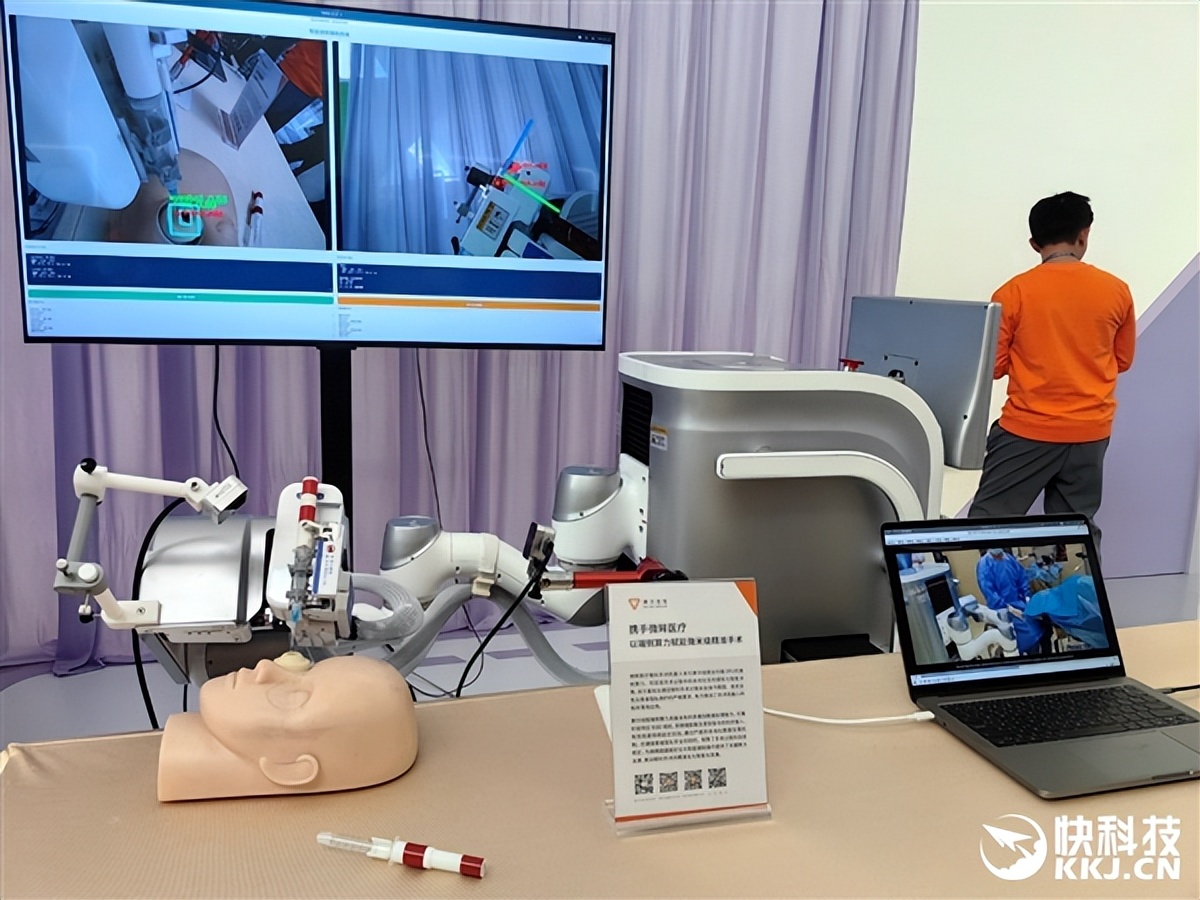
微眸醫療眼科手術機器人 , 可實現手術過程中的本地化實時感知與智能決策 , 充分滿足眼科手術對微米級操作精度、高安全性、患者隱私保護的嚴格要求 。
微視威eVTOL全動飛行模擬器 , 全鏈路自主研發 , 1:1封閉座艙與六自由度運動平臺 , 搭載基于北京大學ViWo引擎的ViSYS視景系統 , 可高質量模擬低空飛行場景 , 國內首個通過中國民航局5級鑒定的國產視景系統 , 已成功出口海外 。
模擬器基于摩爾線程MTT X300專業顯卡 , 首次打通全國產化視景渲染鏈路 , 不僅可用于飛行員訓練 , 也支持eVTOL機型工程驗證 。
面向文旅、政務、面試培訓等不同領域的數字人 。
摩爾線程MTVSR實時視頻超分技術 , 端側運行 , 可將分辨率提升2-4倍 , 多檔質量設定 , 顯著提升低分辨率視頻在高分辨率屏幕下的清晰度 , 還將以SDK形式支持播放器、瀏覽器等App集成調用 。
推薦閱讀














- 背靠通義大模型 這家阿里系公司正在重寫體育場館新的「定價公式」
- Xiaomi Watch 5評測:打響指控家電,重新定義智能手表交互
- 不僅僅是續航升級 小米Watch 5全面評測:隔空操控開啟腕上交互新紀元
- 同泰怡&鯤鵬:從產品深耕到生態共建,筑牢自主創新算力底座
- 北辰集團攜手華為發布智慧場館全球樣板點 首都國際會展中心邁入數智新篇章
- 2026年首款新機官宣:1月1日,正式開售
- 榮耀新機最后預熱:12月26日,正式發布
- 顛覆傳統設計!vivo新專利讓散熱風扇兼具通信功能
- 一加Turbo國際版照片率先曝光,處理器和刷新率或比國內縮水
- 張平:擺脫路徑依賴,攻堅從“比特”到“語義”的6G新范式