
文章圖片
文章圖片

文章圖片
文章圖片

文章圖片
編輯|澤南、陳陳
人們獲取醫(yī)療信息的方式 , 正在逐漸被 AI 改變 。
2026 剛一開年 , OpenAI 發(fā)布了一份有關(guān)普通人與 AI 醫(yī)療的報告 。
報告給出的信息令人驚訝:目前全球 ChatGPT 對話中有超過 5% 是與醫(yī)療健康有關(guān)的 , 每天有 4000 萬人在向 ChatGPT 尋求健康問題的答案 。
在人們向 AI 問的問題中 , 大模型的智能與知識儲備得到了充分體現(xiàn):60% 的人用 AI 探索癥狀 , 52% 的人用于理解醫(yī)學(xué)術(shù)語或臨床建議;越來越多的醫(yī)生也在撰寫醫(yī)療報告的時候應(yīng)用了 AI 。
也正是因?yàn)槿绱?, 1 月 7 日 , OpenAI 正式發(fā)布了 ChatGPT 健康 , 通過整合人們的健康信息與大模型能力 , 可以幫助人們更加了解自身狀況 , 能輔助人們進(jìn)行健康方面的決策 。
【醫(yī)療領(lǐng)域DeepSeek時刻:螞蟻 · 安診兒醫(yī)療大模型開源,登頂權(quán)威榜單】大模型正在生活的很多方面給我們帶來幫助 , 但在面向常規(guī)任務(wù)的通用大模型上尋找醫(yī)療等專業(yè)知識的建議 , 很多時候還是顯得不夠靠譜 。 在醫(yī)療學(xué)術(shù)界 , 有研究就認(rèn)為 AI 提供的醫(yī)療決策必須強(qiáng)制披露其準(zhǔn)確性 , 接受監(jiān)管以保護(hù)患者的安全 。
近日 , 螞蟻集團(tuán)聯(lián)合浙江省衛(wèi)生健康信息中心、浙江省安診兒醫(yī)學(xué)人工智能科技有限公司開源的的螞蟻?安診兒醫(yī)療大模型(AntAngelMed) , 似乎為這些需求找到了最優(yōu)解 。
該模型總參數(shù)量達(dá)到 1000 億(激活參數(shù) 61 億) , 是迄今為止參數(shù)量最大的開源醫(yī)療領(lǐng)域?qū)I(yè)模型 。
AntAngelMed 在 OpenAI 發(fā)起的 HealthBench、國家人工智能應(yīng)用中試基地(醫(yī)療)的 MedAIBench 等評測基準(zhǔn)中表現(xiàn)出色 , 其成績超過了 GPT-oss、Qwen3、DeepSeek-R1 等通用模型 , 也超越了目前已有的醫(yī)療增強(qiáng)推理模型 , 達(dá)到了開源模型第一的成績 。
在由國家人工智能應(yīng)用中試基地(醫(yī)療)?浙江、中國醫(yī)學(xué)科學(xué)院北京協(xié)和醫(yī)學(xué)院、中國信息通信研究院三方共建的權(quán)威測評體系 MedAIBench 中( https://www.medaibench.cn/ ) , AntAngelMed 同樣表現(xiàn)突出 , 尤其是在醫(yī)療知識問答、醫(yī)療倫理安全等多個核心維度上優(yōu)勢顯著 。
此外 , AntAngelMed 在 MedBench 排行榜中位列第一 。 MedBench 是專為評估中國醫(yī)療健康領(lǐng)域語言大模型(LLM)而設(shè)計的權(quán)威基準(zhǔn) 。 AntAngelMed 的這一成績進(jìn)一步凸顯了其在專業(yè)性、安全性以及臨床應(yīng)用潛力方面的領(lǐng)先表現(xiàn) 。
目前 AntAngelMed 模型系列已在模型平臺開源:
- HuggingFace:https://huggingface.co/MedAIBase/AntAngelMed
- ModelScope:https://modelscope.cn/models/MedAIBase/AntAngelMed
- Github: https://github.com/MedAIBase/AntAngelMed
專業(yè)三階段訓(xùn)練
與通用模型不同 , 醫(yī)療大模型面對的評價標(biāo)準(zhǔn)不僅僅是「答得多流暢」 , 還要強(qiáng)調(diào)結(jié)論的可靠性與可控性:既要在證據(jù)充分時給出嚴(yán)謹(jǐn)判斷 , 也要在信息不足或風(fēng)險較高時保持克制、明確安全邊界 。 要滿足這種要求 , 模型不僅需要覆蓋系統(tǒng)化的醫(yī)學(xué)知識 , 更需要具備穩(wěn)定的推理能力與風(fēng)險意識 。
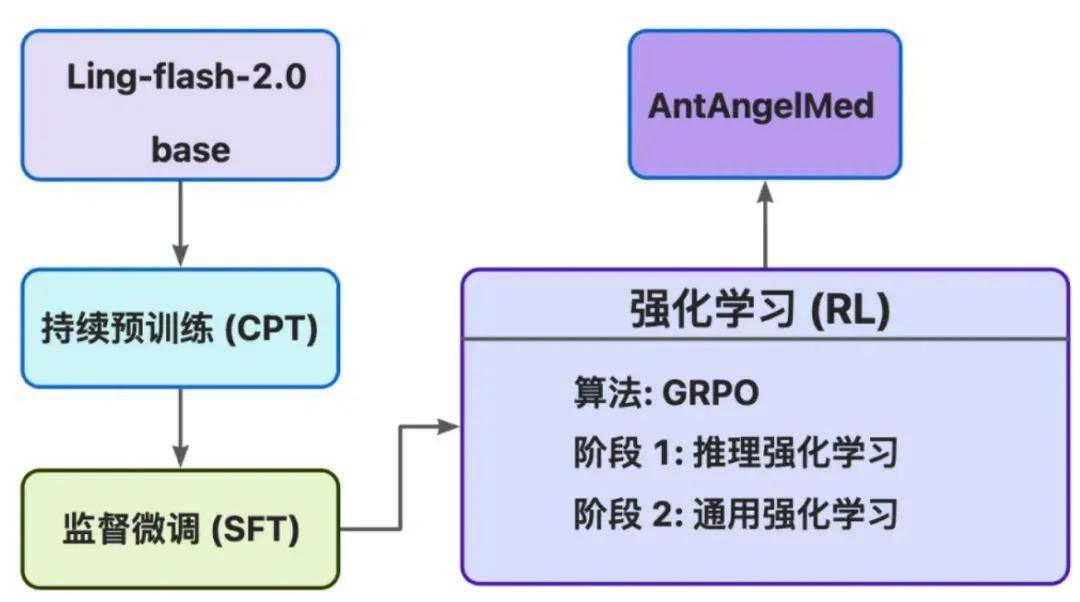
AntAngelMed 作為一款專注醫(yī)療垂直領(lǐng)域的開源大模型 , 其訓(xùn)練策略正是圍繞上述要求展開的 , 形成了一套以醫(yī)學(xué)能力構(gòu)建為目標(biāo)的三階段訓(xùn)練流程 。
第一階段是持續(xù)預(yù)訓(xùn)練 , 為模型注入醫(yī)學(xué)知識 。
團(tuán)隊(duì)在螞蟻百靈通用基座模型 Ling-flash-2.0-base 上系統(tǒng)性引入大規(guī)模、高質(zhì)量醫(yī)學(xué)語料 , 比如百科全書、網(wǎng)絡(luò)文本、學(xué)術(shù)出版物 。
通過這一過程 , 模型構(gòu)建起了穩(wěn)定而完整的醫(yī)學(xué)知識結(jié)構(gòu) , 為后續(xù)的醫(yī)學(xué)能力打下堅實(shí)的地基 。
第二階段是面向真實(shí)醫(yī)療任務(wù)的監(jiān)督微調(diào) 。
AntAngelMed 引入了來自不同來源、不同形式的高質(zhì)量醫(yī)療指令數(shù)據(jù) , 重點(diǎn)微調(diào)模型如何展開和表達(dá)推理過程 。 這一階段不僅提升了模型在復(fù)雜問題中的思考穩(wěn)定性 , 也使其在醫(yī)患問答、診斷分析等真實(shí)場景中 , 能夠更好地理解問題語境并給出符合醫(yī)療交流邏輯的回應(yīng) 。
這樣一來 , AntAngelMed 不再僅僅停留在回答正確的表層表現(xiàn)上 , 而是在醫(yī)療語境中展現(xiàn)出更接近專業(yè)醫(yī)生的溝通方式與思維路徑 。
第三階段是強(qiáng)化學(xué)習(xí) , 控制 AI 醫(yī)療回答的邊界與行為方式 。
AntAngelMed 采用先進(jìn)的 GRPO(Group Relative Policy Optimization , 組相對策略優(yōu)化) 強(qiáng)化學(xué)習(xí)算法 , 并通過雙階段強(qiáng)化學(xué)習(xí)路徑對模型能力進(jìn)一步優(yōu)化提升 。
首先是「推理強(qiáng)化學(xué)習(xí)」 , 確保模型面對復(fù)雜病例信息時能保持因果鏈條清晰、判斷過程可追溯 。
然后是「通用強(qiáng)化學(xué)習(xí)」 , 重點(diǎn)關(guān)注模型的行為邊界 , 在面對不確定性、敏感性問題時學(xué)會提示風(fēng)險、適度保留 , 體現(xiàn)出必要的責(zé)任意識和安全規(guī)范 。
可以說這一階段是通用大模型最容易「踩雷」的部分 , 而也是醫(yī)療 AI 最重要的「合規(guī)能力」 。
AntAngelMed 專業(yè)三階段訓(xùn)練流程
高效 MoE 架構(gòu) , 高效推理能力
除了能力結(jié)構(gòu)的精細(xì)建構(gòu) , AntAngelMed 也在工程設(shè)計上充分考慮醫(yī)療系統(tǒng)的部署需求 。
AntAngelMed 繼承了 Ling-flash-2.0 的先進(jìn)架構(gòu) , 是一個高效的混合專家(MoE)模型 。
Ling-flash-2.0 模型架構(gòu)
在 Ling Scaling Laws 的指導(dǎo)下 , 只激活 1/32 參數(shù)(61 億) , 并在專家粒度、共享專家比例、注意力平衡、無輔助損失函數(shù) + Sigmoid 路由、MTP 層、QK-Norm 和 Partial-RoPE 等核心組件上進(jìn)行了全面優(yōu)化 。
這些優(yōu)化使得小激活率的 MoE 模型相比同等規(guī)模的 Dense 架構(gòu) , 可以實(shí)現(xiàn)高達(dá) 7 倍的效率提升 。
也就是說 , AntAngelMed 僅需 6.1B 激活參數(shù) , 就能實(shí)現(xiàn)約 40B 稠密模型的性能 。 這意味著模型在實(shí)際部署中對資源的占用更低、可擴(kuò)展性更強(qiáng) , 非常適合高用戶需求的醫(yī)療領(lǐng)域 。
由于激活參數(shù)較少 , AntAngelMed 具備非常高的推理效率 , 在 H20 硬件環(huán)境下 , 可實(shí)現(xiàn)超過 200 tokens/s 的推理速度 , 約為 36B 稠密模型的 3 倍 。
對于醫(yī)療場景而言 , 這樣的推理效率不僅代表響應(yīng)更快 , 更重要的是 , 它提升了模型在實(shí)際系統(tǒng)中的可用性:在多用戶同時訪問的醫(yī)療平臺上 , 能夠保證穩(wěn)定輸出;在需要快速輔助決策的臨床場景中 , 能在數(shù)秒內(nèi)完成高質(zhì)量回答 , 減少等待時間;甚至在資源受限的邊緣部署環(huán)境中 , 也能以較低算力負(fù)擔(dān)提供可用性能 。
另外 , 醫(yī)療場景中常常伴隨著篇幅較長的病歷記錄和結(jié)構(gòu)復(fù)雜的檢查報告 , 信息密度高、語義層級深 , 對模型的理解與處理能力提出了更高要求 。
為解決這一需求 , AntAngelMed 采用 YaRN 外推 , 將上下文長度擴(kuò)展至 128K , 大幅增強(qiáng)了模型處理病歷等長文檔的能力 。
此外 , 為配合進(jìn)一步推理加速 , 團(tuán)隊(duì)還采用了 FP8 量化技術(shù)并結(jié)合 EAGLE3 優(yōu)化方案 。 這種軟硬結(jié)合的設(shè)計帶來了實(shí)實(shí)在在性能提升 。
在并發(fā)數(shù)為 32 的情況下 , 與單獨(dú)使用 FP8 相比 , 這種方法顯著提高了推理吞吐量 , 在 HumanEval 數(shù)據(jù)集上的提升幅度為 71% , 在 GSM8K 數(shù)據(jù)集上的提升幅度為 45% , 在 Math-500 數(shù)據(jù)集上的提升幅度更是高達(dá) 94% 。
從訓(xùn)練流程到模型架構(gòu) , 我們不難看出 , AntAngelMed 的設(shè)計始終圍繞醫(yī)療場景展開 。 三階段訓(xùn)練方式讓模型具備了專業(yè)的醫(yī)學(xué)知識 , 而高效的 MoE 架構(gòu) , 使得模型在醫(yī)療這種高頻次、高要求的場景下 , 在大幅降低激活成本的同時 , 依然保持專業(yè)推理能力與長上下文處理能力 。
AntAngelMed:領(lǐng)先的醫(yī)學(xué)專業(yè)模型
最后 , 我們上手體驗(yàn)了一番 , 看看 AntAngelMed 真實(shí)效果如何?
先來個大家都忽視但又每天經(jīng)歷的事情 , 一個成年人一天到底要吃幾個雞蛋 。
AntAngelMed 的響應(yīng)速度非常快 , 幾乎在我們輸入問題后沒幾秒就給出了答復(fù) 。
模型的建議并非簡單羅列營養(yǎng)標(biāo)準(zhǔn) , 而是結(jié)合了膽固醇攝入上限、個體健康狀況(如有無高血脂病史)等因素 , 給出了一個相對靈活的建議區(qū)間:
接下來我們又問了一個問題:請為一個 55 歲有高血壓病史的上班族男性 , 設(shè)計一個簡潔可執(zhí)行的一周飲食 + 運(yùn)動建議計劃 。
AntAngelMed 的回答簡直比醫(yī)生還詳細(xì) , 還做了表格方便用戶查看:
結(jié)語
AntAngelMed 的開源 , 對于 AI 和醫(yī)療行業(yè)而言具有重要意義 。
在 AntAngelMed 的基礎(chǔ)上 , 大量機(jī)構(gòu)和研究者可以進(jìn)行下游任務(wù)微調(diào) , 極大地降低了前沿醫(yī)療 AI 技術(shù)的應(yīng)用門檻 。 對于普通人來說 , 或許過不了多久 , 我們就可以從 AI 那里獲得安全可信的建議了 。
據(jù)介紹 , 螞蟻集團(tuán)還將依托國家平臺持續(xù)推進(jìn)「AI + 醫(yī)療」的開源生態(tài)與技術(shù)創(chuàng)新 , 讓先進(jìn)的技術(shù)能夠普惠更多開發(fā)者與用戶 。
推薦閱讀















- 從DeepSeek到豆包,中國互聯(lián)網(wǎng)進(jìn)入“虎變”紀(jì)元
- 聯(lián)發(fā)科卡位ASIC,移動SoC將降級?
- 老黃開年演講「含華量」爆表!拿DeepSeek、Kimi驗(yàn)貨下一代芯片
- 2026國補(bǔ)新領(lǐng)域:能聽歌能拍照能對話,三款2000元價位AI眼鏡推薦
- TCL李東生:中韓兩國在AI、半導(dǎo)體顯示等新興領(lǐng)域合作潛力巨大
- DeepSeek推出mHC架構(gòu)提升AI模型性能
- 詳細(xì)解讀DeepSeek新年的第一篇論文,他們就是這個時代的真神。
- DeepSeek發(fā)布最新論文,破解大模型訓(xùn)練擁堵難題
- 梁文鋒署名,DeepSeek元旦新論文要開啟架構(gòu)新篇章
- 剛剛,DeepSeek扔出大殺器,梁文鋒署名!暴力優(yōu)化AI架構(gòu)