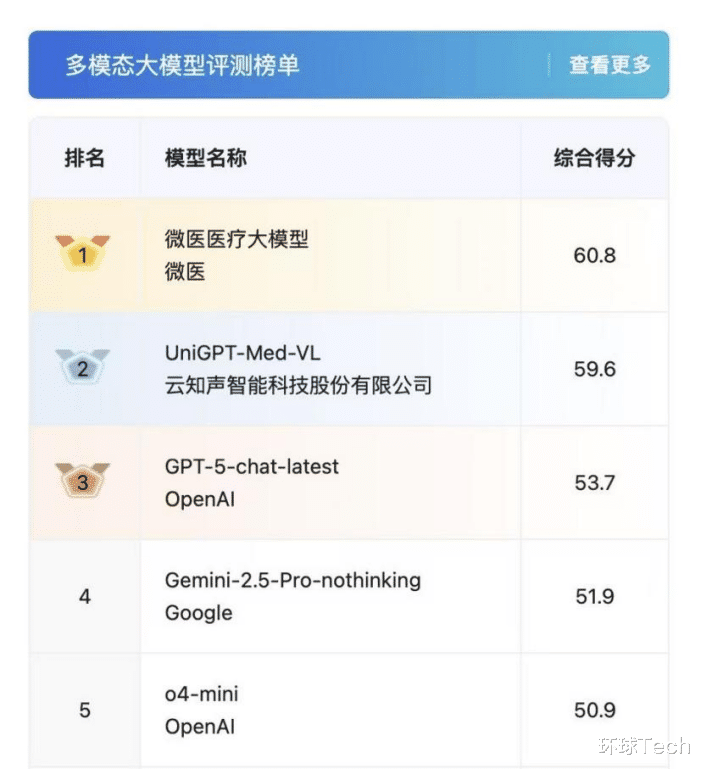
日前 , 中文醫療大模型權威評測平臺MedBench公布了最新一期評測結果 , 引發關注 。 由上海人工智能實驗室全新發布的MedBench 4.0 , 是國內首個且唯一面向醫療垂直大模型、專用大模型及應用場景的綜合性評測與驗證的平臺 , 已成為衡量醫學人工智能產品性能與可靠性的科學標尺 。 在迭代至4.0版本的更為嚴格、全面的MedBench權威評測中 , 微醫醫療大模型在綜合榜單中持續領跑 , 其突出的臨床輔助能力與可靠性獲得驗證 。
MedBench榜單截圖
【微醫醫療大模型領跑MedBench 4.0綜合榜單】2025年11月 , MedBench升級至4.0版本 , 聚焦“實戰化評測突破”與“生態化開放共建”兩大核心方向 , 包含多模態大模型、大語言模型、及智能體三大技術范式 。 平臺對齊國家《衛生健康行業人工智能應用場景參考指引》 , 覆蓋60個全自主構建評測集 , 深度提煉共70萬余專業評測題 , 全方位檢驗模型在不同醫療場景下的真實能力 , 標志著我國醫療大模型評測體系邁入一個全新的階段 。
全方位能力驗證:微醫醫療大模型展現“真功夫”
在MedBench 4.0的評價體系下 , 微醫醫療大模型的優異成績充分證明了其扎實的內功 。
在至關重要的多模態能力上 , 微醫醫療大模型問鼎評測榜單 。 MedBench 4.0瞄準醫療影像、檢測報告等臨床核心場景 , 設置了涵蓋目標檢測、圖像分類、多模態報告質控、序列影像理解、病程動態追蹤等10項細分任務 。 這填補了中文醫療多模態評測領域的技術缺口 , 也為微醫醫療大模型在醫學影像輔助分析、多模態報告解讀等方面的能力提供了精準的驗證依據 。 在針對大語言模型和智能體的評測方面 , 微醫醫療大模型均位列榜單前三 , 行業領先的醫療AI研發能力進一步凸顯 。
此次評測結果有力地回應了“醫療大模型價值何在”的行業之問 。 與滿足日常健康咨詢的通用大模型不同 , 微醫醫療大模型自研技術聚焦深度融合臨床真實診療數據與臨床決策路徑 , 在需要給出專業判斷的嚴肅醫療場景中 , 能夠提供高質量的循證參考 , 其核心價值在于真正賦能診療水平提升、助力基層醫療補短 , 最終服務于價值醫療的宏偉目標 。
技術扎根真實場景 , 驅動價值醫療普惠未來
微醫醫療大模型之所以能在權威評測中展現硬核實力 , 根源在于其“生于場景、長于場景”的發展路徑 。
與實驗室環境下的訓練不同 , 微醫醫療大模型的訓練與優化始終與線下醫療機構的真實業務流程緊密耦合 , 確保了技術發展不偏離臨床需求與醫療規范的主航道 。
目前 , 該模型的能力已全面賦能微醫人工智能醫院的各項服務 。 大模型能力通過AI醫生、AI藥師、AI健管、AI智控和微小醫等五大智能體 , 已在AI健共體中規模化應用 , 實現了從技術能力到商業價值的閉環轉化 。
不僅如此 , 在真實業務場景的協同下 , 微醫已形成能夠增強訓練和自我強化的數據飛輪效應 , 在療效評估、經濟性評估等反饋中不斷優化AI醫療能力 , 最終達到提質增效的效果 。
“此次通過MedBench 4.0的嚴格檢驗 , 不僅是對微醫醫療AI技術路線的肯定 , 更為我們繼續深化應用注入了堅定信心 。 ”微醫人工智能研究院首席科學家徐紅霞介紹 , 微醫將繼續以通過權威驗證的醫療大模型為核心驅動 , 聯合生態伙伴 , 在更廣泛的醫療人工智能應用領域持續深耕 。 以安全、可靠、專業的AI技術為支撐 , 構建一個真正智能化、普惠化的醫療健康新生態 , 讓優質醫療資源觸手可及 , 為健康中國建設貢獻堅實的科技力量 。 (心月)
推薦閱讀













- 大模型中標TOP10里的黑馬:中關村科金的應用攻堅之道
- 2026年,大模型訓練的下半場屬于「強化學習云」
- 新研究讓大模型學會主動追問,人機協作效果大幅提升
- 螞蟻再把醫療AI卷出新高度!螞蟻·安診兒醫療大模型開源即SOTA
- 智能廚電邁入大模型時代,中國廚電想從“學生”變“老師”|CES2026觀察
- 讓兩個大模型在線吵架,跑通全網95%科研代碼|深勢Deploy-Master
- 大模型「愛你在心口難開」?深度隱藏認知讓推理更可靠
- 醫療領域DeepSeek時刻:螞蟻 · 安診兒醫療大模型開源,登頂權威榜單
- 2.9億大模型大單!訊飛聯合中標
- Questel《2025生成式AI專利全景報告》:百度大模型專利申請量全球第一