
文章圖片
文章圖片

隨著人工智能在代碼以及圖片生成方面日益成熟 , 越來越多的研究人員也開始關注 AI 模型在游戲領域中的表現 。 實際上 , 游戲在 AI 的發展早期就已經是一個重要的研究方向 , 許多前期研究聚焦在 Atari , 星際爭霸 , Dota 等熱門游戲 , 并成功訓練出了表現超越人類玩家的專用模型 。 然而 , 這類模型通常只能在單一游戲環境中運行 , 缺乏跨游戲的泛化能力 。
另一方面 , 雖然 ChatGPT 和 Gemini 這類模型通用模型在眾多任務上已經展現出了卓越的能力 , 它們卻難以在游戲環境中取得好的表現 , 即便是很簡單的射擊游戲 。
為了解決這一問題 , 來自 Player2 的研究員們提出了 Pixel2Play(P2P)模型 , 該模型以游戲畫面和文本指令作為輸入 , 直接輸出對應的鍵盤與鼠標操作信號 。 在消費級顯卡 RTX 5090 上 , P2P 可以實現超過 20Hz 的端到端推理速度 , 從而能夠真正像人類一樣和游戲進行實時交互 。 P2P 作為通用游戲基座模型 , 在超過 40 款游戲、總計 8300 + 小時的游戲數據上進行了訓練 , 并能夠以零樣本(zero-shot)的方式直接玩 Roblox 和 Steam 平臺上的多款游戲 。
為了促進領域的發展 , Open-P2P 團隊在沒有使用許可限制的情況下開源了全部的訓練與推理代碼 , 并公開了所有的訓練數據集 。
接下來請看 P2P 模型的人機對戰:(在 Roblox Rivals 游戲中)
- 論文題目:Scaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing
- 項目主頁:https://elefant-ai.github.io/open-p2p/
- 論文代碼:https://github.com/elefant-ai/open-p2p
- 論文數據:https://huggingface.co/datasets/elefantai/p2p-full-data
訓練游戲 AI 模型需要高質量的游戲畫面、文本指令以及對應的操作數據 。 與海量公開的圖文數據不同 , 這類 “畫面 - 操作” 數據在互聯網上很少見 。 盡管已有通過游戲視頻反推動作的開源數據集 , 但開源的大規模高質量人工標注操作數據卻還是空缺 。 為了彌補這一空缺 , Open-P2P 項目開源了全部的訓練數據集 。
如圖所示 , P2P 所用的訓練數據同時包括游戲圖像畫面與對應的文本指令 , 并提供了精確的鍵盤鼠標操作標注
模型設計
為了保證模型可以做到快速的推理速度 , P2P 選擇了輕量級模型框架并從零開始訓練 。
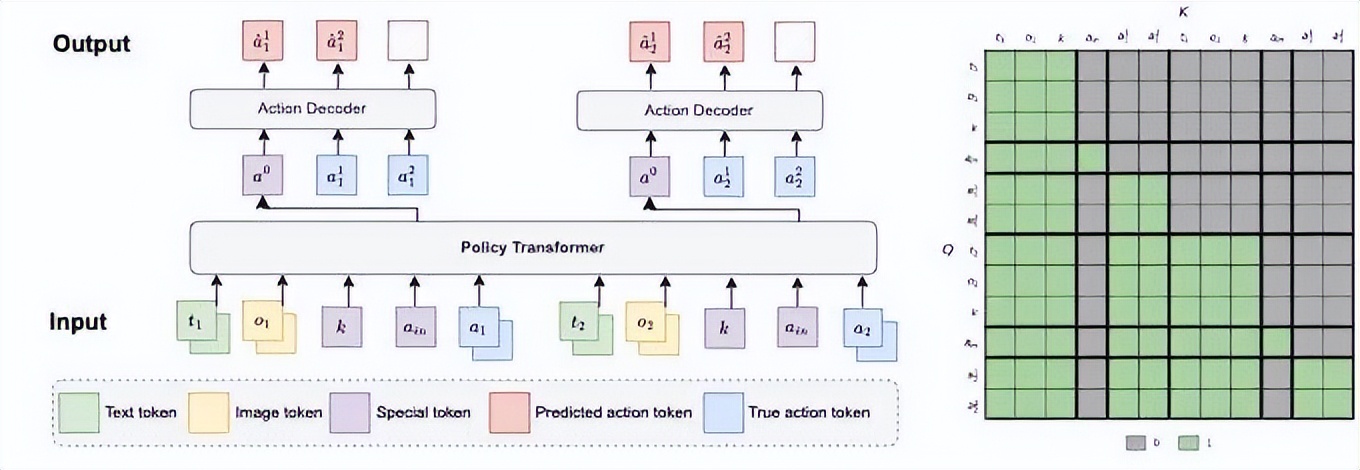
模型主體由一個解碼器 Transformer 構成(左圖所示) , 并額外接入一個輕量化的 action-decoder 來生成最終的操作信號 。 該結構使得模型在推理時只需要對主體模型進行一次前向計算 , 即可生成 action-decoder 所需的表征信號 , 從而使得整體推理速度提升 5 倍 。
為了實現跨游戲通用性 , P2P 采用了自回歸的離散 token 序列作為操作輸出空間 。 具體來說 , 每個操作由 8 個 token 表示:4 個對應鍵盤按鍵 , 2 個對應鼠標在水平與垂直方向上的離散位移 , 最后兩個對應鼠標按鍵 。 這樣的設計可以涵蓋絕大部分游戲的操作需求 。
在輸入方面 , 除了當前幀圖像與文本指令 token 外 , P2P 還會輸入真實操作 token , 這使得模型能夠根據歷史操作來做決策 , 從而更貼近人類玩家的操作習慣 。 為了保證模型的因果關系 , 訓練時使用了特殊的掩碼機制(右圖所示) , 以確保模型在預測時僅能看見歷史真實操作 。
模型評估
P2P 共訓練了四個不同規模的模型 , 參數量分別為 150M , 300M , 600M 和 1.2B 。 在實測中 , 150M 模型可以達到 80Hz 的端到端推理速度 , 而最大的 1.2B 模型也能達到 40Hz , 完全滿足與游戲環境實時交互的需求 。
模型評估的標準主要是人工評估 , 評估環境選取自四款游戲
- Steam 平臺上的 Quake , DOOM
- Roblox 平臺上的 Hypershot , Be a Shark
在 DOOM 和 Quake 中 , 每個官卡設置了四個不同的起始位置(Roblox 游戲因聯網機制無法固定起點) , 模型需從指定起點操作至下一個目標點 。
人工評估采取了兩兩比較的方式:將 1.2B 模型生成的游戲錄像與另外三個相對較小的模型錄像進行人工比對 。 結果顯示 , 1.2B 模型分別以 80% , 83% 與 75% 的偏好度優于 150M , 300M 和 600M 模型 。 下方視頻展示了對比片段:
指令遵循評估
研究還測試了 P2P 模型理解并執行文本指令的能力 。 評估環境選擇了 Quake 的一個迷宮關卡 , 該關卡要求玩家依次點亮三個紅色按鈕才能開門 。
這個任務對于僅憑借視覺信息的模型來說很有挑戰 , 因為 “按下按鈕” 和 “不按按鈕” 在行動軌跡上幾乎沒有區別 。 所以 , 未接受指令的模型通過率只有 20% 。 而當模型接收到 “按下紅色按鈕” 的文本指令后 , 模型的通過率可大幅提高到 80% , 顯示出了優秀的文本指令理解和執行能力 。
下方視頻對比了 1.2B 模型在有指令(左)和無指令(右)的情況下各運行 5 次的表現 。
因果混淆分析
因果混淆是行為克隆中常見的難題 , 在高頻的交互環境中尤其突出 。 例如 , 一個簡單的策略就是直接復制上一幀的操作 , 這種模型在訓練時 , 但在真實環境測試時表現就會很差 。
論文對此進行了系統的研究 , 發現擴大模型的規模與增加訓練模型的數據量能夠有效提升模型對因果關系的理解能力 , 使其不再依賴著淚虛假關聯 , 從而學到更好的操作策略 。
如圖所示 , 隨著訓練數據增多與模型參數量增加 , P2P 模型在因果推斷評估中的表現呈上升趨勢 。
關于作者
本文第一作者岳煜光現任初創公司 Player2 研究員 , 負責游戲模型的開發和研究 。 在加入 Player2 之前 , 他曾先后在 Amazon 和 Twitter 擔任研究人員 , 致力于語言模型與推薦系統的相關研究 。
岳煜光博士畢業于德州大學奧斯汀分校(UT-Austin) , 師從周明遠教授 , 研究方向是強化學習以及貝葉斯統計;此前他于加州大學洛杉磯分校(UCLA)取得碩士學位 , 本科畢業于復旦大學數學系 。
【開源8300小時標注數據,新一代實時通用游戲AI Pixel2Play發布】
推薦閱讀











- 國產芯片訓練的多模態SOTA模型開源,昇騰+昇思做對了什么?
- 智譜聯手華為開源新模型登頂Hugging Face,國產芯片全流程訓練實現突破
- 不用額外緩存!英偉達開源記憶壓縮方案,128K上下文提速2.7倍
- 國產Nano Banana開源!用華為AI芯片訓練,1張圖只要1毛錢
- 百川智能宣布開源全球最強醫療大模型Baichuan-M3,能力超GPT-5.2
- 剛剛,梁文鋒署名開源「記憶」模塊,DeepSeek V4更細節了
- 具身智能DeepSeek時刻!千尋智能模型開源即登頂全球榜單
- “明牌”對局,自變量開源模型超越pi0
- 螞蟻再把醫療AI卷出新高度!螞蟻·安診兒醫療大模型開源即SOTA
- 醫療領域DeepSeek時刻:螞蟻 · 安診兒醫療大模型開源,登頂權威榜單